

















































Jan 01, 1970
Comment j'ai construit un système d'alerte de plantes d'intérieur avec ksqlDB sur Apache Kafka par@thedanicafine
5,647 lectures
Comment j'ai construit un système d'alerte de plantes d'intérieur avec ksqlDB sur Apache Kafka
Trop long; Pour lire
Rejoignez-moi alors que je plonge tête première dans mon premier projet de matériel IoT où j'utilise un Raspberry Pi, Apache Kafka et Telegram pour construire un système pour m'alerter lorsque mes plantes d'intérieur doivent être arrosées !En 2020, tant de gens ont choisi des passe-temps pandémiques – des choses dans lesquelles ils pouvaient se lancer à fond alors qu'ils étaient limités par les fermetures. J'ai choisi des plantes d'intérieur.
Avant la pandémie, j'avais déjà ce qui équivalait à une petite crèche dans ma maison. Honnêtement, même alors, c'était beaucoup de travail de prendre soin de chaque plante chaque jour. Voir lesquels d'entre eux avaient besoin d'être arrosés, s'assurer qu'ils reçoivent tous la bonne quantité de soleil, leur parler… #justHouseplantThings.
Avoir plus de temps à la maison signifiait que je pouvais investir davantage dans mes plantes. Et je l'ai fait - mon temps, mes efforts et mon argent. Il y a quelques dizaines de plantes d'intérieur chez moi; ils ont tous des noms, des personnalités (du moins je le pense), et certains ont même des yeux écarquillés. Cela, bien sûr, était bien pendant que j'étais à la maison toute la journée, mais, alors que la vie revenait lentement à la normale, je me suis retrouvée dans une position difficile : je n'avais plus tout le temps du monde pour suivre mes plantes. J'avais besoin d'une solution. Il devait y avoir une meilleure façon de surveiller mes plantes que de les vérifier manuellement chaque jour.
Entrez Apache Kafka®. Eh bien, vraiment, entrez dans mon désir de choisir un autre passe-temps : les projets de matériel.
J'ai toujours voulu une excuse pour construire un projet à l'aide d'un Raspberry Pi, et je savais que c'était ma chance. Je construirais un système qui pourrait surveiller mes plantes pour m'alerter uniquement lorsqu'elles ont besoin d'attention et pas un instant plus tard. Et j'utiliserais Kafka comme colonne vertébrale.
Cela s'est avéré être un projet très utile. Cela a résolu un problème très réel que j'avais et m'a donné une chance de combiner mon obsession des plantes d'intérieur avec mon désir ardent d'enfin utiliser Kafka à la maison. Tout cela a été soigneusement résumé dans un projet matériel simple et accessible que n'importe qui peut implémenter par lui-même.
Si vous êtes comme moi et que vous avez un problème de plante d'intérieur qui ne peut être résolu qu'en automatisant votre maison, ou même si vous n'êtes pas du tout comme moi mais que vous voulez quand même un projet sympa à approfondir, cet article de blog est pour vous .
Retroussons nos manches et salissons nos mains !
Planter les graines
Tout d'abord, je me suis assis pour comprendre ce que je voulais réaliser avec ce projet. Pour la première phase du système, il serait très utile de pouvoir surveiller les niveaux d'humidité de mes plantes et de recevoir des alertes à leur sujet. Après tout, la partie la plus longue de l'entretien de mes plantes consistait à décider lesquelles devaient être entretenues. Si ce système pouvait gérer ce processus de prise de décision, je gagnerais une tonne de temps !
