























พูดคุยกับใครก็ได้ในสาขา AI การวิเคราะห์ หรือวิทยาศาสตร์ข้อมูล และพวกเขาจะบอกคุณว่าข้อมูลสังเคราะห์คืออนาคต แต่ถ้าคุณถามพวกเขาว่าพวกเขาหมายถึงอะไรด้วยคำว่า "ข้อมูลสังเคราะห์" คุณจะได้รับคำตอบที่แตกต่างกันอย่างสิ้นเชิง นั่นเป็นเพราะว่าข้อมูลสังเคราะห์ไม่ได้เป็นเพียงสิ่งเดียว แต่เป็นหมวดหมู่กว้างๆ ที่มีกรณีการใช้งานและคำจำกัดความหลายแบบ และความคลุมเครือนี้ทำให้การสนทนาเกิดความสับสน
ดังนั้น มาตัดส่วนที่ไม่จำเป็นออกไปกันดีกว่า โดยพื้นฐานแล้ว ข้อมูลสังเคราะห์ทำงานตามสองมิติหลัก มิติแรกคือสเปกตรัมตั้งแต่การเติมข้อมูลที่ขาดหายไปในชุดข้อมูลที่มีอยู่ไปจนถึงการสร้างชุดข้อมูลใหม่ทั้งหมด มิติที่สองจะแยกความแตกต่างระหว่างการแทรกแซงที่ระดับข้อมูลดิบกับการแทรกแซงที่ระดับข้อมูลเชิงลึกหรือผลลัพธ์
ลองนึกภาพว่ามิติเหล่านี้เป็นแกนบนแผนภูมิ ซึ่งจะทำให้ได้สี่ควอดแรนต์ ซึ่งแต่ละควอดแรนต์จะแสดงถึงข้อมูลสังเคราะห์ประเภทต่างๆ ได้แก่ การใส่ข้อมูล การสร้างผู้ใช้ การสร้างแบบจำลองข้อมูลเชิงลึก และผลลัพธ์ที่สร้างขึ้น แต่ละควอดแรนต์มีหน้าที่ที่แตกต่างกัน และหากคุณทำงานกับข้อมูลในรูปแบบใดก็ตาม คุณจะต้องทราบถึงความแตกต่างเหล่านี้

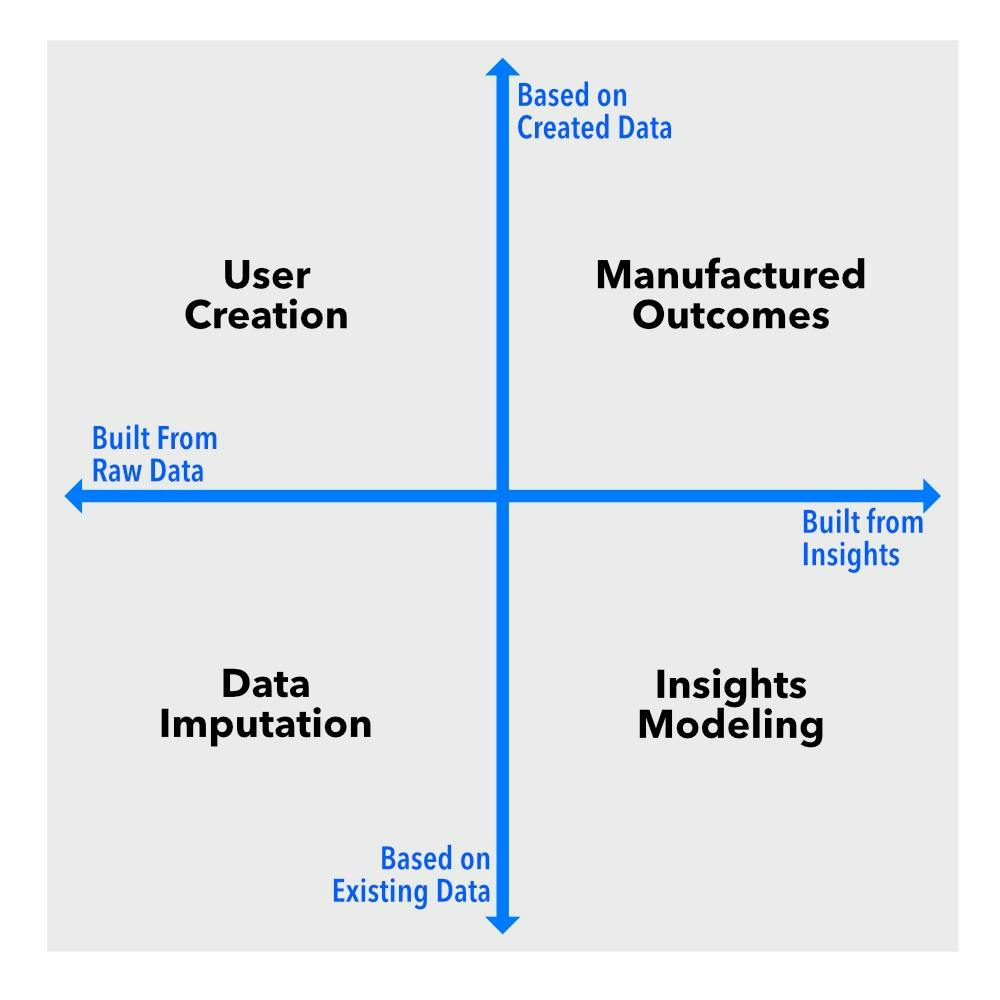
การใส่ข้อมูล: การเติมช่องว่าง
แม้ว่าบางคนอาจโต้แย้งว่าการนำข้อมูลมาใส่แทนค่าไม่ใช่ข้อมูลสังเคราะห์อย่างแท้จริง แต่เทคนิคการนำข้อมูลมาใส่แทนค่าสมัยใหม่ได้พัฒนาไปไกลเกินกว่าการแทนที่ค่าเฉลี่ยหรือค่ามัธยฐานแบบธรรมดา ปัจจุบัน การนำข้อมูลมาใส่แทนค่าขั้นสูงใช้ประโยชน์จากการเรียนรู้ของเครื่องจักรและโมเดล AI เชิงสร้างสรรค์ ทำให้ค่าที่สร้างขึ้นมีความซับซ้อนและเกี่ยวข้องกับบริบทมากกว่าที่เคย
