























Pasikalbėkite su bet kuo, kas dirba dirbtinio intelekto, analizės ar duomenų mokslo srityje, ir jie jums pasakys, kad sintetiniai duomenys yra ateitis. Tačiau paklauskite jų, ką jie reiškia „sintetiniais duomenimis“, ir gausite labai skirtingus atsakymus. Taip yra todėl, kad sintetiniai duomenys nėra tik vienas dalykas – tai plati kategorija su daugybe naudojimo atvejų ir apibrėžimų. Ir tas dviprasmiškumas pokalbius painioja.
Taigi, pašalinkime triukšmą. Iš esmės sintetiniai duomenys veikia dviem pagrindiniais aspektais. Pirmasis yra spektras nuo trūkstamų duomenų užpildymo esamame duomenų rinkinyje iki visiškai naujų duomenų rinkinių generavimo. Antrasis išskiria intervencijas neapdorotų duomenų lygmeniu ir intervencijas įžvalgų ar rezultatų lygmeniu.
Įsivaizduokite šiuos matmenis kaip diagramos ašis. Taip sukuriami keturi kvadrantai, kurių kiekvienas atspindi skirtingą sintetinių duomenų tipą: duomenų priskyrimą, naudotojo kūrimą, įžvalgų modeliavimą ir pagamintus rezultatus . Kiekvienas iš jų atlieka atskirą funkciją, o jei dirbate su bet kokiais duomenimis, turite žinoti skirtumą.

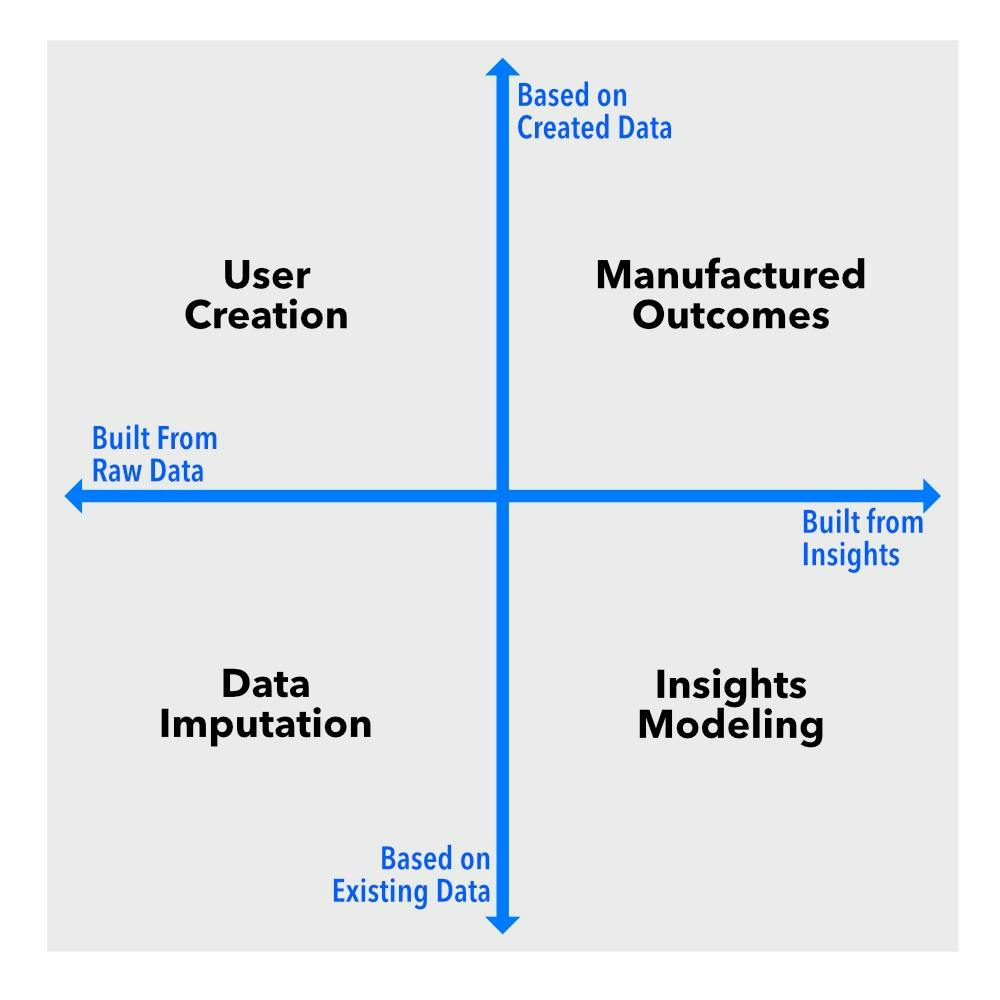
Duomenų priskyrimas: užpildykite tuščius laukus
Nors kai kurie gali ginčytis, kad duomenų priskyrimas nėra iš tikrųjų sintetiniai duomenys, šiuolaikiniai priskyrimo metodai išsivystė daugiau nei paprastas vidurkis arba mediana. Šiandien pažangus priskyrimas naudoja mašininį mokymąsi ir generuojamuosius AI modelius, todėl sukurtos vertės yra sudėtingesnės ir labiau atitinka kontekstą nei bet kada anksčiau.