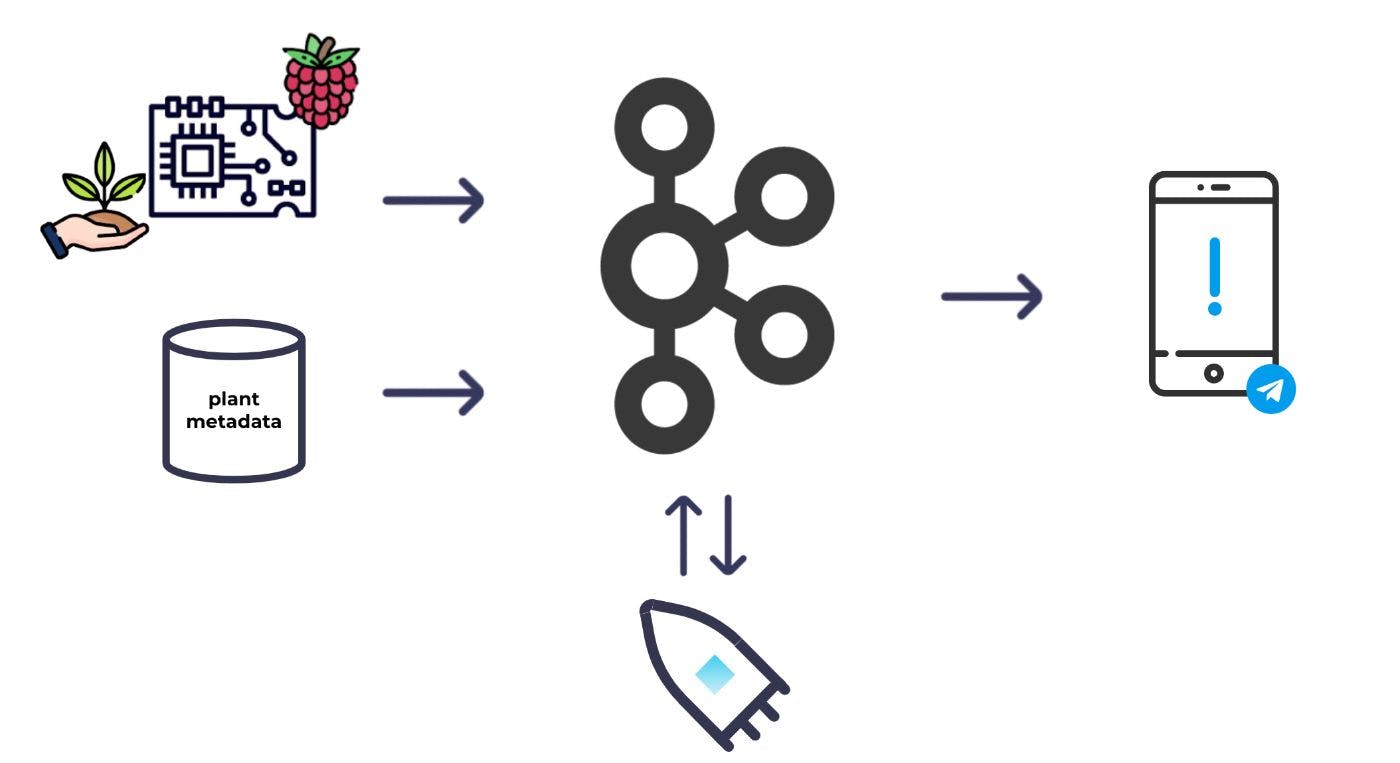
À un niveau élevé, voici le système de base que j'ai envisagé :
Je placerais des capteurs d'humidité dans le sol et je les raccorderais à un Raspberry Pi ; Je pourrais alors prendre régulièrement des mesures d'humidité et les jeter dans Kafka. En plus des relevés d'humidité, j'avais également besoin de métadonnées pour chaque plante afin de décider quelles plantes doivent être arrosées. Je produirais également les métadonnées dans Kafka. Avec les deux ensembles de données dans Kafka, je pourrais ensuite utiliser le traitement de flux pour combiner et enrichir les ensembles de données les uns avec les autres et calculer quelles plantes doivent être arrosées. A partir de là, je pourrais déclencher une alerte.
Avec un ensemble d'exigences de base établies, j'ai plongé dans la phase de matériel et d'assemblage.
Prendre la tige des choses
Comme beaucoup d'ingénieurs qui se respectent, j'ai lancé l'étape du matériel avec une tonne de googler. Je savais que toutes les pièces existaient pour faire de ce projet un succès, mais comme c'était la première fois que je travaillais avec des composants physiques, je voulais m'assurer de savoir exactement dans quoi je m'embarquais.