การแทนค่าข้อมูลเกิดขึ้นที่จุดตัดระหว่าง ข้อมูลที่ขาดหายไป และ การแทรกแซงข้อมูลดิบ ซึ่งหมายความว่าเรากำลังทำงานกับชุดข้อมูลที่มีอยู่ซึ่งมีช่องว่าง และเป้าหมายของเราคือการสร้างค่าที่สมเหตุสมผลเพื่อทำให้ชุดข้อมูลเหล่านั้นสมบูรณ์ ซึ่งแตกต่างจากข้อมูลสังเคราะห์ประเภทอื่น การแทนค่าไม่ได้เกี่ยวกับการสร้างข้อมูลใหม่ทั้งหมด แต่เป็นการทำให้ข้อมูลที่ไม่สมบูรณ์สามารถใช้งานได้มากขึ้น
ตัวอย่าง: บริษัทวิจัยตลาดที่ดำเนินการศึกษาประสิทธิผลของสื่ออาจมีช่องว่างในข้อมูลการตอบสนองของผู้ชมเนื่องจากขาดคำตอบจากแบบสำรวจ แทนที่จะทิ้งชุดข้อมูลที่ไม่สมบูรณ์ เทคนิคการคำนวณ เช่น การสร้างแบบจำลองทางสถิติหรือการเรียนรู้ของเครื่องจักร สามารถสร้างการประมาณการที่สมจริงได้ ทำให้มั่นใจได้ว่านักวิเคราะห์ยังคงสามารถดึงข้อมูลเชิงลึกที่มีความหมายจากข้อมูลได้
การสร้างผู้ใช้: คนปลอม, ข้อมูลเชิงลึกที่แท้จริง
การสร้างผู้ใช้อยู่ระหว่าง การสร้างข้อมูลใหม่ และ การแทรกแซงข้อมูลดิบ แทนที่จะแก้ไขข้อมูลที่มีอยู่ วิธีนี้จะสร้างโปรไฟล์และพฤติกรรมผู้ใช้ใหม่ทั้งหมด ซึ่งมีประโยชน์อย่างยิ่งเมื่อไม่มีข้อมูลผู้ใช้จริง ละเอียดอ่อน หรือจำเป็นต้องปรับขนาดโดยเทียม
การสร้างของผู้ใช้ถือเป็นตัวเปลี่ยนเกมสำหรับการทดสอบผลิตภัณฑ์ การปรับปรุงความปลอดภัย และการฝึกอบรมโมเดล AI
ตัวอย่าง: บริการสตรีมมิ่งอาจสร้างโปรไฟล์ผู้ใช้แบบสังเคราะห์เพื่อทดสอบระบบแนะนำโดยไม่เปิดเผยข้อมูลลูกค้าจริง บริษัทด้านความปลอดภัยทางไซเบอร์ทำแบบเดียวกันเพื่อจำลองสถานการณ์การโจมตีและฝึกระบบตรวจจับการฉ้อโกง
การสร้างแบบจำลองเชิงลึก: รูปแบบที่ไม่มีความเสี่ยงต่อความเป็นส่วนตัว
การสร้างแบบจำลองเชิงลึกทำงานที่จุดตัดระหว่าง ข้อมูลที่มีอยู่ และ การแทรกแซงในระดับเชิงลึก แทนที่จะจัดการจุดข้อมูลดิบ การสร้างแบบจำลองนี้จะสร้างชุดข้อมูลที่รักษาคุณสมบัติทางสถิติของข้อมูลในโลกแห่งความเป็นจริงโดยไม่เปิดเผยระเบียนจริง ซึ่งทำให้การสร้างแบบจำลองนี้เหมาะอย่างยิ่งสำหรับแอปพลิเคชันที่คำนึงถึงความเป็นส่วนตัว
