























Tal med alle inden for kunstig intelligens, analyse eller datavidenskab, og de vil fortælle dig, at syntetiske data er fremtiden. Men spørg dem, hvad de mener med "syntetiske data", og du vil få vildt forskellige svar. Det skyldes, at syntetiske data ikke kun er én ting – det er en bred kategori med flere use cases og definitioner. Og den tvetydighed gør samtaler forvirrende.
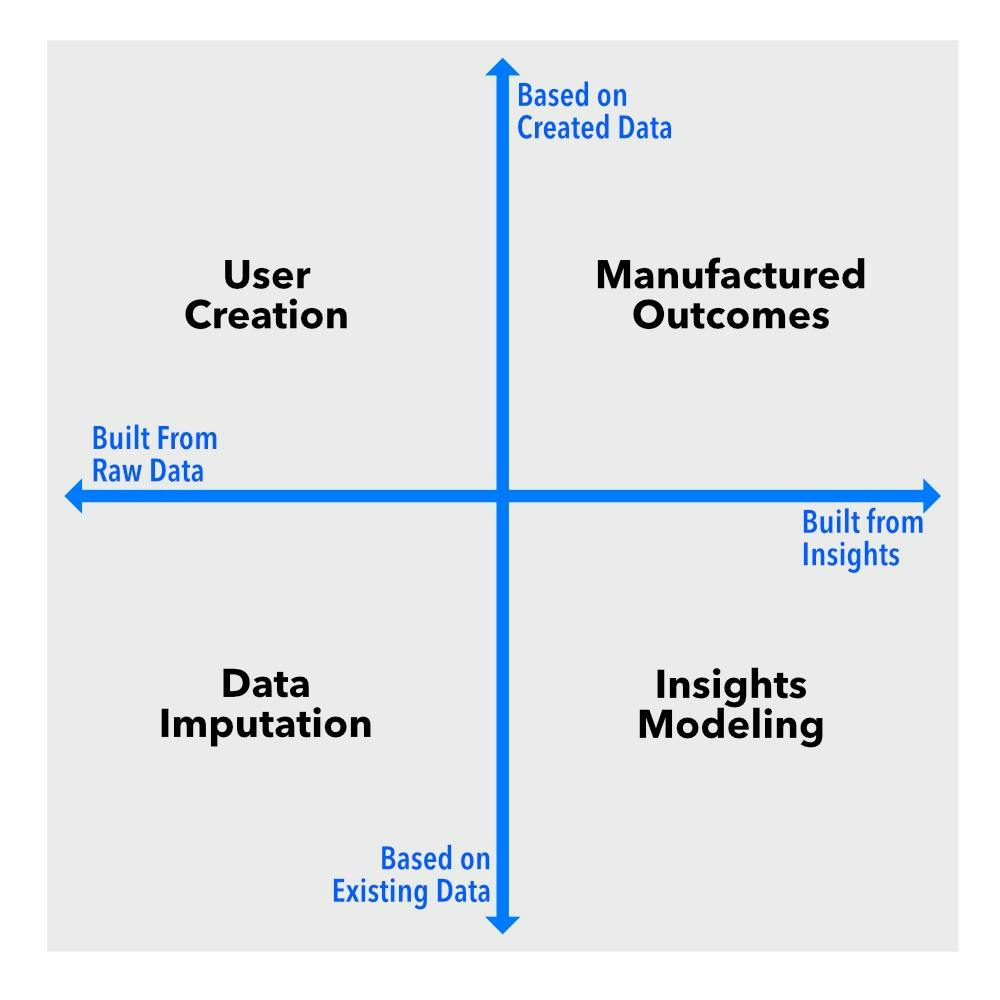
Så lad os skære igennem støjen. I sin kerne opererer syntetiske data langs to nøgledimensioner. Den første er et spektrum, der spænder fra at udfylde manglende data i et eksisterende datasæt til at generere helt nye datasæt. Den anden skelner mellem interventioner på rådataniveau versus interventioner på indsigts- eller resultatniveau.
