























דבר עם כל מי שעוסק בבינה מלאכותית, אנליטיקה או מדעי הנתונים, והם יגידו לך שמידע סינתטי הוא העתיד. אבל שאל אותם למה הם מתכוונים ב"נתונים סינתטיים", ותקבל תשובות שונות בתכלית. הסיבה לכך היא שנתונים סינתטיים הם לא רק דבר אחד - זו קטגוריה רחבה עם מקרי שימוש והגדרות מרובים. והעמימות הזו הופכת שיחות לבלבול.
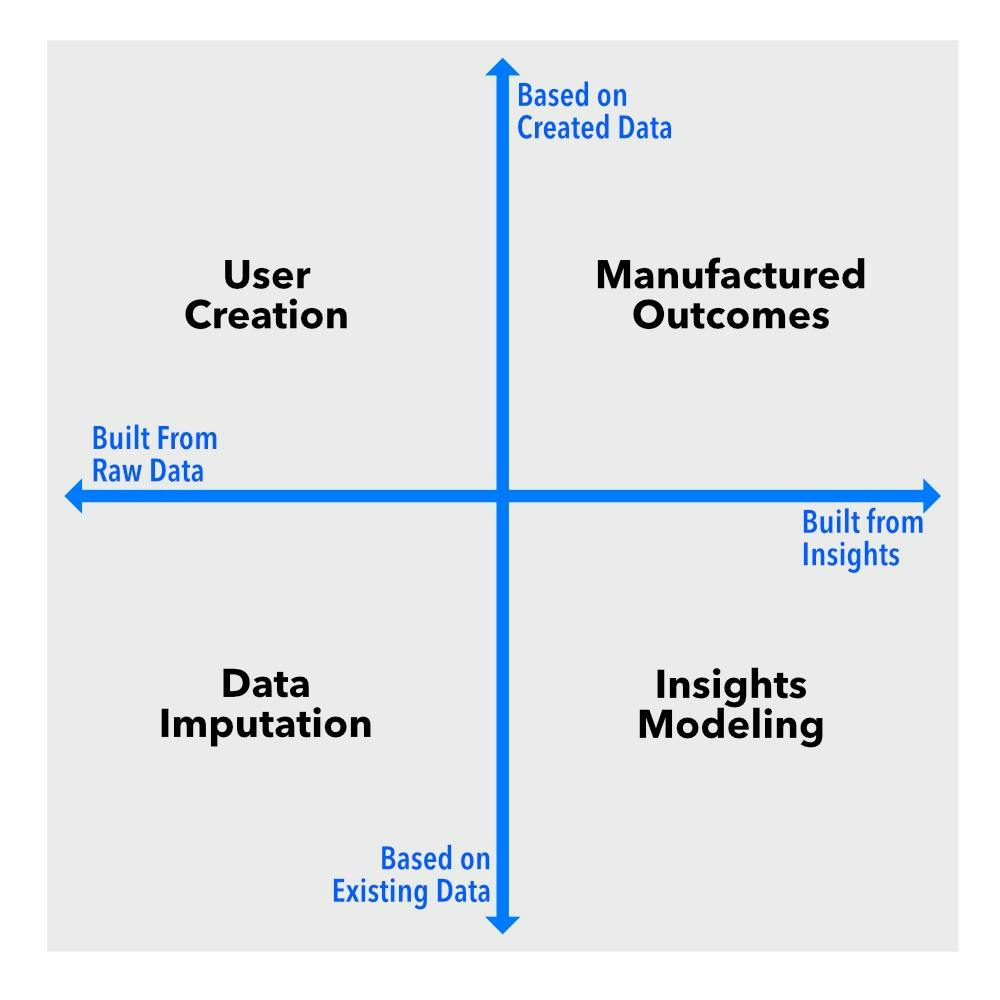
אז, בוא נחתוך את הרעש. בבסיסו, נתונים סינתטיים פועלים לאורך שני מימדים מרכזיים. הראשון הוא ספקטרום שנע בין מילוי נתונים חסרים במערך נתונים קיים ועד ליצירת מערכי נתונים חדשים לגמרי. השני מבחין בין התערבויות ברמת הנתונים הגולמיים לעומת התערבויות ברמת התובנות או התוצאות.
דמיינו את הממדים האלה כצירים בתרשים. זה יוצר ארבעה רבעים, כל אחד מייצג סוג אחר של נתונים סינתטיים: זקיפת נתונים, יצירת משתמשים, מודלים של תובנות ותוצאות מיוצרות . כל אחד מהם משרת פונקציה נפרדת, ואם אתה עובד עם נתונים בכל יכולת, אתה צריך לדעת את ההבדל.

