























एआई, एनालिटिक्स, वा डेटा विज्ञानमा जो कोहीसँग कुरा गर्नुहोस्, र तिनीहरूले तपाईंलाई सिंथेटिक डेटा भविष्य हो भनेर भन्नेछन्। तर तिनीहरूलाई "सिंथेटिक डेटा" भन्नाले के बुझिन्छ भनेर सोध्नुहोस्, र तपाईंले एकदमै फरक जवाफहरू पाउनुहुनेछ। किनभने सिंथेटिक डेटा केवल एउटा चीज होइन - यो धेरै प्रयोगका केसहरू र परिभाषाहरू भएको फराकिलो वर्ग हो। र त्यो अस्पष्टताले कुराकानीहरूलाई भ्रमित बनाउँछ।
त्यसोभए, आवाजलाई काटौं। यसको मूलमा, सिंथेटिक डेटा दुई प्रमुख आयामहरूमा काम गर्दछ। पहिलो भनेको अवस्थित डेटासेटमा हराएको डेटा भर्ने देखि पूर्ण रूपमा नयाँ डेटासेटहरू उत्पन्न गर्ने सम्मको स्पेक्ट्रम हो। दोस्रोले कच्चा डेटा स्तरमा हस्तक्षेपहरू र अन्तर्दृष्टि वा परिणाम स्तरमा हस्तक्षेपहरू बीच भिन्नता छुट्याउँछ।
यी आयामहरूलाई चार्टमा अक्षको रूपमा कल्पना गर्नुहोस्। यसले चार चतुर्थांशहरू सिर्जना गर्दछ, प्रत्येकले फरक प्रकारको सिंथेटिक डेटा प्रतिनिधित्व गर्दछ: डेटा अभियोग, प्रयोगकर्ता सिर्जना, अन्तर्दृष्टि मोडेलिङ, र निर्मित परिणामहरू । प्रत्येकले एक फरक प्रकार्य कार्य गर्दछ, र यदि तपाईं कुनै पनि क्षमतामा डेटासँग काम गर्दै हुनुहुन्छ भने, तपाईंले भिन्नता जान्न आवश्यक छ।

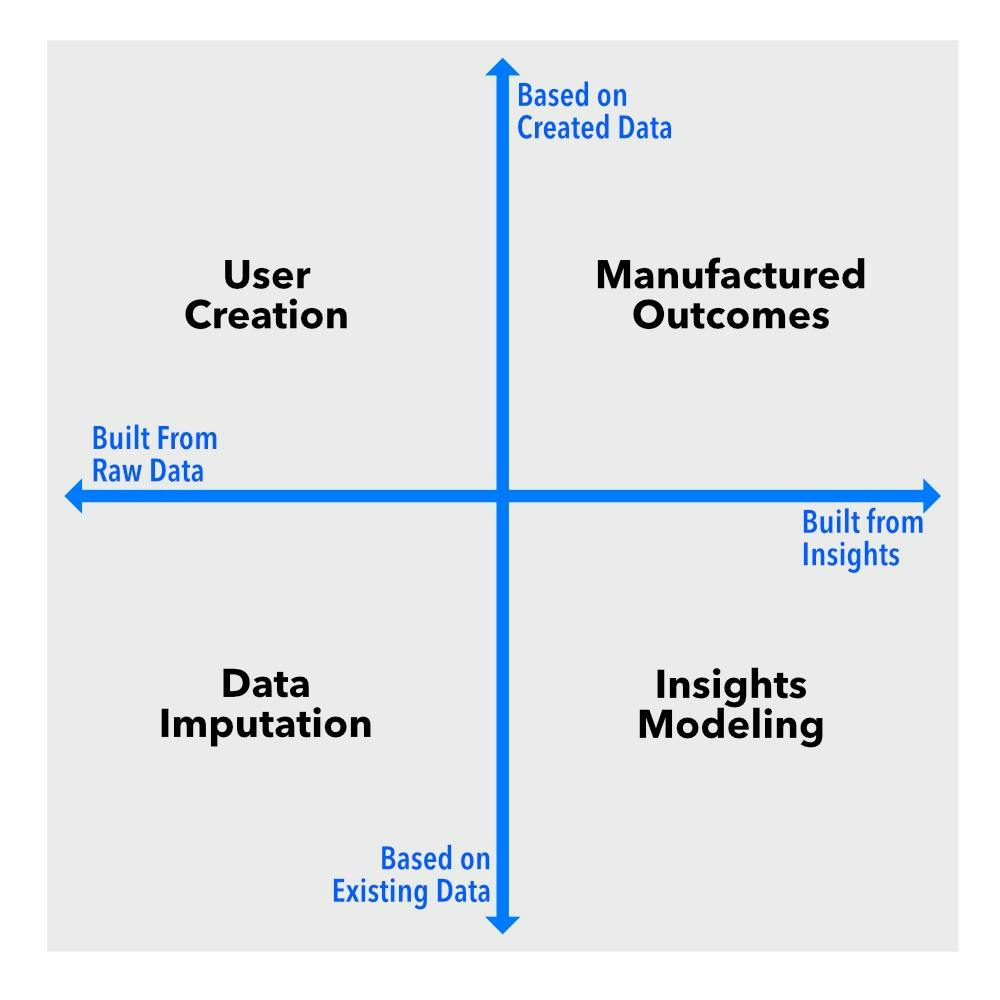
डेटा अभियोजन: खाली ठाउँहरू भर्ने
कतिपयले डेटा इन्पुटेशन वास्तवमा सिंथेटिक डेटा होइन भन्ने तर्क गर्न सक्छन्, आधुनिक इन्पुटेशन प्रविधिहरू साधारण माध्य वा मध्य प्रतिस्थापनभन्दा बाहिर विकसित भएका छन्। आज, उन्नत इन्पुटेशनले मेसिन लर्निङ र जेनेरेटिभ एआई मोडेलहरूलाई प्रयोग गर्दछ, जसले गर्दा उत्पन्न मानहरू पहिलेभन्दा अझ परिष्कृत र सन्दर्भिक रूपमा सान्दर्भिक हुन्छन्।