Duomenų priskyrimas yra trūkstamų duomenų ir neapdorotų duomenų intervencijos sankirtoje. Tai reiškia, kad dirbame su esamais duomenų rinkiniais, kuriuose yra spragų, ir mūsų tikslas yra sukurti patikimas vertes, kad jas užpildytume. Skirtingai nuo kitų tipų sintetinių duomenų, imputacija nėra skirta visiškai naujos informacijos kūrimui, o tai, kad nepilnus duomenis būtų lengviau naudoti.
Pavyzdys: rinkos tyrimų įmonė, atliekanti žiniasklaidos efektyvumo tyrimus, gali turėti spragų auditorijos atsakymų duomenims dėl trūkstamų apklausos atsakymų. Užuot atmetę neišsamius duomenų rinkinius, imputacijos metodai, tokie kaip statistinis modeliavimas ar mašininis mokymasis, gali generuoti realistiškus įvertinimus, užtikrinant, kad analitikai vis tiek galėtų gauti reikšmingų įžvalgų iš duomenų.
Vartotojo kūrimas: netikri žmonės, tikros įžvalgos
Vartotojo kūrimas yra tarp naujų duomenų generavimo ir neapdorotų duomenų intervencijos . Užuot modifikavus esamus duomenis, šis metodas sukuria visiškai naujus vartotojų profilius ir elgseną. Tai ypač naudinga, kai nepasiekiami tikri naudotojo duomenys, jie yra jautrūs arba juos reikia dirbtinai pakeisti.
Vartotojų kūrimas yra žaidimų keitiklis, skirtas produktų testavimui, saugumo gerinimui ir AI modelių mokymui.
Pavyzdys: srautinio perdavimo paslauga gali sukurti sintetinius vartotojo profilius, kad išbandytų savo rekomendacijų variklį, neatskleisdama tikrų klientų duomenų. Kibernetinio saugumo įmonės daro tą patį, kad imituotų atakų scenarijus ir mokytų sukčiavimo aptikimo sistemas.
Įžvalgų modeliavimas: modeliai be privatumo rizikos
Įžvalgų modeliavimas veikia esamų duomenų ir intervencijos įžvalgų lygiu sankirtoje. Užuot manipuliavęs neapdorotų duomenų taškais, jis sukuria duomenų rinkinius, kurie išsaugo statistines realaus pasaulio duomenų savybes, neatskleidžiant faktinių įrašų. Dėl to jis idealiai tinka privatumui jautrioms programoms.
Įžvalgų modeliavimas taip pat leidžia tyrėjams išplėsti įžvalgas iš jau esamų duomenų rinkinių, ypač kai didelio masto duomenų rinkimas yra nepraktiškas. Tai įprasta rinkodaros tyrimuose, kur duomenų rinkimas gali būti sudėtingas ir brangus. Tačiau šis metodas reikalauja tvirto realaus pasaulio mokymo duomenų pagrindo.
Pavyzdys: rinkos tyrimų įmonė, atliekanti kopijų testavimą, gali naudoti įžvalgų modeliavimą, kad padidintų savo normatyvinę duomenų bazę. Užuot pasikliaudama vien surinktais apklausos atsakymais, įmonė gali sukurti sintetinius įžvalgų modelius, kurie ekstrapoliuoja modelius iš esamų norminių duomenų. Tai leidžia prekių ženklams išbandyti kūrybinį našumą, palyginti su platesniu, labiau nuspėjamu duomenų rinkiniu, nuolat nerenkant naujų apklausos atsakymų.
Gamybos rezultatai: kai duomenų dar nėra
Gaminami rezultatai yra tiek naujų duomenų generavimo , tiek įžvalgų lygio intervencijos pabaigoje. Šis metodas apima visiškai naujų duomenų rinkinių generavimą nuo nulio, kad būtų galima imituoti aplinkas ar scenarijus, kurie dar neegzistuoja, bet yra būtini AI mokymui, modeliavimui ir modeliavimui.