Forestil dig disse dimensioner som akser på et diagram. Dette skaber fire kvadranter, der hver repræsenterer en anden type syntetiske data: dataimputering, brugeroprettelse, indsigtsmodellering og fremstillede resultater . Hver af dem har en særskilt funktion, og hvis du arbejder med data på nogen måde, skal du kende forskellen.

Dataimputation: Udfyldning af tomme felter
Mens nogle måske vil hævde, at dataimputering ikke er virkelig syntetiske data, har moderne imputationsteknikker udviklet sig ud over simpel middel- eller mediansubstitution. I dag udnytter avanceret imputation maskinlæring og generative AI-modeller, hvilket gør de genererede værdier mere sofistikerede og kontekstuelt relevante end nogensinde før.
Dataimputering er i skæringspunktet mellem manglende data og rådataintervention . Det betyder, at vi arbejder med eksisterende datasæt, der har huller, og vores mål er at generere plausible værdier for at fuldende dem. I modsætning til andre typer syntetiske data handler imputation ikke om at skabe helt ny information – det handler om at gøre ufuldstændige data mere anvendelige.
Eksempel: Et markedsundersøgelsesfirma, der udfører undersøgelser af medieeffektivitet, kan have huller i sine publikumssvardata på grund af manglende undersøgelsessvar. I stedet for at kassere ufuldstændige datasæt, kan imputationsteknikker – såsom statistisk modellering eller maskinlæring – generere realistiske estimater, hvilket sikrer, at analytikere stadig kan drage meningsfuld indsigt fra dataene.
Brugeroprettelse: Fake People, Real Insights
Brugerskabelse ligger mellem ny datagenerering og rådataintervention . I stedet for at ændre eksisterende data, fremstiller denne tilgang helt nye brugerprofiler og adfærd. Det er især nyttigt, når rigtige brugerdata ikke er tilgængelige, er følsomme eller skal skaleres kunstigt.
Brugeroprettelse er en game-changer til at teste produkter, forbedre sikkerheden og træne AI-modeller.
Eksempel: En streamingtjeneste kan oprette syntetiske brugerprofiler for at teste sin anbefalingsmotor uden at afsløre reelle kundedata. Cybersikkerhedsfirmaer gør det samme for at simulere angrebsscenarier og træne svindeldetektionssystemer.
Insights-modellering: Mønstre uden privatlivsrisici
Indsigtsmodellering opererer i skæringspunktet mellem eksisterende data og intervention på indsigtsniveau . I stedet for at manipulere rådatapunkter opretter den datasæt, der bevarer de statistiske egenskaber af data fra den virkelige verden uden at afsløre faktiske registreringer. Dette gør den ideel til privatlivsfølsomme applikationer.
Insights-modellering giver også forskere mulighed for at skalere indsigt fra allerede eksisterende datasæt, især når det er upraktisk at indsamle data i stor skala. Dette er almindeligt inden for markedsundersøgelser, hvor dataindsamling kan være besværligt og dyrt. Denne tilgang kræver dog et solidt fundament af træningsdata fra den virkelige verden.
Eksempel: Et markedsundersøgelsesfirma, der udfører kopitest, kan bruge indsigtsmodellering til at skalere sin normative database. I stedet for udelukkende at stole på indsamlede undersøgelsessvar, kan virksomheden generere syntetiske indsigtsmodeller, der ekstrapolerer mønstre fra eksisterende normative data. Dette giver brands mulighed for at teste kreativ ydeevne mod et bredere, mere forudsigelig datasæt uden løbende at indsamle nye undersøgelsessvar.
Fremstillede resultater: Når dataene ikke eksisterer endnu
Fremstillede resultater sidder i den yderste ende af både ny datagenerering og intervention på indsigtsniveau . Denne tilgang involverer generering af helt nye datasæt fra bunden for at simulere miljøer eller scenarier, der endnu ikke eksisterer, men som er afgørende for AI-træning, modellering og simuleringer.
