






















LangChainista on nopeasti tullut kehys rakentaa tehokkaita sovelluksia, jotka hyödyntävät suuria kielimalleja (LLM). Vaikka LLM: t ovat erinomaisia ihmisen kielen ymmärtämisessä, SQL-tietokannoissa lukittujen rakenteellisten tietojen valtava määrä vaatii yleensä erikoistunutta kyselytietoa. Tämä herättää keskeisen kysymyksen: miten voimme antaa enemmän käyttäjiä vuorovaikutukseen tietokantojen, kuten MySQL: n, kanssa yksinkertaisella, luonnollisella kielellä?
Tämä artikkeli kertoo käytännön matkastani LangChainilla rakentaakseni täsmälleen sen – luonnollisen kielen käyttöliittymän, joka kykenee kyselemään MySQL-tietokantaa. Jaa vaiheet, jotka liittyvät järjestelmän asentamiseen Dockerin avulla, väistämättömät esteet (mukaan lukien LLM-tunnisteen rajojen hallinta, arkaluonteisten tietojen suojaaminen ja epäselvien pyyntöjen käsittely) ja monivaiheiset, monivaiheiset LLM-ratkaisut, joita olen kehittänyt.
Koko Python-koodi, joka toteuttaa tässä käsitellyn luonnollisen kielen kyselytyökalun, luotiin AI-mallien avulla, lähinnä ChatGPT: n ja Gemini: n avulla. Minun roolini oli määritellä vaatimukset, rakentaa kehotukset, tarkastella ja arvioida luotua koodia toiminnallisuuden ja mahdollisten ongelmien suhteen, ohjata AI: ta tarvittavien tarkistusten kautta, integroida eri komponentit ja suorittaa kriittiset testaus- ja vianmääritysvaiheet.
Step 1: Establishing the Foundation with Docker
- on
- Tavoitteena on luoda vakaa, eristetty monisäiliöympäristö. on
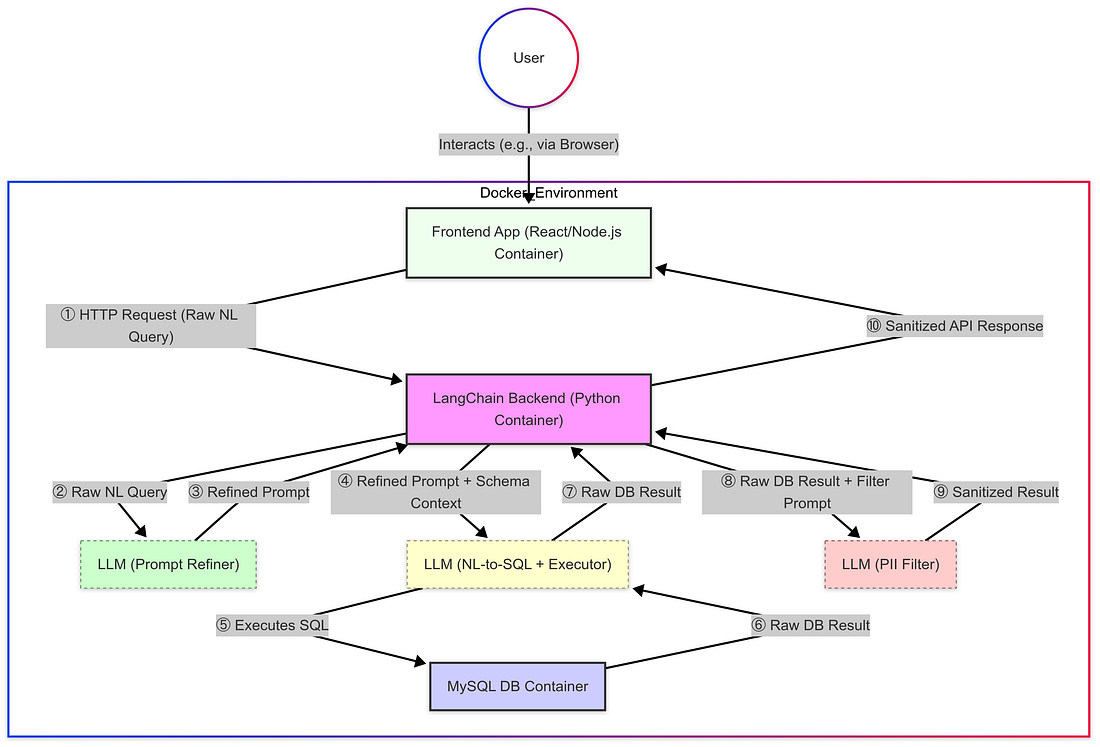
- Menetelmä: Ensimmäinen käytännöllinen askel oli luoda luotettava ja toistettava ympäristö Dockerin avulla. Arkkitehtuurissa oli mukana kolme erillistä konttia: yksi, joka suoritti Frontend-sovelluksen (React/Node.js), yksi Backend-palvelulle (Python with LangChain) ja toinen, joka oli omistettu MySQL-tietokannan instanssille. on
- Asennustiedot: Dockerin käyttäminen antoi puhtaan tason. AI:n hyödyntäminen auttoi nopeuttamaan Dockerfiles- ja docker-compose.yml-tiedostojen luomista, joita tarvitaan näiden kolmen palvelun ja niiden riippuvuuksien (kuten Python, LangChain, Node.js, MySQL-liitäntä) määrittelemiseen. Kriittinen konfigurointi sisälsi Docker-verkkojen luomisen välttämättömän konttien välisen viestinnän (esim. Frontendin puhumisen Backendille) ja tietokannan luottamuksellisten tietojen turvallisen käsittelyn käyttämällä ympäristömuuttujia. on
- Tulos ja siirtyminen: Kun konttorit ovat käynnissä, ne voivat kommunikoida asianmukaisesti ja tarjota tarvittavan infrastruktuurin. Tämän säätiön perustamisen myötä seuraavat vaiheet keskittyvät erityisesti arkkitehtuurisuunnitteluun ja haasteisiin, joita Backend Python -palvelussa esiintyy, koska tämä on paikka, jossa ydin LangChain-logiikka, LLM-orkestrasiointi ja tietojenkäsittelyputki toteutettiin. on