การสร้างแบบจำลองข้อมูลเชิงลึกยังช่วยให้นักวิจัยสามารถปรับขนาดข้อมูลเชิงลึกจากชุดข้อมูลที่มีอยู่เดิมได้ โดยเฉพาะอย่างยิ่งเมื่อการรวบรวมข้อมูลขนาดใหญ่ไม่สามารถทำได้ในทางปฏิบัติ ซึ่งเป็นเรื่องปกติในงานวิจัยการตลาดที่การรวบรวมข้อมูลอาจยุ่งยากและมีค่าใช้จ่ายสูง อย่างไรก็ตาม แนวทางนี้จำเป็นต้องมีข้อมูลการฝึกอบรมในโลกแห่งความเป็นจริงที่มั่นคง
ตัวอย่าง: บริษัทวิจัยตลาดที่ดำเนินการทดสอบสำเนาอาจใช้การสร้างแบบจำลองข้อมูลเชิงลึกเพื่อปรับขนาดฐานข้อมูลเชิงบรรทัดฐาน แทนที่จะพึ่งพาคำตอบจากแบบสำรวจที่รวบรวมไว้เพียงอย่างเดียว บริษัทสามารถสร้างแบบจำลองข้อมูลเชิงลึกแบบสังเคราะห์ที่ขยายรูปแบบจากข้อมูลเชิงบรรทัดฐานที่มีอยู่ได้ วิธีนี้ช่วยให้แบรนด์ต่างๆ สามารถทดสอบประสิทธิภาพการสร้างสรรค์ผลงานกับชุดข้อมูลที่กว้างขึ้นและคาดการณ์ได้มากขึ้นโดยไม่ต้องรวบรวมคำตอบจากแบบสำรวจใหม่ๆ อย่างต่อเนื่อง
ผลลัพธ์ที่สร้างขึ้น: เมื่อยังไม่มีข้อมูล
ผลลัพธ์ที่สร้างขึ้นจะอยู่ที่จุดสุดขั้วของทั้ง การสร้างข้อมูลใหม่ และ การแทรกแซงในระดับข้อมูลเชิงลึก แนวทางนี้เกี่ยวข้องกับการสร้างชุดข้อมูลใหม่ทั้งหมดตั้งแต่เริ่มต้นเพื่อจำลองสภาพแวดล้อมหรือสถานการณ์ที่ยังไม่มีอยู่แต่มีความจำเป็นสำหรับการฝึกอบรม AI การสร้างแบบจำลอง และการจำลอง
บางครั้ง ข้อมูลที่คุณต้องการอาจไม่มีอยู่จริง หรือมีราคาแพงเกินไปหรืออันตรายเกินกว่าจะรวบรวมในโลกแห่งความเป็นจริง นั่นคือที่มาของผลลัพธ์ที่สร้างขึ้น กระบวนการนี้จะสร้างชุดข้อมูลใหม่ทั้งหมด โดยมักจะใช้เพื่อฝึกระบบ AI ในสภาพแวดล้อมที่จำลองได้ยาก
