
























Përshëndetje njerëz të bukur! Shpresoj që viti 2025 po ju trajton mirë, edhe pse deri tani ka qenë i trazuar për mua.
Mirë se vini në blogun "Doodles and Programming" dhe sot do të ndërtojmë: Një model të analizës së ndjenjave duke përdorur TensorFlow + Python.


Në këtë tutorial, ne do të mësojmë gjithashtu për bazat e Mësimit të Makinerisë me Python, dhe siç u përmend më parë, ne do të jemi në gjendje të ndërtojmë modelin tonë të mësimit të makinerisë me Tensorflow, një bibliotekë Python. Ky model do të jetë në gjendje të zbulojë tonin/emocionin e tekstit hyrës , duke studiuar dhe mësuar nga grupi i të dhënave të mostrës së ofruar.
Parakushtet
Gjithçka që na nevojitet është disa njohuri për Python (gjërat më themelore, sigurisht), dhe gjithashtu, sigurohuni që të keni të instaluar Python në sistemin tuaj (rekomandohet Python 3.9+).
Megjithatë, nëse e keni të vështirë të kaloni nëpër këtë tutorial, mos u shqetësoni! Më dërgoni një email ose një mesazh; Unë do të kthehem tek ju ASAP.
Në rast se nuk jeni në dijeni, çfarë është Learning Machine?
Me fjalë të thjeshta, Machine Learning (ML) po e bën kompjuterin të mësojë dhe të bëjë parashikime, duke studiuar të dhëna dhe statistika. Duke studiuar të dhënat e dhëna, kompjuteri mund të identifikojë dhe nxjerrë modele dhe më pas të bëjë parashikime bazuar në to. Identifikimi i emaileve të padëshiruara, njohja e të folurit dhe parashikimi i trafikut janë disa raste të përdorimit në jetën reale të Learning Machine.
Për një shembull më të mirë, imagjinoni se duam t'i mësojmë një kompjuteri të njohë macet në foto. Do t'i tregoni shumë fotografi të maceve dhe do t'i thoshit, "Hej, kompjuter, këto janë mace!" Kompjuteri shikon fotot dhe fillon të vërejë modele - si veshë me majë, mustaqe dhe lesh. Pasi të ketë parë shembuj të mjaftueshëm, mund të njohë një mace në një foto të re që nuk e ka parë më parë.


Një sistem i tillë që ne përfitojmë çdo ditë janë filtrat e postës elektronike të padëshiruar. Imazhi i mëposhtëm tregon se si është bërë.


Pse të përdorni Python?
Edhe pse gjuha e programimit Python nuk është ndërtuar posaçërisht për ML ose Data Science, ajo konsiderohet një gjuhë e shkëlqyer programimi për ML për shkak të përshtatshmërisë së saj. Me qindra biblioteka të disponueshme për shkarkim falas, çdokush mund të ndërtojë me lehtësi modele ML duke përdorur një bibliotekë të para-ndërtuar pa pasur nevojë të programojë procedurën e plotë nga e para.
TensorFlow është një bibliotekë e tillë e ndërtuar nga Google për Mësimin e Makinerisë dhe Inteligjencën Artificiale. TensorFlow përdoret shpesh nga shkencëtarët e të dhënave, inxhinierët e të dhënave dhe zhvilluesit e tjerë për të ndërtuar lehtësisht modele të mësimit të makinerive, pasi përbëhet nga një shumëllojshmëri algoritmesh të mësimit të makinerive dhe AI.
Vizitoni faqen zyrtare të TensorFlow
Instalimi
Për të instaluar Tensorflow, ekzekutoni komandën e mëposhtme në terminalin tuaj:
pip install tensorflowDhe për të instaluar Pandas dhe Numpy,
pip install pandas numpyJu lutemi shkarkoni skedarin e mostrës CSV nga kjo depo: Github Repository - Model TensorFlow ML
Kuptimi i të dhënave
Rregulli numër 1 i analizës së të dhënave dhe çdo gjë që bazohet në të dhëna: Kuptoni së pari të dhënat që keni.
Në këtë rast, grupi i të dhënave ka dy kolona: Teksti dhe Ndjenja. Ndërsa kolona "tekst" ka një sërë deklaratash të bëra për filma, libra etj., kolona "ndjenja" tregon nëse teksti është pozitiv, neutral ose negativ, duke përdorur respektivisht numrat 1, 2 dhe 0.
Përgatitja e të Dhënave
Rregulli tjetër i përgjithshëm është pastrimi i dublikatave dhe heqja e vlerave null në të dhënat tuaja të mostrës. Por në këtë rast, duke qenë se grupi i të dhënave është mjaft i vogël dhe nuk përmban vlera të kopjuara ose të pavlefshme, ne mund të anashkalojmë procesin e pastrimit të të dhënave.