डेटा अभियोग हराएको डेटा र कच्चा डेटा हस्तक्षेपको प्रतिच्छेदनमा बस्छ। यसको मतलब हामी अवस्थित डेटासेटहरूसँग काम गरिरहेका छौं जसमा खाली ठाउँहरू छन्, र हाम्रो लक्ष्य तिनीहरूलाई पूरा गर्न सम्भव मानहरू उत्पन्न गर्नु हो। अन्य प्रकारका सिंथेटिक डेटा भन्दा फरक, अभियोग पूर्ण रूपमा नयाँ जानकारी सिर्जना गर्ने बारे होइन - यो अपूर्ण डेटालाई अझ उपयोगी बनाउने बारे हो।
उदाहरण: मिडिया प्रभावकारिता अध्ययन गर्ने बजार अनुसन्धान फर्मले सर्वेक्षण प्रतिक्रियाहरू हराएको कारणले गर्दा यसको दर्शक प्रतिक्रिया डेटामा अन्तर हुन सक्छ। अपूर्ण डेटासेटहरू खारेज गर्नुको सट्टा, तथ्याङ्कीय मोडेलिङ वा मेसिन लर्निङ जस्ता आरोप लगाउने प्रविधिहरूले यथार्थपरक अनुमानहरू उत्पन्न गर्न सक्छन्, जसले गर्दा विश्लेषकहरूले अझै पनि डेटाबाट अर्थपूर्ण अन्तर्दृष्टिहरू प्राप्त गर्न सक्छन्।
प्रयोगकर्ता सिर्जना: नक्कली मानिसहरू, वास्तविक अन्तर्दृष्टिहरू
प्रयोगकर्ता सिर्जना नयाँ डेटा उत्पादन र कच्चा डेटा हस्तक्षेप बीच निहित छ। अवस्थित डेटा परिमार्जन गर्नुको सट्टा, यो दृष्टिकोणले पूर्ण रूपमा नयाँ प्रयोगकर्ता प्रोफाइल र व्यवहारहरू निर्माण गर्दछ। यो विशेष गरी उपयोगी हुन्छ जब वास्तविक प्रयोगकर्ता डेटा उपलब्ध हुँदैन, संवेदनशील हुन्छ, वा कृत्रिम रूपमा मापन गर्न आवश्यक हुन्छ।
प्रयोगकर्ता सिर्जना उत्पादनहरूको परीक्षण, सुरक्षा सुधार, र एआई मोडेलहरूलाई तालिम दिनको लागि एक खेल-परिवर्तक हो।
उदाहरण: स्ट्रिमिङ सेवाले वास्तविक ग्राहक डेटा उजागर नगरी आफ्नो सिफारिस इन्जिन परीक्षण गर्न कृत्रिम प्रयोगकर्ता प्रोफाइलहरू सिर्जना गर्न सक्छ। साइबर सुरक्षा फर्महरूले आक्रमण परिदृश्यहरू अनुकरण गर्न र धोखाधडी पत्ता लगाउने प्रणालीहरूलाई तालिम दिन पनि त्यस्तै गर्छन्।
अन्तर्दृष्टि मोडलिङ: गोपनीयता जोखिम बिना ढाँचाहरू