זקיפת נתונים: מילוי החסר
בעוד שחלקם עשויים לטעון כי זקיפת נתונים אינה באמת נתונים סינתטיים, טכניקות זקיפה מודרניות התפתחו מעבר להחלפה ממוצעת או חציונית. כיום, זקיפה מתקדמת ממנפת למידת מכונה ומודלים של בינה מלאכותית, מה שהופך את הערכים שנוצרו למתוחכמים ורלוונטיים מבחינה הקשרית מאי פעם.
זקיפת נתונים נמצאת בצומת של נתונים חסרים והתערבות נתונים גולמיים . זה אומר שאנחנו עובדים עם מערכי נתונים קיימים שיש להם פערים, והמטרה שלנו היא ליצור ערכים סבירים כדי להשלים אותם. בניגוד לסוגים אחרים של נתונים סינתטיים, זקיפה לא עוסקת ביצירת מידע חדש לגמרי - אלא בהפיכת נתונים לא שלמים לשמישים יותר.
דוגמה: חברת מחקרי שוק המבצעת מחקרי אפקטיביות מדיה עשויה להופיע בפערים בנתוני תגובת הקהל שלה עקב תשובות חסרות לסקר. במקום לזרוק מערכי נתונים לא שלמים, טכניקות זקיפה - כגון מודלים סטטיסטיים או למידת מכונה - יכולות ליצור הערכות מציאותיות, מה שמבטיח שהאנליסטים עדיין יכולים להפיק תובנות משמעותיות מהנתונים.
יצירת משתמש: אנשים מזויפים, תובנות אמיתיות
יצירת המשתמש נמצאת בין יצירת נתונים חדשים להתערבות בנתונים גולמיים . במקום לשנות נתונים קיימים, גישה זו מייצרת פרופילי משתמשים והתנהגויות חדשות לחלוטין. זה שימושי במיוחד כאשר נתוני משתמש אמיתיים אינם זמינים, הם רגישים או שיש להתאים אותם באופן מלאכותי.
יצירת משתמשים היא מחליף משחק לבדיקת מוצרים, שיפור האבטחה והדרכה של מודלים של AI.
דוגמה: שירות סטרימינג עשוי ליצור פרופילי משתמש סינתטיים כדי לבדוק את מנוע ההמלצות שלו מבלי לחשוף נתוני לקוחות אמיתיים. חברות אבטחת סייבר עושות את אותו הדבר כדי לדמות תרחישי תקיפה ולהכשיר מערכות לגילוי הונאה.
מודלים של תובנות: דפוסים ללא סיכוני הפרטיות
מודלים של תובנות פועלים בצומת של נתונים קיימים והתערבות ברמת התובנות . במקום לתמרן נקודות נתונים גולמיות, הוא יוצר מערכי נתונים המשמרים את המאפיינים הסטטיסטיים של נתונים מהעולם האמיתי מבלי לחשוף רשומות ממשיות. זה הופך אותו לאידיאלי עבור יישומים רגישים לפרטיות.
מודלים של תובנות גם מאפשרים לחוקרים להרחיב תובנות ממערכי נתונים קיימים, במיוחד כאשר איסוף נתונים בקנה מידה גדול אינו מעשי. זה נפוץ במחקר שיווקי, שבו איסוף נתונים יכול להיות מסורבל ויקר. עם זאת, גישה זו דורשת בסיס איתן של נתוני אימון מהעולם האמיתי.
דוגמה: חברת מחקרי שוק המבצעת בדיקות עותק עשויה להשתמש במודלים של תובנות כדי להרחיב את מסד הנתונים הנורמטיבי שלה. במקום להסתמך רק על תשובות סקר שנאספו, המשרד יכול לייצר מודלים של תובנות סינתטיות המוציאות דפוסים מנתונים נורמטיביים קיימים. זה מאפשר למותגים לבחון ביצועים יצירתיים מול מערך נתונים רחב יותר וחזוי יותר מבלי לאסוף כל הזמן תשובות חדשות לסקר.
תוצאות מיוצרות: כאשר הנתונים עדיין לא קיימים
תוצאות מיוצרות נמצאות בקצה הקיצוני הן של יצירת נתונים חדשים והן של התערבות ברמת התובנות . גישה זו כוללת יצירת מערכי נתונים חדשים לגמרי מאפס כדי לדמות סביבות או תרחישים שעדיין לא קיימים אך חיוניים לאימון, מודלים וסימולציות של AI.