Për të filluar ndërtimin e modelit, ne duhet të mbledhim dhe të përgatisim grupin e të dhënave për të trajnuar modelin e analizës së ndjenjave. Pandat, një bibliotekë e njohur për analizën dhe manipulimin e të dhënave, mund të përdoren për këtë detyrë.
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values Kodi i mësipërm konverton skedarin CSV në një kornizë të dhënash, duke përdorur një funksion pandas.read_csv() . Më pas, cakton vlerat e kolonës "sentiment" në një listë Python duke përdorur funksionin tolist() dhe krijon një grup Numpy me vlerat.
Pse të përdorni një grup Numpy?
Siç mund ta dini tashmë, Numpy është ndërtuar në thelb për manipulimin e të dhënave. Vargjet Numpy trajtojnë në mënyrë efikase etiketat numerike për detyrat e mësimit të makinerive, gjë që ofron fleksibilitet në organizimin e të dhënave. Kjo është arsyeja pse ne po përdorim Numpy në këtë rast.
Përpunimi i tekstit
Pas përgatitjes së të dhënave të mostrës, ne duhet të ripërpunojmë Tekstin, i cili përfshin Tokenizimin.
Tokenizimi është procesi i ndarjes së çdo mostre teksti në fjalë ose shenja individuale, në mënyrë që të mund të konvertojmë të dhënat e tekstit të papërpunuar në një format që mund të përpunohet nga modeli , duke e lejuar atë të kuptojë dhe të mësojë nga fjalët individuale në mostrat e tekstit. .
Referojuni imazhit të mëposhtëm për të mësuar se si funksionon tokenizimi.
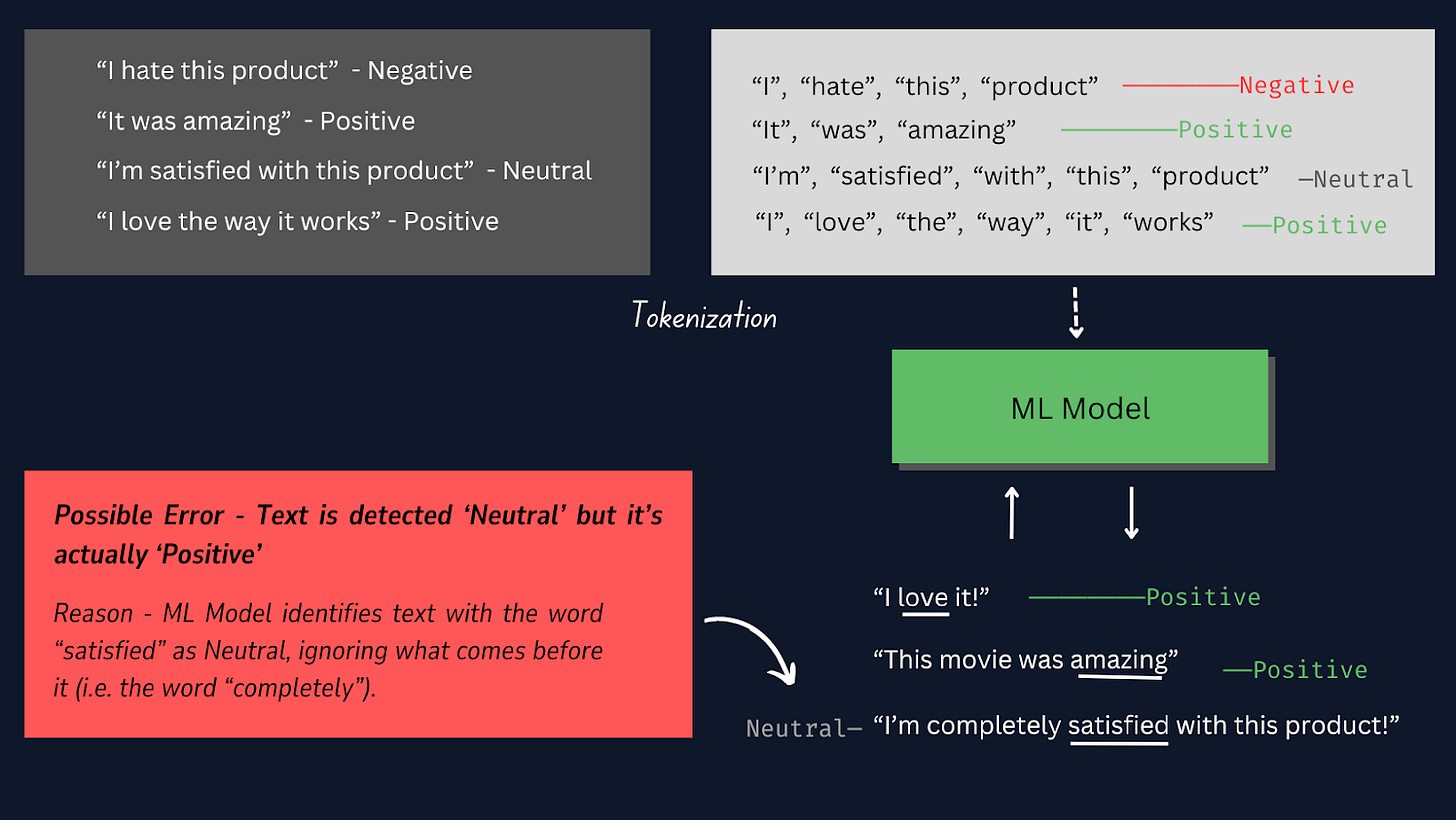
Në këtë projekt, është më mirë të përdoret tokenizimi manual në vend të tokenizuesve të tjerë të para-ndërtuar pasi na siguron më shumë kontroll mbi procesin e tokenizimit, siguron përputhshmëri me formate specifike të të dhënave dhe lejon hapa të përshtatur të parapërpunimit.
Shënim: Në Manual Tokenization, ne shkruajmë kodin për të ndarë tekstin në fjalë, i cili është shumë i personalizueshëm sipas nevojave të projektit. Megjithatë, metoda të tjera, të tilla si përdorimi i TensorFlow Keras Tokenizer, vijnë me mjete dhe funksione të gatshme për ndarjen automatike të tekstit, gjë që është më e lehtë për t'u zbatuar, por më pak e personalizueshme.
Në vijim është pjesa e kodit që mund të përdorim për tokenizimin e të dhënave të mostrës.
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)Në kodin e mësipërm,
-
word_index: Një fjalor bosh i krijuar për të ruajtur çdo fjalë unike në grupin e të dhënave, së bashku me vlerën e saj. -
sequences: Një listë boshe që ruan sekuencat e paraqitjes numerike të fjalëve për çdo mostër teksti. -
for text in texts: kalon nëpër çdo mostër teksti në listën "tekste" (krijuar më herët). -
words = text.lower().split(): Konverton çdo mostër teksti në shkronja të vogla dhe e ndan atë në fjalë individuale, bazuar në hapësirën e bardhë. -
for word in words: Një lak i ndërthurur që përsëritet mbi secilën fjalë në listën "fjalë", e cila përmban fjalë të shënjuara nga mostrat aktuale të tekstit. -