Kartais jums reikalingų duomenų tiesiog nėra arba jie yra per brangūs arba pavojingi, kad juos būtų galima rinkti realiame pasaulyje. Čia atsiranda gamybos rezultatai. Šis procesas generuoja visiškai naujus duomenų rinkinius, dažnai lavinančias AI sistemas aplinkoje, kurią sunku pakartoti.
Pavyzdys: savarankiškai vairuojančių automobilių įmonės sukuria sintetinius kelių scenarijus, pavyzdžiui, staiga vaikščiojantis pėsčiasis, kad mokytų savo dirbtinį intelektą retų, bet kritinių situacijų, kurios gali nepasirodyti realiame vairavimo filmuotoje medžiagoje.
Sintetinių duomenų rizika ir svarstymai
Nors sintetiniai duomenys yra galingi sprendimai, jie nekelia pavojaus. Kiekvienas sintetinių duomenų tipas turi savo iššūkių, kurie gali turėti įtakos duomenų kokybei, patikimumui ir etiškam naudojimui. Štai keletas pagrindinių rūpesčių, kuriuos reikia nepamiršti:
- Poslinkio plitimas: jei pagrindiniai duomenys, naudojami imputacijai, įžvalgų modeliavimui arba pagamintiems rezultatams, yra paklaidų, šie paklaidai gali būti sustiprinti ar net sustiprinti.
- Trūksta reprezentatyvumo realiame pasaulyje: naudotojų kūrimas ir duomenų kūrimas gali generuoti duomenis, kurie atrodo realistiški, tačiau neatspindi tikrojo vartotojo elgesio ar rinkos sąlygų niuansų.
- Per didelis pritaikymas ir klaidingas pasitikėjimas: netinkamai pritaikytas įžvalgų modeliavimas gali sukurti duomenis, kurie per daug sutampa su mokymo rinkiniu, todėl daromos klaidinančios išvados.
- Reguliavimo ir etikos problemos: Privatumo įstatymai, pvz., BDAR ir CCPA, vis dar taikomi sintetiniams duomenims, jei juos galima pakeisti, kad būtų galima identifikuoti tikrus asmenis.
Pagrindiniai klausimai, kuriuos reikia užduoti vertinant sintetinius duomenis
Norėdami užtikrinti, kad sintetiniai duomenys atitiktų kokybės standartus, apsvarstykite šiuos klausimus:
- Kas yra pirminių duomenų šaltinis? Sintetinių duomenų pagrindo supratimas padeda įvertinti galimus šališkumus ir apribojimus.
- Kaip buvo generuojami sintetiniai duomenys? Įvairūs metodai – mašininis mokymasis, statistiniai modeliai ar taisyklėmis pagrįstos sistemos – turi įtakos sintetinių duomenų patikimumui.
- Ar sintetiniai duomenys išlaiko statistinį realaus pasaulio duomenų vientisumą? Užtikrinkite, kad sugeneruoti duomenys veiktų panašiai kaip tikrieji duomenys, tik jų nedubliuodami.
- Ar sintetiniai duomenys gali būti audituojami arba patvirtinami? Patikimiems sintetiniams duomenims turi būti taikomi patvirtinimo mechanizmai.
- Ar jis atitinka reguliavimo ir etikos gaires? Tai, kad duomenys yra sintetiniai, nereiškia, kad jiems netaikomi privatumo reglamentai.
- Ar yra procesas, skirtas atnaujinti pagrindinius duomenų modelius? Sintetiniai duomenys yra tokie pat geri, kaip ir realaus pasaulio duomenys, kuriais jie pagrįsti. Užtikrinant nuolatinio pagrindinių duomenų rinkinio atnaujinimo procesą, modeliai nepasensta ir nesutampa su dabartinėmis tendencijomis.
Apvyniojimas
Sintetiniai duomenys yra plati sąvoka, o jei dirbate dirbtinio intelekto, analizės ar bet kurioje duomenimis pagrįstoje sferoje, turite aiškiai suprasti, su kuo susiduriate. Ar pildote trūkstamus duomenis (įskaitymas), kuriate bandomuosius vartotojus (vartotojo kūrimas), kuriate anoniminius modelius (įžvalgų modeliavimas) ar kuriate visiškai naujus duomenų rinkinius nuo nulio (pagaminti rezultatai)?
Kiekvienas iš jų atlieka skirtingą vaidmenį, kaip naudojame ir saugome duomenis, o jų supratimas yra labai svarbus norint priimti pagrįstus sprendimus sparčiai besivystančiame AI ir duomenų mokslo pasaulyje. Taigi kitą kartą, kai kas nors išmeta terminą „sintetiniai duomenys“, paklauskite jų: kokios rūšies?