अन्तर्दृष्टि मोडेलिङले अवस्थित डेटा र अन्तर्दृष्टि स्तरमा हस्तक्षेपको प्रतिच्छेदनमा काम गर्छ। कच्चा डेटा बिन्दुहरूलाई हेरफेर गर्नुको सट्टा, यसले डेटासेटहरू सिर्जना गर्दछ जसले वास्तविक रेकर्डहरू उजागर नगरी वास्तविक-विश्व डेटाको सांख्यिकीय गुणहरू सुरक्षित गर्दछ। यसले यसलाई गोपनीयता-संवेदनशील अनुप्रयोगहरूको लागि आदर्श बनाउँछ।
अन्तर्दृष्टि मोडेलिङले अनुसन्धानकर्ताहरूलाई पहिले नै अवस्थित डेटासेटहरूबाट अन्तर्दृष्टिहरू मापन गर्न अनुमति दिन्छ, विशेष गरी जब ठूलो मात्रामा डेटा सङ्कलन गर्नु अव्यावहारिक हुन्छ। यो मार्केटिङ अनुसन्धानमा सामान्य छ, जहाँ डेटा सङ्कलन बोझिलो र महँगो हुन सक्छ। यद्यपि, यो दृष्टिकोणलाई वास्तविक-विश्व प्रशिक्षण डेटाको बलियो जग चाहिन्छ।
उदाहरण: प्रतिलिपि परीक्षण गर्ने बजार अनुसन्धान फर्मले आफ्नो मानक डेटाबेस मापन गर्न अन्तर्दृष्टि मोडेलिङ प्रयोग गर्न सक्छ। सङ्कलन गरिएका सर्वेक्षण प्रतिक्रियाहरूमा मात्र भर पर्नुको सट्टा, फर्मले अवस्थित मानक डेटाबाट ढाँचाहरू एक्स्ट्रापोलेट गर्ने सिंथेटिक अन्तर्दृष्टि मोडेलहरू उत्पन्न गर्न सक्छ। यसले ब्रान्डहरूलाई निरन्तर नयाँ सर्वेक्षण प्रतिक्रियाहरू सङ्कलन नगरी फराकिलो, थप भविष्यवाणी गर्ने डेटासेट विरुद्ध रचनात्मक प्रदर्शन परीक्षण गर्न अनुमति दिन्छ।
निर्मित परिणामहरू: जब डेटा अझै अवस्थित छैन
निर्मित परिणामहरू नयाँ डेटा उत्पादन र अन्तर्दृष्टि-स्तर हस्तक्षेप दुवैको चरम अन्त्यमा बस्छन्। यो दृष्टिकोणमा वातावरण वा परिदृश्यहरूको नक्कल गर्न स्क्र्याचबाट पूर्ण रूपमा नयाँ डेटासेटहरू उत्पन्न गर्ने समावेश छ जुन अझै अवस्थित छैन तर एआई प्रशिक्षण, मोडेलिङ र सिमुलेशनहरूको लागि आवश्यक छ।
कहिलेकाहीँ, तपाईंलाई आवश्यक पर्ने डेटा अवस्थित हुँदैन—वा वास्तविक संसारमा सङ्कलन गर्न धेरै महँगो वा खतरनाक हुन्छ। त्यहीँबाट निर्मित परिणामहरू आउँछन्। यो प्रक्रियाले पूर्ण रूपमा नयाँ डेटासेटहरू उत्पन्न गर्दछ, प्रायः प्रतिकृति बनाउन गाह्रो वातावरणमा एआई प्रणालीहरूलाई तालिम दिन।