if word not in word_index: Nëse fjala nuk është aktualisht e pranishme në fjalorin word_index, ajo i shtohet së bashku me një indeks unik, i cili merret duke shtuar 1 në gjatësinë aktuale të fjalorit. -
sequence. append (word_index[word]): Pas përcaktimit të indeksit të fjalës aktuale, ajo i shtohet listës "sekuencë". Kjo konverton çdo fjalë në mostrën e tekstit në indeksin e saj përkatës bazuar në fjalorin "word_index". -
sequence.append(sequence): Pasi të gjitha fjalët në mostrën e tekstit të konvertohen në indekse numerike dhe të ruhen në listën "sekuenca", kjo listë i shtohet listës "sekuenca".
Në përmbledhje, kodi i mësipërm shënjon të dhënat e tekstit duke konvertuar secilën fjalë në paraqitjen e saj numerike bazuar në fjalorin word_index , i cili harton fjalët në indekse unike. Ai krijon sekuenca të paraqitjeve numerike për çdo mostër teksti, të cilat mund të përdoren si të dhëna hyrëse për modelin.
Arkitektura Model
Arkitektura e një modeli të caktuar është rregullimi i shtresave, komponentëve dhe lidhjeve që përcaktojnë se si të dhënat rrjedhin nëpër të . Arkitektura e modelit ka një ndikim të rëndësishëm në shpejtësinë e trajnimit, performancën dhe aftësinë e përgjithësimit të modelit.
Pas përpunimit të të dhënave hyrëse, ne mund të përcaktojmë arkitekturën e modelit si në shembullin e mëposhtëm:
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
Në kodin e mësipërm, ne përdorim TensorFlow Keras, i cili është një API i rrjeteve nervore të nivelit të lartë, i ndërtuar për eksperimentim dhe prototip të shpejtë të modeleve të mësimit të thellë, duke thjeshtuar procesin e ndërtimit dhe përpilimit të modeleve të mësimit të makinerive.
-
tf. keras.Sequential(): Përcaktimi i një modeli sekuencial, i cili është një grumbull linear shtresash. Të dhënat rrjedhin nga shtresa e parë në të fundit, sipas renditjes. -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): Kjo shtresë përdoret për futjen e fjalëve, e cila i konverton fjalët në vektorë të dendur me madhësi fikse. Lent (word_index) + 1 specifikon madhësinë e fjalorit, 16 është dimensionaliteti i ngulitjes dhe input_length=max_length përcakton gjatësinë e hyrjes për çdo sekuencë. -
tf.keras.layers.LSTM(64): Kjo shtresë është një shtresë e kujtesës afatshkurtër (LSTM), e cila është një lloj rrjeti nervor periodik (RNN). Ai përpunon sekuencën e futjeve të fjalëve dhe mund të "kujtojë" modele ose varësi të rëndësishme në të dhëna. Ai ka 64 njësi, të cilat përcaktojnë dimensionalitetin e hapësirës së daljes. -
tf.keras.layers.Dense(3, activation='softmax'): Kjo është një shtresë e lidhur dendur me 3 njësi dhe një funksion aktivizimi softmax. Është shtresa dalëse e modelit, që prodhon një shpërndarje probabiliteti mbi tre klasat e mundshme (duke supozuar një problem klasifikimi me shumë klasa).


