






















LangChain se ha convertido rápidamente en un marco para construir aplicaciones poderosas que aprovechen los grandes modelos de idiomas (LLM). Mientras que los LLM excelen en la comprensión del lenguaje humano, el acceso a las enormes cantidades de datos estructurados bloqueados en las bases de datos SQL normalmente requiere conocimientos especializados de consulta. Esto plantea una pregunta clave: ¿cómo podemos empoderar a más usuarios para interactuar con bases de datos, como MySQL, usando un lenguaje simple y natural?
Este artículo narra mi viaje práctico usando LangChain para construir exactamente eso - una interfaz de lenguaje natural capaz de interrogar una base de datos MySQL. Compartiré los pasos involucrados en la configuración del sistema usando Docker, los obstáculos inevitables encontrados (incluyendo la gestión de los límites de token de LLM, la garantía de la privacidad de datos sensibles y el manejo de prompts ambiguos), y las soluciones multi-paso, multi-LLM que desarrollé.
La totalidad del código de Python que implementa la herramienta de consulta de lengua natural discutida aquí fue generada con la ayuda de modelos de IA, principalmente ChatGPT y Gemini. Mi papel involucró definir los requisitos, estructurar los prompts, revisar y evaluar el código generado para la funcionalidad y los problemas potenciales, guiar a la IA a través de las revisiones necesarias, integrar los diversos componentes, y realizar las fases cruciales de prueba y depuración.
Step 1: Establishing the Foundation with Docker
- y
- El objetivo: Crear un entorno estable, aislado y multicontenedor. y
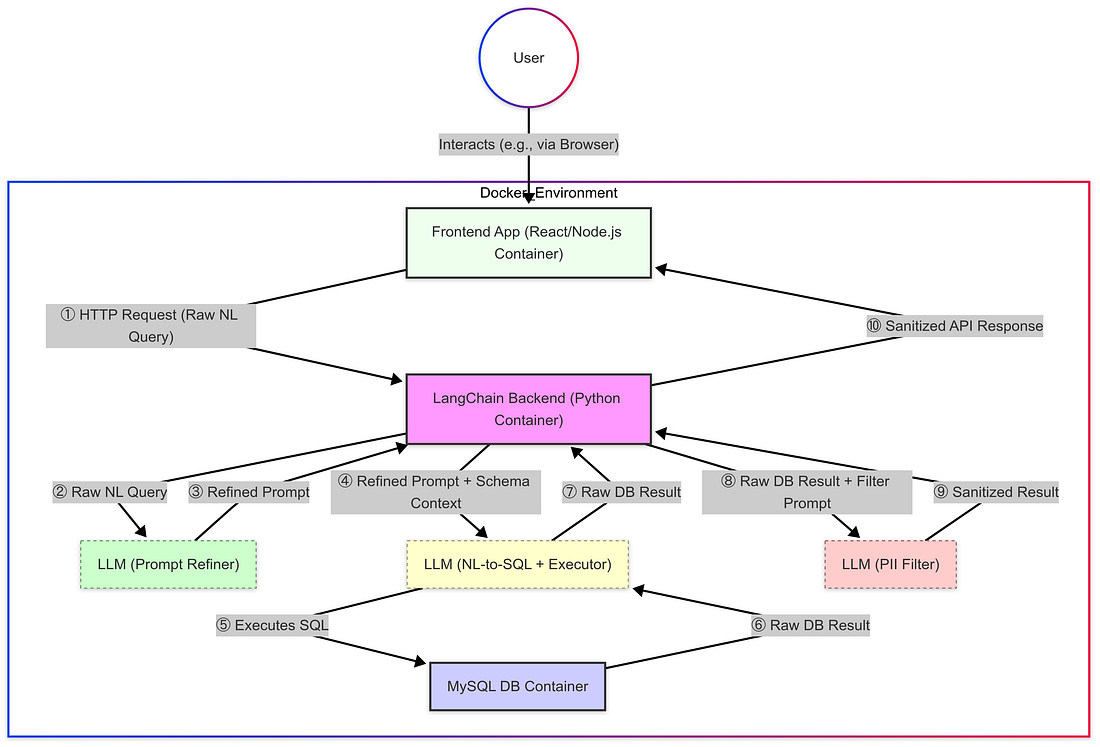
- El Método: Mi primer paso práctico fue crear un entorno confiable y reproducible utilizando Docker.La arquitectura involucró tres contenedores distintos: uno ejecutando la aplicación Frontend (React/Node.js), uno para el servicio Backend (Python con LangChain), y otro dedicado a la instancia de base de datos MySQL. y
- Detalles de configuración: El uso de Docker proporcionó una plancha limpia.El aprovechamiento de la ayuda de la IA ayudó a acelerar la creación de los Dockerfiles y docker-compose.yml necesarios para definir estos tres servicios y sus dependencias (como Python, LangChain, Node.js, conector MySQL).La configuración crítica incluyó la configuración de redes de Docker para la comunicación necesaria entre contenedores (por ejemplo, permitiendo al Frontend hablar con el Backend) y manejar de forma segura las credenciales de la base de datos utilizando variables ambientales. y
- Resultado y transición: Una vez en funcionamiento, los contenedores podrían comunicarse adecuadamente, proporcionando la infraestructura necesaria.Con esta fundación establecida, los siguientes pasos se ampliarán específicamente en el diseño de la arquitectura y los desafíos que se encuentran dentro del servicio Backend Python, ya que este es el lugar donde se implementó la lógica de base LangChain, la orquestación LLM y la tubería de procesamiento de datos. y