Step 2: First Queries and the Schema Size Challenge
- on
- Alkuperäinen menestys: Containerisoitu asennus toimi, mikä mahdollisti onnistuneen luonnollisen kielen kyselyt tietokantaan. Yksinkertaiset pyynnöt antoivat oikean kyselylogiikan ja tiedot LangChainin ja ensisijaisen LLM: n kautta. on
- Haaste: Token-rajoitukset: Kuitenkin suuri pullonkaula ilmestyi nopeasti: API-virheet johtuen token-rajojen ylittymisestä. Tämä tapahtui, koska LLM: lle annettu konteksti sisältää usein tietokantajärjestelmän yksityiskohtia (taulukko / sarakkeen nimet, tyypit), ja satojen taulukoiden kanssa tämä järjestelmätieto teki pyynnöt liian suuriksi LLM: n rajoille. on
- Workaround: Subsetting: Välitön ratkaisu oli rajoittaa LLM: lle toimitettuja kaavatietoja, ehkä harkitsemalla vain pieniä, manuaalisesti määriteltyjä alaryhmiä tietokantataulukoista tai käyttämällä parametreja, kuten top_k=1, jos sitä sovelletaan LangChain-komponenttien käsittelyyn. on
- Rajoitukset: Vaikka toiminnallinen, tämä on hauras korjaus. LLM ei ole tietoinen taulukoista tämän rajoitetun näkymän ulkopuolella, mikä estää monimutkaisempia kyselyitä ja vaatii manuaalisia päivityksiä. on


Step 3: Implementing PII/PHI Filtering via a Dedicated LLM Prompt
- on
- Kriittinen vaatimustenmukaisuuden tarve: Peruskyselyjen sallimisen jälkeen seuraava prioriteetti oli tietosuojakäytäntöjen noudattaminen. Yrityksille, erityisesti säännellyillä aloilla, kuten terveydenhuollossa ja pankkitoiminnassa, arkaluonteisen PII/PHI:n suodattaminen on usein tiukka lakisääteinen vaatimus (esimerkiksi HIPAA:n tai rahoituslainsäädännön vuoksi), joka on välttämätön ankarien rangaistusten välttämiseksi. on
- Ratkaisu: ”Data Security Bot”: Minun lähestymistapani liittyi siihen, että lisäsin omistettujen tietojen hävittämiskerroksen... (LLM-suodattimen täytäntöönpanoa kuvaavan kappaleen loput pysyvät ennallaan) on
- Suodatuslogiikka: Sisällä yksityiskohtainen kehotus (get_sanitize_prompt) käski tätä toista LLM: tä toimimaan "tietosuojan suodattimena". sen ensisijainen tehtävä oli tarkastella raaka-tekstin vastausta ja muokata tunnistettuja PHI: ää ja PII: ää. on


- on
- Esimerkki: Tulos kuten {'member_id': 12345, 'member_name': 'Jane Doe', 'osoite': '123 Main Street, Mercy City'} muunnetaan suodattimen LLM: llä {'member_id': 12345, 'member_name': '[REDACTED]', 'osoite': '[REDACTED]'}. on
Tässä koko diagrammi muutoksen jälkeen


Step 4: Refining Prompts for Raw SQL Generation
- on
- Haaste: Väärinkäsitys: PII-suodattimen toteuttamisen jälkeen käsittelin haasteen varmistaa, että tärkein NL-to-SQL LLM (MainLLM) ymmärsi tarkasti käyttäjän aikomuksen ennen mahdollisesti monimutkaisten tai epäselvien kyselyiden suorittamista tietokantaa vastaan. on
- Ratkaisu: "Prompt Refinement Bot": Toteutuksen luotettavuuden parantamiseksi esittelin alustavan "Prompt Refinement Bot" -kolmannen LLM-puhelun. Tämä bot toimii "asiantuntijaprosessin insinöörinä", ottaen alkuperäisen käyttäjän kyselyn ja tietokannan kaavion kirjoittamaan pyyntö erittäin nimenomaiseksi ja yksiselitteiseksi ohjeeksi MainLLM: lle. on
- Tavoitteena oli muotoilla kehotus, joka selkeästi ohjasi MainLLM: tä siitä, mitä taulukoita, sarakkeita ja ehtoja tarvitaan, maksimoimalla mahdollisuus, että se suorittaa oikean kyselyn tietokantaan ja hakee tarkoitetut tiedot. on
- Tulos: Tämä esikäsittelyvaihe paransi merkittävästi MainLLM:n keräämien tietojen johdonmukaisuutta ja tarkkuutta. on