Përmbledhje
Në Learning Machine with TensorFlow, përpilimi i referohet procesit të konfigurimit të modelit për trajnim duke specifikuar tre komponentë kryesorë - Funksioni i Humbjes, Optimizuesi dhe Metrika.
Funksioni i humbjes : Mat gabimin midis parashikimeve të modelit dhe objektivave aktuale, duke ndihmuar në drejtimin e rregullimeve të modelit.
Optimizer : Rregullon parametrat e modelit për të minimizuar funksionin e humbjes, duke mundësuar të mësuarit efikas.
Metrikë : Ofron vlerësimin e performancës përtej humbjes, të tilla si saktësia ose saktësia, duke ndihmuar në vlerësimin e modelit.

Kodi i mëposhtëm mund të përdoret për të përpiluar modelin e analizës së ndjenjave:
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])Këtu,
loss='sparse_categorical_crossentropy': Një funksion humbjeje përdoret përgjithësisht për detyrat e klasifikimit nëse etiketat e synuara janë numra të plotë dhe prodhimi i modelit është një shpërndarje probabiliteti mbi klasa të shumta. Ai mat ndryshimin midis etiketimeve të vërteta dhe parashikimeve , duke synuar ta minimizojë atë gjatë stërvitjes.optimizer='adam': Adam është një algoritëm optimizimi që përshtat normën e të mësuarit në mënyrë dinamike gjatë trajnimit. Përdoret gjerësisht në praktikë për shkak të efikasitetit, qëndrueshmërisë dhe efektivitetit në një gamë të gjerë detyrash në krahasim me optimizuesit e tjerë.metrics = ['accuracy']: Saktësia është një metrikë e zakonshme që përdoret shpesh për të vlerësuar modelet e klasifikimit. Ai siguron një masë të drejtpërdrejtë të performancës së përgjithshme të modelit në detyrë, si përqindje e mostrave për të cilat parashikimet e modelit përputhen me etiketat e vërteta.