Step 2: First Queries and the Schema Size Challenge
- y
- Éxito inicial: La configuración containerizada funcionó, permitiendo consultas de lengua natural exitosas contra la base de datos. solicitudes simples dieron lugar a la lógica de la consulta correcta y los datos a través de LangChain y el LLM primario. y
- El desafío: Límites de token: Sin embargo, apareció rápidamente una barrera importante: errores de API debido a los límites de token. Esto ocurrió porque el contexto proporcionado al LLM a menudo incluye detalles del esquema de la base de datos (nombres de tablas/columnas, tipos), y con cientos de tablas, esta información del esquema hizo que las indicaciones fueran demasiado grandes para los límites del LLM. y
- The Workaround: Subsetting: Mi solución inmediata fue restringir la información de esquema proporcionada al LLM, tal vez considerando sólo un pequeño subconjunto definido manualmente de las tablas de la base de datos o utilizando parámetros como top_k=1 si se aplica a la representación del esquema de manejo de componentes de LangChain. y
- Limitaciones: Aunque funcional, esta es una solución frágil. El LLM permanece inconsciente de las tablas fuera de esta vista limitada, evitando consultas más complejas y requiriendo actualizaciones manuales. Esto indicó claramente que manejar esquemas de bases de datos grandes de manera eficiente requiere un enfoque más avanzado. y


Step 3: Implementing PII/PHI Filtering via a Dedicated LLM Prompt
- y
- La necesidad crítica de cumplimiento: Después de habilitar consultas básicas, la siguiente prioridad fue el cumplimiento de la privacidad de los datos. Para las empresas, en particular en los sectores regulados como el cuidado de la salud y el sector bancario, filtrar PII/PHI sensibles es a menudo un requisito legal estricto (por ejemplo, debido a la HIPAA o la regulación financiera) necesario para evitar sanciones severas. y
- La Solución: Un “Bot de Seguridad de Datos”: Mi enfoque involucró la adición de una capa de saneamiento de datos dedicada... (el resto del párrafo que describe la implementación del filtro LLM sigue siendo el mismo) y
- Lógica de filtración: En el interior, un prompt detallado (get_sanitize_prompt) instruyó a este segundo LLM a actuar como un "filtro de privacidad de datos". y


- y
- Ejemplo: Un resultado como {'member_id': 12345, 'member_name': 'Jane Doe', 'address': '123 Main Street, Mercy City'} sería transformado por el filtro LLM a {'member_id': 12345, 'member_name': '[REDACTED]', 'address': '[REDACTED]'}. y
Aquí está el diagrama completo después del cambio