Step 5: Enhancing Context with Conversation Memory
- on
- Tarve: Jotta käyttäjäkokemus ylittäisi yksittäiset kyselyt ja mahdollistaisi luonnollisemman vuoropuhelun, keskustelun kontekstin muistaminen oli ratkaisevan tärkeää seurantakysymysten käsittelyssä. on
- Tämä lähestymistapa käyttää LLM (gpt-3.5-turbo tässä tapauksessa) asteittain tiivistää keskustelun, pitää avainkonteksti käytettävissä samalla hallita token käyttöä (konfiguroitu max_token_limit=500). on
- Integraatio: Tämä tiivistetty {history} sisällytettiin sitten suoraan mainosmalliin, jota käytettiin vuorovaikutuksessa MainLLM:n (NL-to-SQL + Executor) kanssa käyttäjän nykyisen (mahdollisesti hienostuneen) {query}:n rinnalla. on
- Hyöty: Tämän muistikerroksen lisääminen mahdollisti järjestelmän harkitseman jatkuvaa vuoropuhelua, mikä paransi merkittävästi käytettävyyttä johdonmukaisempien ja asiayhteydet huomioivia keskusteluja tietokannan sisällöstä. on
Conclusion: Lessons from Building a Multi-LLM SQL Interface
Tämän luonnollisen kielen käyttöliittymän rakentaminen MySQL: lle LangChainilla oli paljastava matka nykyaikaisen tekoälyn kehityksen voimaan ja monimutkaisuuteen.Se, mikä alkoi tavoitteena kysyä tietokantaa käyttämällä yksinkertaista englantia, kehittyi monivaiheiseksi putkistoksi, johon liittyi kolme erillistä LLM-puhelua: yksi käyttäjän kehotusten hienosäätöön, yksi luonnollisen kielen kääntämiseen SQL: hen ja sen suorittamiseen suoraan tietokantaan ja kriittinen kolmas tulosten herkän PII/PHI: n suodattamiseksi.
Tärkeimmät haasteet, kuten LLM-tunnisteen rajojen hallinta suurilla järjestelmillä, tietosuojan varmistaminen suodatuksen avulla ja nopean ymmärryksen parantaminen vaativat iteratiivisia ratkaisuja. Vaikka tekoälyn hyödyntäminen koodin tuottamiseen nopeutti prosessin osia, yleisen arkkitehtuurin suunnittelu, erityisten logiikkojen toteuttaminen, kuten PII-suodattimen poikkeukset, komponenttien integrointi ja tiukka testaus pysyivät ratkaisevina ihmisen johtamiin tehtäviin.
Next Steps: Exploring Retrieval-Augmented Generation (RAG)
Menestysaste, etenkin monimutkaisempien tai epäselvempien kyselyiden osalta, osoittaa selkeät parannusmahdollisuudet nykyisten nopeiden tekniikoiden ja suodatustekniikoiden ulkopuolella.
Yksi lupaava tie, jota aion tutkia lisäämällä tarkkuutta, onRetrieval-Augmented Generation (RAG)Sen sijaan, että luottaisi pelkästään LLM: n sisäiseen tietoon tai staattiseen näkemykseen kaavasta, RAG esittelee dynaamisen hakuvaiheen.
Tässä NL-to-SQL -kontekstissa tämä voi sisältää seuraavien toimintojen hakemisen:
- on
- Yksityiskohtaiset kuvaukset tai asiakirjat tietyn tietokannan taulukoista ja sarakkeista, joita pidetään kyselyn kannalta merkityksellisimpinä. on
- Esimerkkejä samankaltaisista luonnollisen kielen kysymyksistä, jotka on aiemmin kartoitettu niiden oikeisiin SQL-vastaaviin. on
- Pyydettyihin tietoihin liittyvät asiaankuuluvat liiketoimintasäännöt tai määritelmät. on
Tätä vastaanotettua, kohdennettua tietoa lisätään sitten (”lisätään”) viestiin, joka lähetetään tärkeimmälle NL-to-SQL LLM: lle (MainLLMHypoteesi on, että tämä dynaaminen konteksti parantaa merkittävästi LLM: n ymmärrystä ja kykyä tuottaa tarkkaa SQL: tä, mikä mahdollisesti tarjoaa huomattavia parannuksia ilman hienosäätämisen laajoja tietokokonaisuusvaatimuksia. tehokkaan RAG-strategian toteuttaminen ja arviointi edustaa seuraavaa jännittävää vaihetta tämän keskusteluketjun käyttöliittymän parantamisessa.








