























AI、分析、データ サイエンスの分野の人に話を聞くと、誰もが合成データこそが未来だと言うでしょう。しかし、「合成データ」の意味を尋ねると、まったく異なる答えが返ってきます。合成データは 1 つのものではなく、複数のユース ケースと定義を持つ幅広いカテゴリだからです。そして、その曖昧さが会話を混乱させます。
それでは、ノイズを排除してみましょう。合成データは、本質的に 2 つの主要な次元に沿って機能します。1 つ目は、既存のデータセットの欠落データの補完から、まったく新しいデータセットの生成までの範囲です。2 つ目は、生データ レベルでの介入と、洞察または結果レベルでの介入を区別します。
これらのディメンションをグラフの軸として想像してください。これにより 4 つの象限が作成され、それぞれが異なるタイプの合成データ (データ補完、ユーザー作成、インサイト モデリング、および製造された結果)を表します。それぞれが異なる機能を果たすため、何らかの形でデータを扱う場合は、その違いを知っておく必要があります。

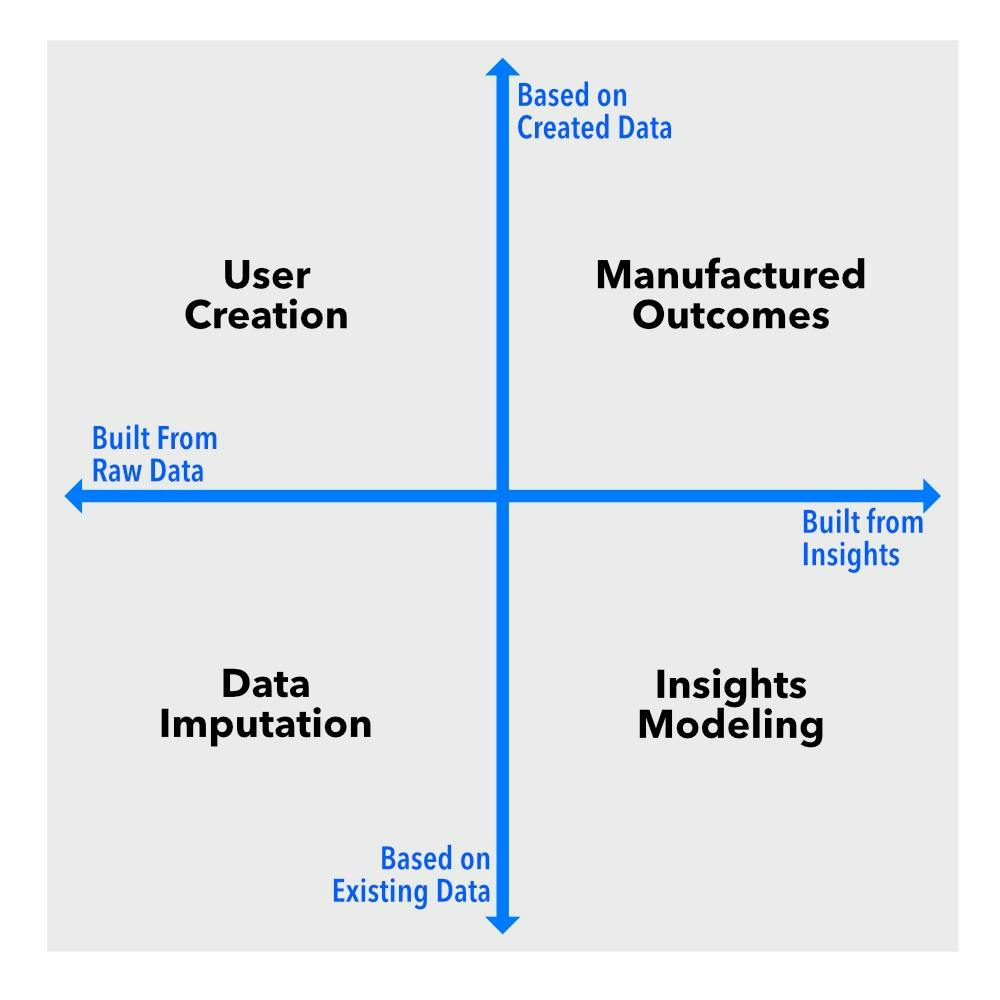
データ補完: 空白を埋める
データ補完は真の意味での合成データではないと主張する人もいるかもしれませんが、現代の補完技術は単純な平均値や中央値の置換を超えて進化しています。今日、高度な補完では機械学習と生成 AI モデルを活用し、生成される値はこれまで以上に洗練され、文脈的に関連性のあるものになっています。
データ補完は、欠損データと生データ介入の交差点に位置します。つまり、ギャップのある既存のデータセットを扱い、妥当な値を生み出してギャップを埋めることが目標です。他の種類の合成データとは異なり、補完はまったく新しい情報を作成することではなく、不完全なデータをより使いやすくすることです。
例:メディアの有効性調査を実施している市場調査会社では、アンケートの回答が欠落しているために視聴者の反応データに欠落が生じることがあります。不完全なデータセットを破棄する代わりに、統計モデリングや機械学習などの補完技術を使用すると現実的な推定値を生成できるため、アナリストは引き続きデータから有意義な洞察を引き出すことができます。
ユーザーの作成: 偽の人物、本物の洞察
ユーザー作成は、新しいデータの生成と生データの介入の間にあります。このアプローチでは、既存のデータを変更するのではなく、まったく新しいユーザー プロファイルと動作を作成します。実際のユーザー データが利用できない、機密性が高い、または人工的にスケーリングする必要がある場合に特に便利です。
ユーザーの作成は、製品のテスト、セキュリティの向上、AI モデルのトレーニングに大きな変化をもたらします。
例:ストリーミング サービスは、実際の顧客データを公開せずに推奨エンジンをテストするために、合成ユーザー プロファイルを作成する場合があります。サイバー セキュリティ企業も同様のことを行って、攻撃シナリオをシミュレートし、不正検出システムをトレーニングします。
インサイトモデリング: プライバシーリスクのないパターン
インサイト モデリングは、既存のデータとインサイト レベルでの介入の交差点で機能します。生のデータ ポイントを操作する代わりに、実際のレコードを公開せずに現実世界のデータの統計的特性を保持するデータセットを作成します。そのため、プライバシーに配慮したアプリケーションに最適です。
また、インサイト モデリングにより、研究者は既存のデータセットからインサイトを拡張することもできます。特に、大規模なデータの収集が現実的でない場合に有効です。これは、データ収集が面倒でコストがかかるマーケティング調査では一般的です。ただし、このアプローチには、実際のトレーニング データの強固な基盤が必要です。
例:コピーテストを実施する市場調査会社は、インサイト モデリングを使用して規範データベースを拡張できます。収集された調査回答のみに頼るのではなく、既存の規範データからパターンを推定する合成インサイト モデルを生成できます。これにより、ブランドは新しい調査回答を継続的に収集することなく、より広範で予測力の高いデータセットに対してクリエイティブなパフォーマンスをテストできます。