उदाहरण: स्व-ड्राइभिङ कार कम्पनीहरूले वास्तविक-विश्व ड्राइभिङ फुटेजमा प्रायः नदेखिने दुर्लभ तर गम्भीर परिस्थितिहरूमा आफ्नो एआईलाई तालिम दिनको लागि कृत्रिम सडक परिदृश्यहरू उत्पन्न गर्छन् - जस्तै पैदल यात्री अचानक जयवाक गर्दै।
सिंथेटिक डेटाको जोखिम र विचारहरू
सिंथेटिक डेटाले शक्तिशाली समाधान प्रदान गर्छ, तर यो जोखिमरहित भने छैन। प्रत्येक प्रकारको सिंथेटिक डेटाको आफ्नै चुनौतीहरू हुन्छन् जसले डेटाको गुणस्तर, विश्वसनीयता र नैतिक प्रयोगलाई असर गर्न सक्छ। यहाँ ध्यानमा राख्नु पर्ने केही प्रमुख चिन्ताहरू छन्:
- पूर्वाग्रह प्रचार: यदि आरोप, अन्तर्दृष्टि मोडेलिङ, वा निर्मित परिणामहरूको लागि प्रयोग गरिएको अन्तर्निहित डेटामा पूर्वाग्रह छ भने, ती पूर्वाग्रहहरूलाई सुदृढ पार्न वा विस्तार गर्न सकिन्छ।
- वास्तविक-विश्व प्रतिनिधित्वको अभाव: प्रयोगकर्ता सिर्जना र डेटा निर्माणले वास्तविक लाग्ने डेटा उत्पन्न गर्न सक्छ तर वास्तविक प्रयोगकर्ता व्यवहार वा बजार अवस्थाको सूक्ष्मताहरू कब्जा गर्न असफल हुन्छ।
- अत्यधिक फिटिंग र गलत आत्मविश्वास: अन्तर्दृष्टि मोडेलिङ, जब अनुचित रूपमा लागू गरिन्छ, तालिम सेटसँग धेरै नजिकको मिल्दो डेटा सिर्जना गर्न सक्छ, जसले गर्दा भ्रामक निष्कर्ष निम्त्याउँछ।
- नियामक र नैतिक सरोकारहरू: GDPR र CCPA जस्ता गोपनीयता कानूनहरू अझै पनि कृत्रिम डेटामा लागू हुन्छन् यदि यसलाई वास्तविक व्यक्तिहरू पहिचान गर्न उल्टो-इन्जिनियर गर्न सकिन्छ।
सिंथेटिक डेटाको मूल्याङ्कन गर्दा सोध्नुपर्ने मुख्य प्रश्नहरू
सिंथेटिक डेटाले गुणस्तर मापदण्डहरू पूरा गर्छ भनी सुनिश्चित गर्न, यी प्रश्नहरू विचार गर्नुहोस्:
- मूल डेटाको स्रोत के हो? सिंथेटिक डेटाको आधार बुझ्नाले सम्भावित पूर्वाग्रह र सीमितताहरूको मूल्याङ्कन गर्न मद्दत गर्छ।