Nogle gange eksisterer de data, du har brug for, simpelthen ikke – eller er for dyre eller farlige at indsamle i den virkelige verden. Det er her, Manufactured Outcomes kommer ind i billedet. Denne proces genererer helt nye datasæt, ofte for at træne AI-systemer i miljøer, der er svære at replikere.
Eksempel: Selvkørende bilfirmaer genererer syntetiske vejscenarier - som en fodgænger, der pludselig går i stykker - for at træne deres AI i sjældne, men kritiske situationer, som måske ikke optræder ofte i køreoptagelser fra den virkelige verden.
Risici og overvejelser ved syntetiske data
Selvom syntetiske data giver kraftfulde løsninger, er det ikke uden risici. Hver type syntetiske data har sine egne udfordringer, der kan påvirke datakvalitet, pålidelighed og etisk brug. Her er nogle vigtige bekymringer at huske på:
- Bias-udbredelse: Hvis de underliggende data, der bruges til imputation, indsigtsmodellering eller fremstillede resultater, indeholder bias, kan disse skævheder forstærkes eller endda forstærkes.
- Manglende repræsentativitet i den virkelige verden: Brugeroprettelse og datafremstilling kan generere data, der virker realistiske, men som ikke fanger nuancerne af faktisk brugeradfærd eller markedsforhold.
- Overtilpasning og falsk tillid: Indsigtsmodellering kan, når den anvendes forkert, skabe data, der stemmer for tæt med træningssættet, hvilket fører til vildledende konklusioner.
- Regulatoriske og etiske bekymringer: Privatlivslove som GDPR og CCPA gælder stadig for syntetiske data, hvis de kan omvendt udvikles til at identificere rigtige individer.
Nøglespørgsmål at stille ved evaluering af syntetiske data
Overvej disse spørgsmål for at sikre, at syntetiske data lever op til kvalitetsstandarder:
- Hvad er kilden til de originale data? At forstå grundlaget for syntetiske data hjælper med at vurdere potentielle skævheder og begrænsninger.
- Hvordan blev de syntetiske data genereret? Forskellige metoder - maskinlæring, statistiske modeller eller regelbaserede systemer - påvirker pålideligheden af syntetiske data.
- Bevarer de syntetiske data den statistiske integritet af data fra den virkelige verden? Sørg for, at de genererede data opfører sig på samme måde som faktiske data uden blot at duplikere dem.
- Kan de syntetiske data revideres eller valideres? Pålidelige syntetiske data bør have valideringsmekanismer på plads.
- Overholder det lovgivningsmæssige og etiske retningslinjer? Bare fordi data er syntetiske, betyder det ikke, at de er undtaget fra reglerne om beskyttelse af personlige oplysninger.
- Er der en proces til at opdatere de underliggende datamodeller? Syntetiske data er kun så gode som de virkelige data, de er baseret på. Sikring af en proces til løbende opdatering af det grundlæggende datasæt forhindrer modeller i at blive forældede og forkert tilpasset aktuelle trends.
Indpakning
Syntetisk data er et bredt begreb, og hvis du arbejder med kunstig intelligens, analyse eller et hvilket som helst datadrevet felt, skal du være klar over, hvilken slags du har med at gøre. Udfylder du manglende data (imputation), opretter du testbrugere (brugeroprettelse), genererer anonymiserede mønstre (indsigtsmodellering) eller bygger du helt nye datasæt fra bunden (fremstillede resultater)?
Hver af disse spiller en forskellig rolle i, hvordan vi bruger og beskytter data, og at forstå dem er nøglen til at træffe informerede beslutninger i den hastigt udviklende verden af AI og datavidenskab. Så næste gang nogen kaster om sig med udtrykket "syntetiske data", så spørg dem: Hvilken slags?