L'objectif principal du système de surveillance était de me dire quand les plantes devaient être arrosées, donc évidemment, j'avais besoin d'une sorte de capteur d'humidité. J'ai appris que les capteurs d'humidité du sol se présentent sous différentes formes et tailles, sont disponibles sous forme de composants analogiques ou numériques et diffèrent dans la manière dont ils mesurent l'humidité. Au final, j'ai opté pour ces capteurs capacitifs I2C. Ils semblaient être une excellente option pour quelqu'un qui débutait avec du matériel : en tant que capteurs capacitifs, ils duraient plus longtemps que les capteurs résistifs, ils ne nécessitaient aucune conversion analogique-numérique et ils étaient plus ou moins plug-and- jouer. De plus, ils ont offert des mesures de température gratuitement.
Un aparté : Pour les curieux, I2C signifie Inter-Integrated Circuit. Chacun de ces capteurs communique via une adresse unique ; donc, pour récupérer les données de chaque capteur, je dois définir et garder une trace de l'adresse unique de chaque capteur que j'utilise - quelque chose à garder à l'esprit pour plus tard.
Décider des capteurs était la plus grande partie de ma configuration physique. Il ne restait plus qu'à mettre la main sur le matériel pour mettre la main sur un Raspberry Pi et quelques équipements. Ensuite, j'étais libre de commencer à construire le système.
J'ai utilisé les composants suivants :
- Raspberry Pi 4 Modèle B
- PCB de planche à pain demi-taille
- Capteurs capacitifs d'humidité du sol
- Kit de connecteur de pas JST
- fil ruban 4 brins
- Pinces à sertir, pinces à dénuder, soudure, fer à souder (que j'ai tous trouvés commodément dans mon garage)
Du sol vers le haut…
Bien que je voulais que ce projet soit facile et convivial pour les débutants, je voulais aussi me mettre au défi de faire autant de câblage et de soudure que possible. Pour honorer ceux qui m'ont précédé , j'ai entrepris ce voyage d'assemblage avec quelques fils, une sertisseuse et un rêve. La première étape consistait à préparer suffisamment de fil ruban pour connecter quatre capteurs à la planche à pain et également pour connecter la planche à pain à mon Raspberry Pi. Pour permettre l'espacement entre les composants dans la configuration, j'ai préparé des longueurs de 24 pouces. Chaque fil devait être dénudé, serti et branché soit sur un connecteur JST (pour les fils reliant les capteurs à la planche à pain) soit sur une prise femelle (pour se connecter au Raspberry Pi lui-même). Mais, bien sûr, si vous cherchez à gagner du temps, des efforts et des larmes, je vous recommande de ne pas sertir vos propres fils et d'acheter à la place des fils préparés à l'avance.
Un aparté : étant donné le nombre de plantes d'intérieur que je possède, quatre peuvent sembler être un nombre arbitrairement faible de capteurs à utiliser dans ma configuration de surveillance. Comme indiqué précédemment, ces capteurs étant des dispositifs I2C, toute information qu'ils communiquent sera envoyée à l'aide d'une adresse unique. Cela dit, les capteurs d'humidité du sol que j'ai achetés sont tous livrés avec la même adresse par défaut, ce qui est problématique pour des configurations comme celle-ci où vous souhaitez utiliser plusieurs du même appareil. Il existe deux façons principales de contourner ce problème. La première option dépend de l'appareil lui-même. Mon capteur particulier avait deux cavaliers d'adresse I2C à l'arrière, et la soudure de n'importe quelle combinaison de ceux-ci signifiait que je pouvais changer l'adresse I2C pour aller de 0x36 à 0x39. Au total, je pourrais avoir quatre adresses uniques, d'où les quatre capteurs que j'utilise dans la configuration finale. Si les appareils ne disposent pas d'un moyen physique pour changer d'adresse, la deuxième option consiste à rediriger les informations et à configurer des adresses proxy à l'aide d'un multiplex. Étant donné que je suis nouveau dans le domaine du matériel, j'ai senti que cela sortait du cadre de ce projet particulier.