- सिंथेटिक डेटा कसरी उत्पन्न भयो? विभिन्न विधिहरू - मेसिन लर्निङ, तथ्याङ्कीय मोडेलहरू, वा नियम-आधारित प्रणालीहरू - ले सिंथेटिक डेटाको विश्वसनीयतालाई असर गर्छ।
- के सिंथेटिक डेटाले वास्तविक-विश्व डेटाको सांख्यिकीय अखण्डता कायम राख्छ? उत्पन्न डेटाले वास्तविक डेटा जस्तै व्यवहार गर्छ भनी सुनिश्चित गर्नुहोस्, केवल नक्कल नगरी।
- के सिंथेटिक डेटाको लेखा परीक्षण वा प्रमाणीकरण गर्न सकिन्छ? भरपर्दो सिंथेटिक डेटामा प्रमाणीकरण संयन्त्र हुनुपर्छ।
- के यसले नियामक र नैतिक दिशानिर्देशहरूको पालना गर्छ? डेटा कृत्रिम छ भन्दैमा यो गोपनीयता नियमहरूबाट मुक्त छ भन्ने होइन।
- के अन्तर्निहित डेटा मोडेलहरू अद्यावधिक गर्ने कुनै प्रक्रिया छ? सिंथेटिक डेटा वास्तविक-विश्व डेटा जत्तिकै राम्रो हुन्छ जुन यसमा आधारित छ। आधारभूत डेटासेटलाई निरन्तर अद्यावधिक गर्ने प्रक्रिया सुनिश्चित गर्नाले मोडेलहरूलाई पुरानो हुन र हालको प्रवृत्तिहरूसँग गलत तरिकाले मिल्नबाट रोक्छ।
यसलाई बेर्दै
सिंथेटिक डेटा एउटा व्यापक शब्द हो, र यदि तपाईं एआई, एनालिटिक्स, वा कुनै पनि डेटा-संचालित क्षेत्रमा काम गर्दै हुनुहुन्छ भने, तपाईं कस्तो प्रकारको व्यवहार गर्दै हुनुहुन्छ भन्ने कुरामा स्पष्ट हुन आवश्यक छ। के तपाईं हराएको डेटा (आरोप) भर्दै हुनुहुन्छ, परीक्षण प्रयोगकर्ताहरू सिर्जना गर्दै हुनुहुन्छ (प्रयोगकर्ता सिर्जना गर्दै हुनुहुन्छ), बेनामी ढाँचाहरू उत्पन्न गर्दै हुनुहुन्छ (अन्तरदृष्टि मोडेलिङ), वा स्क्र्याचबाट ब्रान्ड-नयाँ डेटासेटहरू निर्माण गर्दै हुनुहुन्छ (निर्मित परिणामहरू)?
यी प्रत्येकले डेटा कसरी प्रयोग र सुरक्षा गर्छौं भन्ने कुरामा फरक भूमिका खेल्छ, र एआई र डेटा विज्ञानको द्रुत रूपमा विकसित संसारमा सूचित निर्णयहरू लिनको लागि तिनीहरूलाई बुझ्नु महत्वपूर्ण छ। त्यसैले अर्को पटक कसैले "सिंथेटिक डेटा" शब्द प्रयोग गर्दा, तिनीहरूलाई सोध्नुहोस्: कुन प्रकारको?