結果の捏造: データがまだ存在しないとき
製造された成果は、新しいデータ生成と洞察レベルの介入の両方の極端な端に位置します。このアプローチでは、AI のトレーニング、モデリング、シミュレーションに不可欠な、まだ存在しない環境やシナリオをシミュレートするために、まったく新しいデータセットをゼロから生成します。
必要なデータが存在しない、または現実世界で収集するにはコストがかかりすぎたり危険だったりする場合もあります。そこで Manufactured Outcomes の出番です。このプロセスでは、まったく新しいデータセットを生成し、多くの場合、再現が難しい環境で AI システムをトレーニングします。
例:自動運転車の企業は、歩行者が突然信号無視をするなどの合成道路シナリオを生成し、実際の運転映像ではあまり見られない、まれではあるが重大な状況について AI をトレーニングします。
合成データのリスクと考慮事項
合成データは強力なソリューションを提供しますが、リスクがないわけではありません。合成データの種類ごとに、データの品質、信頼性、倫理的使用に影響を与える可能性のある独自の課題があります。以下に、留意すべき重要な懸念事項をいくつか示します。
- バイアスの伝播:代入、インサイト モデリング、または製造された結果に使用される基礎データにバイアスが含まれている場合、それらのバイアスは強化されたり、増幅されたりする可能性があります。
- 現実世界の代表性の欠如:ユーザーの作成とデータの製造により、現実的に見えるデータが生成される可能性がありますが、実際のユーザー行動や市場状況のニュアンスを捉えることはできません。
- 過剰適合と誤った自信: Insights モデリングは、不適切に適用された場合、トレーニング セットと近すぎるデータを作成し、誤解を招く結論につながる可能性があります。
- 規制と倫理上の懸念: リバースエンジニアリングによって実際の個人を特定できる場合、GDPR や CCPA などのプライバシー法は合成データにも適用されます。
合成データを評価する際に尋ねるべき重要な質問
合成データが品質基準を満たしていることを確認するには、次の質問を考慮してください。
- 元のデータのソースは何ですか?合成データの基礎を理解することは、潜在的なバイアスや制限を評価するのに役立ちます。
- 合成データはどのように生成されましたか?機械学習、統計モデル、ルールベースのシステムなど、さまざまな方法が合成データの信頼性に影響を与えます。
- 合成データは現実世界のデータの統計的整合性を維持していますか?生成されたデータが実際のデータを単に複製するのではなく、実際のデータと同様に動作することを確認します。
- 合成データは監査または検証できますか?信頼性の高い合成データには検証メカニズムが備わっている必要があります。
- 規制および倫理ガイドラインに準拠していますか?データが合成されているからといって、プライバシー規制が免除されるわけではありません。
- 基礎となるデータ モデルを更新するプロセスはありますか?合成データは、その基となる現実世界のデータと同じ品質でしか提供されません。基礎となるデータセットを継続的に更新するプロセスを確保することで、モデルが古くなり、現在の傾向と一致しなくなるのを防ぐことができます。
まとめ
合成データは幅広い用語であり、AI、分析、またはデータ駆動型の分野で作業している場合は、どのような種類のデータを扱っているかを明確にする必要があります。欠落しているデータを埋める (代入)、テスト ユーザーを作成する (ユーザー作成)、匿名化されたパターンを生成する (インサイト モデリング)、またはまったく新しいデータセットをゼロから構築する (製造された結果) のでしょうか。
これらはそれぞれ、データの使用方法と保護方法において異なる役割を果たしており、これらを理解することは、急速に進化する AI とデータ サイエンスの世界で情報に基づいた意思決定を行うための鍵となります。次に誰かが「合成データ」という言葉を口にしたら、次のように尋ねてみてください。「どの種類ですか?」