Après avoir préparé les fils pour connecter les capteurs au Raspberry Pi, j'ai confirmé que tout était correctement configuré en utilisant un script Python de test pour collecter les lectures d'un seul capteur. Pour plus de sécurité, j'ai testé les trois capteurs restants de la même manière. Et c'est au cours de cette étape que j'ai appris de première main comment les fils croisés affectent les composants électroniques… et à quel point ces problèmes sont difficiles à déboguer.
Avec le câblage enfin en état de marche, j'ai pu connecter tous les capteurs au Raspberry Pi. Tous les capteurs devaient être connectés aux mêmes broches (GND, 3V3, SDA et SCL) sur le Raspberry Pi. Chaque capteur a une adresse I2C unique, donc, bien qu'ils communiquent tous sur les mêmes fils, je peux toujours obtenir des données de capteurs spécifiques en utilisant leur adresse. Tout ce que j'avais à faire était de câbler chaque capteur à la planche à pain, puis de connecter la planche à pain au Raspberry Pi. Pour ce faire, j'ai utilisé un peu de fil restant et connecté les colonnes de la planche à pain à l'aide de soudure. J'ai ensuite soudé les connecteurs JST directement sur la planche à pain afin de pouvoir facilement brancher les capteurs.
Après avoir connecté la planche à pain au Raspberry Pi, inséré les capteurs dans quatre usines et confirmé via un script de test que je pouvais lire les données de tous les capteurs, j'ai pu commencer à travailler sur la production des données dans Kafka.
Données sur le vrai thym
Avec la configuration du Raspberry Pi et tous les capteurs d'humidité fonctionnant comme prévu, il était temps d'intégrer Kafka dans le mélange pour commencer à diffuser des données.
Comme vous vous en doutez, j'avais besoin d'un cluster Kafka avant de pouvoir écrire des données dans Kafka. Voulant rendre le composant logiciel de ce projet aussi léger et facile à configurer que possible, j'ai choisi d'utiliser Confluent Cloud comme fournisseur Kafka. Cela signifiait que je n'avais pas besoin de configurer ou de gérer d'infrastructure et que mon cluster Kafka était prêt quelques minutes après sa configuration.
Il convient également de noter pourquoi j'ai choisi d'utiliser Kafka pour ce projet, d'autant plus que MQTT est plus ou moins la norme de facto pour le streaming de données IoT à partir de capteurs. Kafka et MQTT sont tous deux conçus pour la messagerie de style pub/sous, ils sont donc similaires à cet égard. Mais si vous envisagez de créer un projet de streaming de données tel que celui-ci, MQTT échouera. Vous avez besoin d'une autre technologie telle que Kafka pour gérer le traitement des flux, la persistance des données et toute intégration en aval. L'essentiel est que MQTT et Kafka fonctionnent très bien ensemble . En plus de Kafka, j'aurais certainement pu utiliser MQTT pour le composant IoT de mon projet. Au lieu de cela, j'ai décidé de travailler directement avec le producteur Python sur le Raspberry Pi. Cela dit, si vous souhaitez utiliser MQTT et Kafka pour tout projet inspiré de l'IoT, soyez assuré que vous pouvez toujours transférer vos données MQTT dans Kafka à l'aide du connecteur source MQTT Kafka .
Désherber à travers les données
Avant de mettre des données en mouvement, j'ai pris du recul pour décider comment je voulais structurer les messages sur mon sujet Kafka. Surtout pour les projets de piratage comme celui-ci, il est facile de commencer à envoyer des données dans un sujet Kafka sans souci pour le monde, mais il est important de savoir comment vous allez structurer vos données sur les sujets, quelle clé vous utiliserez et les données types dans les champs.
Commençons donc par les sujets. À quoi ressembleront-ils ? Les capteurs avaient la capacité de capturer l'humidité et la température - ces lectures devaient-elles être écrites sur un seul sujet ou plusieurs ? Étant donné que les lectures d'humidité et de température étaient capturées à partir du capteur d'une plante en même temps, je les ai stockées ensemble dans le même message Kafka. Ensemble, ces deux éléments d'information constituaient une lecture de la plante aux fins de ce projet. Tout irait dans le même sujet de lecture.