Trajnimi i Modelit
Tani që të dhënat hyrëse janë përpunuar dhe gati dhe arkitektura e modelit është përcaktuar gjithashtu, ne mund ta trajnojmë modelin duke përdorur metodën model.fit() .
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences: Të dhënat hyrëse për trajnimin e modelit, i cili përbëhet nga sekuenca të të njëjtave dimensione (mbushja do të diskutohet më vonë në tutorial).labels: Etiketat e synuara që korrespondojnë me të dhënat hyrëse (dmth. kategoritë e ndjenjave të caktuara për çdo mostër teksti)epochs=15: Një epokë është një kalim i plotë përmes të dhënave të plota të trajnimit gjatë procesit të trajnimit. Prandaj, në këtë program, modeli përsëritet mbi të dhënat e plota 15 herë gjatë trajnimit.
Kur numri i epokave rritet, ai potencialisht do të përmirësojë performancën pasi mëson modele më komplekse përmes mostrave të të dhënave. Megjithatë, nëse përdoren shumë epoka, modeli mund të mësojë përmendësh të dhënat e trajnimit duke çuar (që quhet "mbipërshtatje") në përgjithësim të dobët të të dhënave të reja. Koha e harxhuar për trajnim do të rritet gjithashtu me rritjen e numrit të epokave dhe anasjelltas.


verbose=1: Ky është një parametër për të kontrolluar se sa rezultat prodhon metoda e përshtatjes së modelit gjatë stërvitjes. Një vlerë prej 1 do të thotë se shiritat e përparimit do të shfaqen në tastierë ndërsa modeli trajnohet, 0 do të thotë pa dalje dhe 2 do të thotë një rresht për epokë. Meqenëse do të ishte mirë të shihnim saktësinë dhe vlerat e humbjes dhe kohën e marrë për çdo epokë, do ta vendosim në 1.
Bërja e parashikimeve
Pas përpilimit dhe trajnimit të modelit, ai më në fund mund të bëjë parashikime bazuar në të dhënat tona të mostrës, thjesht duke përdorur funksionin predict(). Megjithatë, ne duhet të fusim të dhëna hyrëse në mënyrë që të testojmë modelin dhe të marrim daljen. Për ta bërë këtë, ne duhet të futim disa deklarata teksti dhe më pas t'i kërkojmë modelit të parashikojë ndjenjën e të dhënave hyrëse.
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence) Këtu, test_texts ruan disa të dhëna hyrëse ndërsa lista test_sequences përdoret për të ruajtur të dhënat e testimit të tokenizuara, të cilat janë fjalë të ndara me hapësira të bardha pasi kthehen në shkronja të vogla. Por megjithatë, test_sequences nuk do të jenë në gjendje të veprojnë si të dhëna hyrëse për modelin.
Arsyeja është se shumë korniza të mësimit të thellë, duke përfshirë Tensorflow, zakonisht kërkojnë që të dhënat hyrëse të kenë një dimension uniform (që do të thotë se gjatësia e çdo sekuence duhet të jetë e barabartë), për të përpunuar grupe të dhënash në mënyrë efikase. Për ta arritur këtë, mund të përdorni teknika si mbushja, ku sekuencat zgjerohen për të përputhur gjatësinë e sekuencave më të gjata në grupin e të dhënave, duke përdorur një shenjë të veçantë si # ose 0 (0, në këtë shembull).
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)Në kodin e dhënë,
-
padded_test_sequences: Një listë boshe për të ruajtur sekuencat e mbushura që do të përdoren për të testuar modelin. -
for sequence in sequences: Kalon nëpër secilën sekuencë në listën "sekuenca". -
padded_sequence: Krijon një sekuencë të re të mbushur për çdo sekuencë, duke shkurtuar sekuencën origjinale në elementët e parë max_length për të siguruar qëndrueshmëri. Më pas, ne po e mbushim sekuencën me zero që të përputhet me gjatësinë_max nëse është më e shkurtër, duke i bërë në mënyrë efektive të gjitha sekuencat të njëjtën gjatësi. -
padded_test_sequences.append(): Shtoni një sekuencë të mbushur në listë që do të përdoret për testim. -
padded_sequences = np.array(): Konvertimi i listës së sekuencave të mbushura në një grup Numpy.