לפעמים, הנתונים שאתה צריך פשוט לא קיימים - או שהם יקרים או מסוכנים מדי לאיסוף בעולם האמיתי. זה המקום שבו התוצאות המיוצרות נכנסות לתמונה. תהליך זה מייצר מערכי נתונים חדשים לחלוטין, לעתים קרובות כדי לאמן מערכות AI בסביבות שקשה לשכפל.
דוגמה: חברות מכוניות בנהיגה עצמית מייצרות תרחישי כביש סינתטיים - כמו הולך רגל שפתאום מתרוצץ - כדי לאמן את הבינה המלאכותית שלהן במצבים נדירים אך קריטיים שאולי לא יופיעו לעתים קרובות בצילומי נהיגה מהעולם האמיתי.
סיכונים ושיקולים של נתונים סינתטיים
נתונים סינתטיים אמנם מספקים פתרונות רבי עוצמה, אך הם אינם נטולי סיכונים. לכל סוג של נתונים סינתטיים יש אתגרים משלו שיכולים להשפיע על איכות הנתונים, המהימנות והשימוש האתי. הנה כמה דאגות עיקריות שכדאי לזכור:
- הפצת הטיה: אם הנתונים הבסיסיים המשמשים לזקיפה, מודלים של תובנות או תוצאות מיוצרות מכילים הטיה, ניתן לחזק או אפילו להגביר את ההטיות הללו.
- חוסר ייצוגיות בעולם האמיתי: יצירת משתמשים וייצור נתונים עשויים לייצר נתונים שנראים מציאותיים אך אינם מצליחים ללכוד את הניואנסים של התנהגות המשתמש בפועל או תנאי השוק.
- התאמת יתר וביטחון כוזב: מודלים של תובנות, כשהם מיושמים בצורה לא נכונה, עלולים ליצור נתונים המתואמים מדי עם מערך האימונים, מה שמוביל למסקנות מטעות.
- חששות רגולטוריים ואתיים: חוקי פרטיות כמו GDPR ו-CCPA עדיין חלים על נתונים סינתטיים אם ניתן לבצע הנדסה לאחור כדי לזהות אנשים אמיתיים.
שאלות עיקריות שיש לשאול בעת הערכת נתונים סינתטיים
כדי להבטיח שהנתונים הסינתטיים עומדים בתקני איכות, שקול את השאלות הבאות:
- מה מקור הנתונים המקוריים? הבנת הבסיס של נתונים סינתטיים עוזרת להעריך הטיות ומגבלות פוטנציאליות.
- כיצד נוצרו הנתונים הסינטטיים? שיטות שונות - למידת מכונה, מודלים סטטיסטיים או מערכות מבוססות כללים - משפיעות על המהימנות של נתונים סינתטיים.
- האם הנתונים הסינתטיים שומרים על השלמות הסטטיסטית של נתונים מהעולם האמיתי? ודא שהנתונים שנוצרו מתנהגים בדומה לנתונים בפועל מבלי רק לשכפל אותם.
- האם ניתן לבדוק או לאמת את הנתונים הסינתטיים? לנתונים סינתטיים אמינים צריכים להיות מנגנוני אימות.
- האם הוא עומד בהנחיות הרגולטוריות והאתיות? זה שהנתונים הם סינתטיים לא אומר שהם פטורים מתקנות הפרטיות.
- האם יש תהליך לעדכון מודלים הנתונים הבסיסיים? נתונים סינתטיים טובים רק כמו הנתונים בעולם האמיתי שהם מבוססים עליהם. הבטחת תהליך לעדכון מתמיד של מערך הנתונים הבסיסי מונעת ממודלים להיות מיושנים ולא מתאימים למגמות הנוכחיות.
עוטף את זה
נתונים סינתטיים הם מונח רחב, ואם אתה עובד בבינה מלאכותית, אנליטיקה או כל תחום מבוסס נתונים, עליך להיות ברור באיזה סוג אתה מתמודד. האם אתה ממלא נתונים חסרים (זקיפה), יוצר משתמשי בדיקה (יצירת משתמשים), יוצר דפוסים אנונימיים (מודלים של תובנות), או בונה מערכי נתונים חדשים לגמרי מאפס (תוצאות מיוצרות)?
כל אחד מאלה ממלא תפקיד אחר באופן שבו אנו משתמשים בנתונים ומגנים עליהם, והבנתם היא המפתח לקבלת החלטות מושכלות בעולם המתפתח במהירות של AI ומדעי הנתונים. אז בפעם הבאה שמישהו זורק את המונח "נתונים סינתטיים", שאל אותם: איזה סוג?