En plus des données du capteur, j'avais besoin d'un sujet pour stocker les métadonnées de la plante d'intérieur, y compris le type de plante que le capteur surveille et ses limites de température et d'humidité. Ces informations seraient utilisées lors de l'étape de traitement des données pour déterminer quand une lecture devrait déclencher une alerte.
J'ai créé deux sujets : houseplants-readings et houseplants-metadata . Combien de partitions dois-je utiliser ? Pour les deux sujets, j'ai décidé d'utiliser le nombre de partitions par défaut dans Confluent Cloud qui, au moment de la rédaction, est de six. Était-ce le bon numéro ? Eh bien, oui et non. Dans ce cas, en raison du faible volume de données que je traite, six partitions par sujet pourraient être exagérées, mais dans le cas où j'étendrais ce projet à plus d'usines plus tard, ce serait bien d'avoir six partitions .
Outre les partitions, un autre paramètre de configuration important à prendre en compte est le compactage des journaux que j'ai activé sur le sujet des plantes d'intérieur. Contrairement au flux d'événements "lectures", le sujet "métadonnées" contient des données de référence, ou métadonnées. En le conservant dans un sujet compacté, vous vous assurez que les données ne vieilliront jamais et vous aurez toujours accès à la dernière valeur connue pour une clé donnée (la clé, si vous vous en souvenez, étant un identifiant unique pour chaque plante d'intérieur).
Sur la base de ce qui précède, j'ai écrit deux schémas Avro pour les lectures et les métadonnées de la plante d'intérieur (abrégé ici pour plus de lisibilité).
Schéma des lectures
{ "doc": "Houseplant reading taken from sensors.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"}, {"name": "moisture", "type": "float"}, {"name": "temperature", "type": "float"} ], "name": "reading", "namespace": "com.houseplants", "type": "record" }Schéma de métadonnées de la plante d'intérieur
{ "doc": "Houseplant metadata.", "fields": [ {"name": "plant_id", "type": "int"}, {"name": "scientific_name", "type": "string"}, {"name": "common_name", "type": "string"}, {"name": "given_name", "type": "string"}, {"name": "temperature_threshold_low", "type": "float"}, {"name": "temperature_threshold_high", "type": "float"}, {"name": "moisture_threshold_low", "type": "float"}, {"name": "moisture_threshold_high", "type": "float"} ], "name": "houseplant", "namespace": "com.houseplants", "type": "record" }
Si vous avez déjà utilisé Kafka, vous savez qu'avoir des sujets et savoir à quoi ressemblent les valeurs de votre message n'est que la première étape. Il est tout aussi important de savoir quelle sera la clé de chaque message. Pour les lectures et les métadonnées, je me suis demandé ce que serait une instance de chacun de ces ensembles de données, car c'est l'instance d'entité qui devrait constituer la base d'une clé dans Kafka. Étant donné que les lectures sont prises par usine et que les métadonnées sont attribuées par usine , une instance d'entité des deux ensembles de données était une usine individuelle. J'ai décidé que la clé logique des deux sujets serait basée sur la plante. J'attribuerais un identifiant numérique à chaque plante et ce numéro serait la clé des messages de lecture et des messages de métadonnées.
Donc, avec le sentiment de satisfaction légèrement suffisant qui vient de savoir que je procédais de la bonne manière, j'ai pu porter mon attention sur la diffusion des données de mes capteurs dans les sujets Kafka.
Cultiver les messages
Je voulais commencer à envoyer les données de mes capteurs à Kafka. La première étape consistait à installer la bibliothèque Python confluent-kafka sur le Raspberry Pi. À partir de là, j'ai écrit un script Python pour capturer les lectures de mes capteurs et produire les données dans Kafka.
Le croiriez-vous si je vous disais que c'était si simple ? Avec seulement quelques lignes de code, mes données de capteur étaient écrites et conservées dans un sujet Kafka pour une utilisation dans l'analyse en aval. J'ai encore un peu le vertige rien que d'y penser.