Step 4: Refining Prompts for Raw SQL Generation
- y
- El desafío: Malinterpretación: Después de implementar el filtro PII, abordé el desafío de asegurarme de que el principal LLM NL-to-SQL (MainLLM) entienda con precisión la intención del usuario antes de ejecutar consultas potencialmente complejas o ambiguas contra la base de datos. y
- La Solución: Un “Prompt Refinement Bot”: Para mejorar la fiabilidad de la ejecución, introduje un preliminar “Prompt Refinement Bot” – una tercera llamada LLM. Este bot actuó como un “ingeniero de prompt experto”, tomando la consulta de usuario original y el esquema de base de datos para reescribir la solicitud en una instrucción altamente explícita e inequívoca para el MainLLM. y
- Objetivo de Refinamiento: El objetivo era formular un prompt que guiara claramente a MainLLM sobre qué tablas, columnas y condiciones se necesitaban, maximizando la posibilidad de que ejecutara la consulta correcta contra la base de datos y recuperara los datos pretendidos. y
- Resultado: Este paso de preprocesamiento mejoró significativamente la coherencia y exactitud de los datos recuperados por MainLLM. y

Step 5: Enhancing Context with Conversation Memory
- y
- La necesidad: Para elevar la experiencia del usuario más allá de las consultas únicas y permitir un diálogo más natural, recordar el contexto de la conversación era crucial para manejar las preguntas de seguimiento. y
- La implementación: Integré las capacidades de memoria de LangChain utilizando ConversationSummaryMemory. Este enfoque utiliza un LLM (gpt-3.5-turbo en este caso) para resumir progresivamente la conversación, manteniendo el contexto clave accesible mientras se gestiona el uso de token (configurado con max_token_limit=500). y
- Integración: Este {history} resumido se incorporó luego directamente al modelo de prompt utilizado cuando interactúa con el MainLLM (el NL-to-SQL + Executor), junto con el actual (potencialmente refinado) {query} del usuario. y
- Beneficio: La adición de esta capa de memoria permitió al sistema considerar el diálogo en curso, mejorando significativamente la usabilidad para conversaciones más coherentes y conscientes del contexto sobre el contenido de la base de datos. y
Conclusion: Lessons from Building a Multi-LLM SQL Interface
Construir esta interfaz de lenguaje natural a MySQL usando LangChain fue un viaje revelador en el poder y la complejidad del desarrollo de la IA moderna. Lo que comenzó como un objetivo de interrogar una base de datos usando el inglés común evolucionó en una tubería de múltiples etapas que involucraba tres llamadas LLM distintas: una para refinar las solicitudes de usuario, una para traducir el lenguaje natural a SQL y ejecutarlo directamente contra la base de datos, y una tercera crítica para filtrar PII / PHI sensibles de los resultados.
Los principales desafíos, como gestionar los límites de token de LLM con esquemas grandes, asegurar la privacidad de los datos a través de la filtración y mejorar la comprensión rápida, requieren soluciones iterativas.Aunque aprovechar la IA para la generación de código aceleró partes del proceso, diseñar la arquitectura general, implementar lógicas específicas como las excepciones del filtro de PII, integrar componentes y realizar pruebas rigurosas siguen siendo tareas cruciales impulsadas por el hombre.
Next Steps: Exploring Retrieval-Augmented Generation (RAG)
La tasa de éxito, especialmente para consultas más complejas o ambiguas, indica claras oportunidades de mejora más allá de las técnicas actuales de ingeniería rápida y filtración.
Una avenida prometedora que planeo explorar junto a una mayor precisión esRetrieval-Augmented Generation (RAG)En lugar de depender únicamente del conocimiento interno del LLM o de una visión estática del esquema, RAG introduce un paso de recuperación dinámica.Antes de generar el SQL, un sistema RAG buscaría una base de conocimiento especializada para obtener información altamente relevante para la consulta actual del usuario.
En este contexto NL-to-SQL, esto podría implicar la recuperación de:
- y
- Descripciones o documentación detalladas de las tablas y columnas de bases de datos específicas que se consideren más relevantes para la consulta. y
- Ejemplos de preguntas de lengua natural similares previamente mapeadas a sus homólogos SQL correctos. y
- Reglas comerciales o definiciones relevantes relativas a los datos solicitados. y
Esta información recuperada, dirigida se agregaría (“augmentada”) a la prompt enviada al principal LLM NL-to-SQL (MainLLM), proporcionándole un contexto más rico, justo en el tiempo. La hipótesis es que este contexto dinámico mejorará significativamente la comprensión del LLM y la capacidad de generar SQL preciso, potencialmente ofreciendo mejoras sustanciales sin los extensos requisitos de conjuntos de datos de ajuste.