ตัวอย่าง: บริษัทผู้ผลิตยานพาหนะขับเคลื่อนอัตโนมัติสร้างสถานการณ์จำลองบนท้องถนน เช่น คนเดินถนนข้ามถนนโดยไม่สนใจกฎจราจร เพื่อฝึก AI ในสถานการณ์ที่เกิดขึ้นไม่บ่อยนักแต่สำคัญซึ่งอาจไม่เกิดขึ้นบ่อยนักในภาพการขับขี่ในโลกแห่งความเป็นจริง
ความเสี่ยงและการพิจารณาข้อมูลสังเคราะห์
แม้ว่าข้อมูลสังเคราะห์จะให้โซลูชันที่มีประสิทธิภาพ แต่ก็ไม่ได้ปราศจากความเสี่ยง ข้อมูลสังเคราะห์แต่ละประเภทมีข้อท้าทายเฉพาะตัวที่อาจส่งผลต่อคุณภาพข้อมูล ความน่าเชื่อถือ และการใช้งานข้อมูลอย่างถูกต้อง ต่อไปนี้คือข้อกังวลสำคัญบางประการที่ควรคำนึงถึง:
- การแพร่กระจายอคติ: หากข้อมูลพื้นฐานที่ใช้สำหรับการคำนวณ การสร้างแบบจำลองเชิงข้อมูลเชิงลึก หรือผลลัพธ์ที่สร้างขึ้น มีอคติ อคติเหล่านั้นก็อาจได้รับการเสริมกำลังหรือแม้กระทั่งขยายตัวเพิ่มขึ้นได้
- ขาดการเป็นตัวแทนจากโลกแห่งความเป็นจริง: การสร้างผู้ใช้และการผลิตข้อมูลอาจสร้างข้อมูลที่ดูเหมือนจริงแต่ไม่สามารถจับรายละเอียดของพฤติกรรมผู้ใช้จริงหรือเงื่อนไขตลาดได้
- การโอเวอร์ฟิตติ้งและความเชื่อมั่นที่ผิด: การสร้างแบบจำลองเชิงลึก หากนำไปใช้อย่างไม่ถูกต้อง สามารถสร้างข้อมูลที่สอดคล้องกับชุดการฝึกมากเกินไป จนนำไปสู่ข้อสรุปที่เข้าใจผิดได้
- ข้อกังวลด้านกฎระเบียบและจริยธรรม: กฎหมายความเป็นส่วนตัว เช่น GDPR และ CCPA ยังคงบังคับใช้กับข้อมูลสังเคราะห์หากสามารถถอดรหัสย้อนกลับเพื่อระบุบุคคลจริงได้
คำถามสำคัญที่ต้องถามเมื่อประเมินข้อมูลสังเคราะห์
เพื่อให้แน่ใจว่าข้อมูลสังเคราะห์เป็นไปตามมาตรฐานคุณภาพ โปรดพิจารณาคำถามเหล่านี้:
- แหล่งที่มาของข้อมูลต้นฉบับคืออะไร การทำความเข้าใจรากฐานของข้อมูลสังเคราะห์จะช่วยประเมินอคติและข้อจำกัดที่อาจเกิดขึ้นได้