Avec les lectures de capteurs dans Kafka, j'avais maintenant besoin des métadonnées de la plante d'intérieur pour effectuer toute sorte d'analyse en aval. Dans les pipelines de données typiques, ce type de données résiderait dans une base de données relationnelle ou dans un autre magasin de données et serait ingéré à l'aide de Kafka Connect et des nombreux connecteurs disponibles.
Plutôt que de créer ma propre base de données externe, j'ai décidé d'utiliser Kafka comme couche de stockage persistante pour mes métadonnées. Avec des métadonnées pour seulement une poignée de plantes, j'ai écrit manuellement les données directement dans Kafka à l'aide d'un autre script Python .
La racine du problème
Mes données sont dans Kafka ; maintenant il est temps de vraiment me salir les mains. Mais d'abord, revenons sur ce que je voulais réaliser avec ce projet. L'objectif général est d'envoyer une alerte lorsque mes plantes ont des lectures d'humidité faibles qui indiquent qu'elles doivent être arrosées. Je peux utiliser le traitement de flux pour enrichir les données de lecture avec les métadonnées, puis calculer un nouveau flux de données pour piloter mes alertes.
J'ai choisi d'utiliser ksqlDB pour l'étape de traitement des données de ce pipeline afin de pouvoir traiter les données avec un minimum de codage. En conjonction avec Confluent Cloud, ksqlDB est facile à configurer et à utiliser : il vous suffit de provisionner un contexte d'application et d'écrire du SQL simple pour commencer à charger et à traiter vos données.
Définition des données d'entrée
Avant de pouvoir commencer à traiter les données, je devais déclarer mes ensembles de données dans l'application ksqlDB afin qu'ils soient disponibles pour travailler avec. Pour ce faire, j'ai d'abord dû décider lequel des deux objets ksqlDB de première classe mes données devaient être représentées sous la forme - TABLE ou STREAM -, puis utiliser une instruction CREATE pour pointer vers les rubriques Kafka existantes.
Les données de lecture de la plante d'intérieur sont représentées dans ksqlDB sous la forme d'un STREAM - en gros exactement la même chose qu'un sujet Kafka (une série d'événements immuables en ajout uniquement) mais également avec un schéma. Plutôt commodément, j'avais déjà conçu et déclaré le schéma précédemment, et ksqlDB peut le récupérer directement à partir du Schema Registry :
CREATE STREAM houseplant_readings ( id STRING KEY ) WITH ( kafka_topic='houseplant-readings', format='AVRO', partitions=4 );
Avec le flux créé sur le sujet Kafka, nous pouvons utiliser le SQL standard pour l'interroger et le filtrer afin d'explorer les données à l'aide d'une simple instruction comme celle-ci :
SELECT plant_id, moisture FROM HOUSEPLANT_READINGS EMIT CHANGES;
Les métadonnées de la plante d'intérieur ont besoin d'un peu plus de considération. Bien qu'il soit stocké en tant que sujet Kafka (tout comme les données de lecture), il s'agit logiquement d'un type de données différent : son état. Pour chaque plante, elle a un nom, elle a un emplacement, etc. Nous le stockons dans un sujet Kafka compacté et le représentons dans ksqlDB en tant que TABLE . Un tableau, comme dans un SGBDR classique, nous indique l'état actuel d'une clé donnée. Notez que bien que ksqlDB récupère le schéma lui-même ici à partir du Schema Registry, nous devons déclarer explicitement quel champ représente la clé primaire de la table.