Tani, meqenëse të dhënat hyrëse janë gati për t'u përdorur, modeli më në fund mund të parashikojë ndjenjën e teksteve hyrëse.
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}") Në kodin e mësipërm, metoda model.predict() gjeneron parashikime për çdo sekuencë testimi, duke prodhuar një sërë probabilitetesh të parashikuara për secilën kategori të ndjenjave. Më pas ai përsëritet përmes secilit element test_texts dhe np.argmax(predictions[i]) kthen indeksin e probabilitetit më të lartë në grupin e probabiliteteve të parashikuara për mostrën e testit të i-të. Ky indeks korrespondon me kategorinë e ndjenjave të parashikuara me probabilitetin më të lartë të parashikuar për çdo kampion provë, që do të thotë se parashikimi më i mirë i bërë nxirret dhe tregohet si rezultati kryesor.
Shënime speciale *:* np.argmax() është një funksion NumPy që gjen indeksin e vlerës maksimale në një grup. Në këtë kontekst, np.argmax(predictions[i]) ndihmon në përcaktimin e kategorisë së ndjenjave me probabilitetin më të lartë të parashikuar për çdo mostër testimi.
Programi tani është gati për të ekzekutuar. Pas përpilimit dhe trajnimit të modelit, Modeli i Mësimit të Makinerisë do të printojë parashikimet e tij për të dhënat hyrëse.


Në daljen e modelit, ne mund t'i shohim vlerat si "Saktësi" dhe "Humbje" për çdo epokë. Siç u përmend më parë, Saktësia është përqindja e parashikimeve të sakta nga parashikimet totale. Saktësia më e lartë është më e mirë. Nëse saktësia është 1.0, që do të thotë 100%, do të thotë se modeli ka bërë parashikime të sakta në të gjitha rastet. Në mënyrë të ngjashme, 0.5 do të thotë se modeli ka bërë parashikime të sakta gjysmën e kohës, 0.25 do të thotë parashikim i saktë tremujori i kohës, e kështu me radhë.
Humbja , nga ana tjetër, tregon se sa keq përputhen parashikimet e modelit me vlerat e vërteta. Vlera më e vogël e humbjes do të thotë një model më i mirë me më pak gabime, me vlerën 0 që është vlera perfekte e humbjes pasi kjo do të thotë se nuk janë bërë gabime.
Megjithatë, ne nuk mund të përcaktojmë saktësinë e përgjithshme dhe humbjen e modelit me të dhënat e mësipërme të treguara për secilën epokë. Për ta bërë këtë, ne mund të vlerësojmë modelin duke përdorur metodën evaluimit() dhe të printojmë saktësinë dhe humbjen e tij.
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)Prodhimi:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543Prandaj, në këtë model, vlera e Humbjes është 0.6483 që do të thotë se Modeli ka bërë disa gabime. Saktësia e modelit është rreth 70%, që do të thotë se parashikimet e bëra nga modeli janë të sakta më shumë se gjysmën e rasteve. Në përgjithësi, ky model mund të konsiderohet një model “pak i mirë”; megjithatë, ju lutemi vini re se vlerat "e mira" të humbjes dhe saktësisë varen shumë nga lloji i modelit, madhësia e grupit të të dhënave dhe qëllimi i një modeli të caktuar të mësimit të makinës.
Dhe po, ne mund dhe duhet të përmirësojmë matjet e mësipërme të modelit duke rregulluar mirë proceset dhe grupe më të mira të të dhënave të mostrave. Megjithatë, për hir të këtij tutoriali, le të ndalemi nga këtu. Nëse dëshironi një pjesë të dytë të këtij tutoriali, ju lutem më njoftoni!
Përmbledhje
Në këtë tutorial, ne ndërtuam një Model të Mësimit të Makinerisë TensorFlow me aftësinë për të parashikuar ndjenjën e një teksti të caktuar, pas analizimit të grupit të të dhënave të mostrës.
Kodi i plotë dhe skedari CSV i mostrës mund të shkarkohen dhe të shihen në depon e GitHub - GitHub - Buzzpy/Tensorflow-ML-Model