- ข้อมูลสังเคราะห์ถูกสร้างขึ้นมาได้อย่างไร วิธีการต่างๆ เช่น การเรียนรู้ของเครื่องจักร โมเดลสถิติ หรือระบบตามกฎเกณฑ์ ล้วนส่งผลกระทบต่อความน่าเชื่อถือของข้อมูลสังเคราะห์
- ข้อมูลสังเคราะห์ช่วยรักษาความสมบูรณ์ทางสถิติของข้อมูลในโลกแห่งความเป็นจริงได้หรือไม่ ตรวจ สอบให้แน่ใจว่าข้อมูลที่สร้างขึ้นมีการทำงานคล้ายกับข้อมูลจริงโดยไม่เพียงทำซ้ำเท่านั้น
- ข้อมูลสังเคราะห์สามารถตรวจสอบหรือยืนยันได้หรือไม่ ข้อมูลสังเคราะห์ที่เชื่อถือได้ควรมีกลไกการตรวจสอบยืนยัน
- ข้อมูลดังกล่าวสอดคล้องกับหลักเกณฑ์ด้านกฎระเบียบและจริยธรรมหรือ ไม่ เพียงเพราะข้อมูลเป็นข้อมูลสังเคราะห์ไม่ได้หมายความว่าข้อมูลดังกล่าวจะได้รับการยกเว้นจากกฎระเบียบด้านความเป็นส่วนตัว
- มีกระบวนการในการอัปเดตโมเดลข้อมูลพื้นฐานหรือไม่ ข้อมูลสังเคราะห์จะมีประสิทธิภาพเท่ากับข้อมูลในโลกแห่งความเป็นจริงที่ใช้เป็นพื้นฐาน การมีกระบวนการอัปเดตชุดข้อมูลพื้นฐานอย่างต่อเนื่องจะช่วยป้องกันไม่ให้โมเดลล้าสมัยและไม่สอดคล้องกับแนวโน้มปัจจุบัน
การห่อมันขึ้นมา
ข้อมูลสังเคราะห์เป็นคำที่มีความหมายกว้าง และหากคุณทำงานในด้านปัญญาประดิษฐ์ การวิเคราะห์ หรือสาขาใดๆ ที่ขับเคลื่อนด้วยข้อมูล คุณต้องชัดเจนว่าคุณกำลังจัดการกับข้อมูลประเภทใด คุณกำลังเติมเต็มข้อมูลที่ขาดหายไป (การใส่ค่า) สร้างผู้ใช้ทดสอบ (การสร้างผู้ใช้) สร้างรูปแบบที่ไม่ระบุตัวตน (การสร้างแบบจำลองข้อมูลเชิงลึก) หรือสร้างชุดข้อมูลใหม่ทั้งหมดตั้งแต่ต้น (ผลลัพธ์ที่ผลิตขึ้น) หรือไม่
ข้อมูลแต่ละประเภทมีบทบาทที่แตกต่างกันในการใช้และปกป้องข้อมูล การทำความเข้าใจข้อมูลเหล่านี้ถือเป็นกุญแจสำคัญในการตัดสินใจอย่างรอบรู้ในโลกของ AI และวิทยาศาสตร์ข้อมูลที่กำลังเปลี่ยนแปลงอย่างรวดเร็ว ดังนั้น คราวหน้าหากใครพูดถึงคำว่า "ข้อมูลสังเคราะห์" ให้ถามพวกเขาว่าข้อมูลประเภทใด