CREATE TABLE houseplant_metadata ( id INTEGER PRIMARY KEY ) WITH ( kafka_topic='houseplant-metadata', format='AVRO', partitions=4 );Enrichir les données
Avec les deux ensembles de données enregistrés avec mon application ksqlDB, l'étape suivante consiste à enrichir les houseplant_readings avec les métadonnées contenues dans la table houseplants . Cela crée un nouveau flux (soutenu par un sujet Kafka) avec à la fois la lecture et les métadonnées de la plante associée :
La requête d'enrichissement ressemblerait à ceci :
CREATE STREAM houseplant_readings_enriched WITH ( kafka_topic='houseplant-readings-enriched', format='AVRO', partitions=4 ) AS SELECT r.id AS plant_id, r.timestamp AS ts, r.moisture AS moisture, r.temperature AS temperature, h.scientific_name AS scientific_name, h.common_name AS common_name, h.given_name AS given_name, h.temperature_low AS temperature_low, h.temperature_high AS temperature_high, h.moisture_low AS moisture_low, h.moisture_high AS moisture_high FROM houseplant_readings AS r LEFT OUTER JOIN houseplants AS h ON houseplant_readings.id = houseplants.id PARTITION BY r.id EMIT CHANGES;
Et le résultat de cette requête ressemblerait à ceci :
Créer des alertes sur un flux d'événements
En repensant au début de cet article, vous vous souviendrez que le but de tout cela était de me dire quand une plante aurait besoin d'être arrosée. Nous avons un flux de lectures d'humidité (et de température), et nous avons un tableau qui nous indique le seuil auquel le niveau d'humidité de chaque plante peut indiquer qu'elle a besoin d'être arrosée. Mais comment puis-je déterminer quand envoyer une alerte de faible humidité ? Et à quelle fréquence je les envoie ?
En essayant de répondre à ces questions, j'ai remarqué certaines choses sur mes capteurs et les données qu'ils généraient. Tout d'abord, je capture des données à des intervalles de cinq secondes. Si je devais envoyer une alerte pour chaque lecture de faible humidité, j'inonderais mon téléphone d'alertes - ce n'est pas bon. Je préfère recevoir une alerte au plus une fois par heure. La deuxième chose que j'ai réalisée en regardant mes données était que les capteurs n'étaient pas parfaits - je voyais régulièrement de fausses lectures basses ou fausses hautes, bien que la tendance générale au fil du temps était que le niveau d'humidité d'une plante diminuait.
En combinant ces deux observations, j'ai décidé qu'au cours d'une période donnée d'une heure, il serait probablement suffisant d'envoyer une alerte si je voyais 20 minutes de lectures de faible humidité. À une lecture toutes les 5 secondes, cela fait 720 lectures par heure, et… en faisant un peu de calcul ici, cela signifie que j'aurais besoin de voir 240 lectures basses sur une période d'une heure avant d'envoyer une alerte.
Donc, ce que nous allons faire maintenant, c'est créer un nouveau flux qui contiendra au plus un événement par plante par période d'une heure. J'y suis parvenu en écrivant la requête suivante :
CREATE TABLE houseplant_low_readings WITH ( kafka_topic='houseplant-low-readings', format='AVRO', partitions=4 ) AS SELECT plant_id, given_name, common_name, scientific_name, CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message, COUNT(*) AS low_reading_count FROM houseplant_readings_enriched WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES) WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240 EMIT FINAL;
Tout d'abord, vous remarquerez l' agrégation fenêtrée . Cette requête fonctionne sur des fenêtres d'une heure sans chevauchement, ce qui me permet d'agréger les données par identifiant de plante dans une fenêtre donnée. Assez simple.
Je filtre et compte spécifiquement les lignes dans le flux de lectures enrichies où la valeur de lecture d'humidité est inférieure au seuil d'humidité bas pour cette plante. Si ce nombre est d'au moins 240, j'afficherai un résultat qui constituera la base d'une alerte.
Mais vous vous demandez peut-être pourquoi le résultat de cette requête se trouve dans une table. Eh bien, comme nous le savons, les flux représentent un historique plus ou moins complet d'une entité de données, tandis que les tableaux reflètent la valeur la plus à jour pour une clé donnée. Il est important de se rappeler que cette requête est en fait une application de streaming avec état sous les couvertures. Au fur et à mesure que les messages transitent sur le flux de données enrichi sous-jacent, si ce message particulier répond à l'exigence de filtre, nous incrémentons le nombre de lectures faibles pour cet ID d'usine dans la fenêtre d'une heure et en gardons une trace dans un état. Ce qui m'importe vraiment dans cette requête, cependant, c'est le résultat final de l'agrégation, à savoir si le nombre de lectures basses est supérieur à 240 pour une clé donnée. Je veux un tableau.
Un aparté : vous remarquerez que la dernière ligne de cette instruction est "EMIT FINAL". Cette phrase signifie que, plutôt que de générer potentiellement un résultat à chaque fois qu'une nouvelle ligne passe par l'application de streaming, j'attendrai que la fenêtre se soit fermée avant qu'un résultat ne soit émis.
Le résultat de cette requête est que, pour un ID d'usine donné dans une fenêtre spécifique d'une heure, je produirai au plus un message d'alerte, comme je le souhaitais.
Ramification
À ce stade, j'avais un sujet Kafka rempli par ksqlDB contenant un message lorsqu'une plante a un niveau d'humidité bas de manière appropriée et constante. Mais comment puis-je réellement extraire ces données de Kafka ? Le plus pratique pour moi serait de recevoir ces informations directement sur mon téléphone.
Je n'étais pas sur le point de réinventer la roue ici, alors j'ai profité de ce billet de blog qui décrit l'utilisation d'un bot Telegram pour lire les messages d'un sujet Kafka et envoyer des alertes à un téléphone. En suivant le processus décrit par le blog, j'ai créé un bot Telegram et entamé une conversation avec ce bot sur mon téléphone, en notant l'identifiant unique de cette conversation ainsi que la clé API de mon bot. Avec ces informations, je pourrais utiliser l'API de chat Telegram pour envoyer des messages de mon bot à mon téléphone.
C'est bien beau, mais comment envoyer mes alertes de Kafka à mon bot Telegram ? Je pourrais invoquer l'envoi de messages en écrivant un consommateur sur mesure qui consommerait les alertes du sujet Kafka et enverrait manuellement chaque message via l'API de chat Telegram. Mais cela ressemble à du travail supplémentaire. Au lieu de cela, j'ai décidé d'utiliser le connecteur HTTP Sink entièrement géré pour faire la même chose, mais sans écrire de code supplémentaire de ma part.
En quelques minutes, mon Telegram Bot était prêt à l'action, et j'ai eu une conversation privée ouverte entre moi et le bot. À l'aide de l'ID de chat, je pouvais désormais utiliser le connecteur HTTP Sink entièrement géré sur Confluent Cloud pour envoyer des messages directement sur mon téléphone.
La configuration complète ressemblait à ceci :
{ "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "config": { "topics": "houseplant-low-readings", "input.data.format": "AVRO", "connector.class": "HttpSink", "name": "HttpSinkConnector_Houseplants_Telegram_Bot", "kafka.auth.mode": "KAFKA_API_KEY", "http.api.url": "https://api.telegram.org/**********/sendMessage", "request.method": "POST", "headers": "Content-Type: application/json", "request.body.format": "string", "batch.max.size": "1", "batch.prefix": "{\"chat_id\":\"********\",", "batch.suffix": "}", "regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*", "regex.replacements": "\"text\":\"$1\"", "regex.separator": "~", "tasks.max": "1" } }
Quelques jours après le lancement du connecteur, j'ai reçu un message très utile m'informant que ma plante avait besoin d'être arrosée. Succès!
Tourner une nouvelle page
Cela fait environ un an que j'ai terminé la phase initiale de ce projet. Pendant ce temps, je suis heureux d'annoncer que toutes les plantes que je surveille sont heureuses et en bonne santé ! Je n'ai plus besoin de passer plus de temps à les vérifier et je peux compter exclusivement sur les alertes générées par mon pipeline de données en continu. À quel point cela est cool?
Si le processus de construction de ce projet vous a intrigué, je vous encourage à vous lancer dans votre propre pipeline de données en continu. Que vous soyez un utilisateur chevronné de Kafka qui souhaite vous mettre au défi de créer et d'intégrer des pipelines en temps réel dans votre propre vie, ou quelqu'un qui découvre complètement Kafka, je suis ici pour vous dire que ce type de projets est fait pour vous .
Également publié ici.
L O A D I N G
. . . comments & more!
. . . comments & more!



