






















LangChain په چټکۍ سره د لوی زبانونو ماډلونو (LLMs) څخه ګټه ورکولو قوي غوښتنلیکونو جوړولو لپاره یو ګټه ورکول جوړ شوی دی. که څه هم LLMs د بشري ژبه درک کې غوره دي، د SQL ډاټا بیسونو کې مخکښ جوړ شوي ډاټا ډیری مقدارونو ته لاس رسی معمولا د ځانګړي پوښتنې پوهې ته اړتیا لري. دا یو مهم پوښتنه رامینځته کوي: څنګه موږ کولی شو د ډاټا بیسونو سره، لکه MySQL، د ساده، طبيعي ژبه کارولو سره د کاروونکو سره اړیکه ونیسئ؟
دا مقاله زما عملی سفر په کارولو سره د LangChain په کارولو سره د دې په سمه توګه جوړولو لپاره کلکوي - یو طبيعي ژور انټرنیټ چې د MySQL ډاټا کې پوښتنې وړ دی. زه به د ډککر په کارولو سره د سیسټم جوړولو په برخه کې اړتیاوې، د ناڅاپي چټکونو (په شمول د LLM token محدودیتونو مدیریت، حساس ډاټا رامینځته کول، او د بیلابیلو پاملرنې په کارولو سره) او د څو ګامونو، څو LLM حلونه چې زه جوړ کړم. د اړیکو د ډاټا ډاټا بیسونو ته د اړیکو AI لګول کولو چټکونو او بریالیتوبونو په څیر څارنه وکړي.
د پیتون کوډ په بشپړه توګه چې دلته بحث شوي طبیعي ژوره پوښتنې وسیله کار کوي، د AI ماډلونو، په عمده توګه ChatGPT او Gemini سره تولید شوی. زما د اړتیاوو د تعریف، د پروپتونو جوړولو، د فعالیتونو او احتمالي ستونزو لپاره د تولید شوي کوډ په لټه کې او evaluating، د AI له خوا د اړین اصلاحاتو له لارې لارښوونې، د مختلفو برخو انډول کولو، او د مهمو ازموینې او ډبګګین کولو مرحلهونو ترسره کولو کې شامل دي.
Step 1: Establishing the Foundation with Docker
- د
- هدف: د ډیری کانټینر چاپیریال جوړ کړي. د
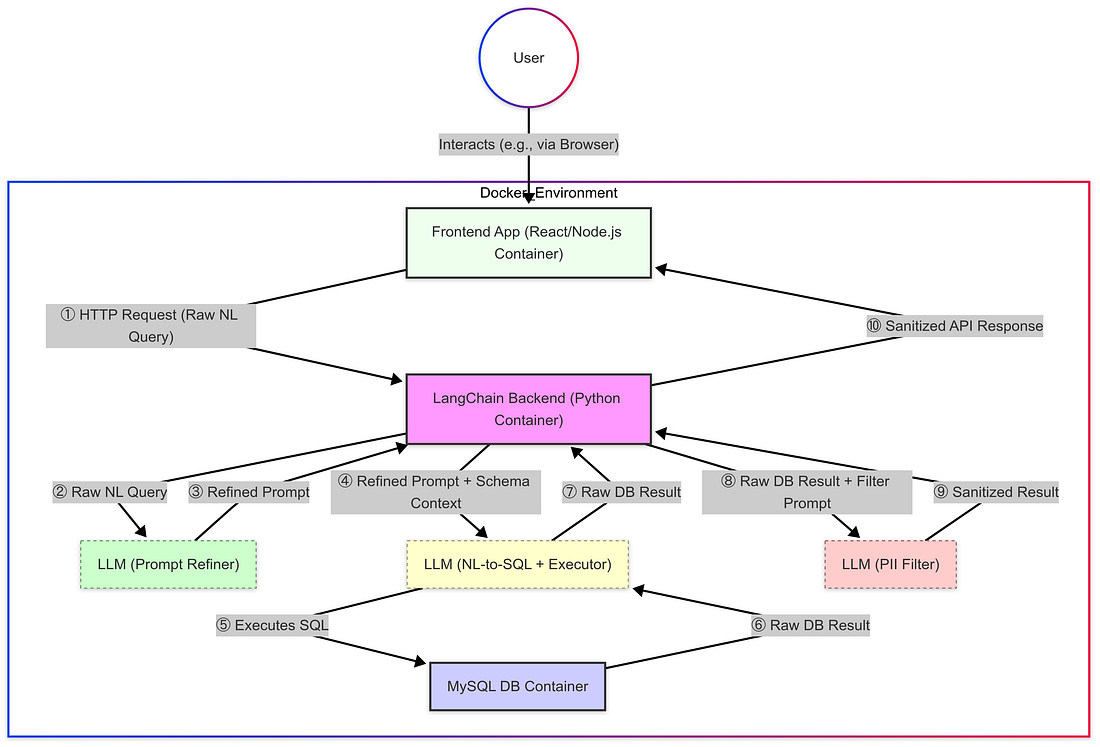
- The Method: زما لومړي عملی قدم دی چې د Docker کارولو په کارولو سره د باور وړ او reproducable چاپیریال جوړ کړي. د آرکټیکټریټ د درې مختلف کنټینرونو سره تړاو لري: یو د Frontend غوښتنلیک (React / Node.js)، یو د Backend خدمت لپاره (Python سره LangChain)، او یو بل د MySQL ډاټا ډاټا انټرنټ لپاره اختصاصي. دا کنټینریز شوي روښانه کولو ته اړتيا وي کله چې د اړتیاوو د Python کتابتونونو په ځای کې د تقاضا او پلیټ فارم غیر متوافقیتونو له امله نصب کول. د
- د نصب تفصيلات: د Docker کارولو سره د پاکیزه شیټ ترلاسه کړ. د AI ملاتړ د Dockerfiles او docker-compose.yml د جوړولو په چټکۍ سره مرسته کوي چې د دغو درې خدمتونو او د دوی د بستېونو (چې Python، LangChain، Node.js، MySQL کنکشن) د تعریف کولو لپاره اړتیا لري. د ډکر شبکې جوړولو شامل دي چې اړتیا لري د کانټینر منځني اړیکو لپاره (د مثال په توګه، د Frontend سره د Backend سره خبرې کولو ته اجازه ورکوي) او د چاپیریال بدلونونو په کارولو سره د ډاټاټا تصدیقاتو په خوندي ډول کاروي. د
- د پایلو او انتقال: یو ځل چلول، د کانټینرونه کولی شي په مناسبه توګه اړیکه ونیسئ، د اړتيا د انټرنېټ د وړاندې کولو سره. د دې بنسټ جوړولو سره، د لاندې اقدامات به په ځانګړې توګه د آرکټیکټریټ ډیزاین او د پایټین د خدمتونو په برخه کې پاملرنې ته وده ورکړي، ځکه چې دا دا دی چې د کور LangChain منطق، LLM orchestration، او د ډاټا پروسس پائپیلن جوړ شوي دي. د


Step 2: First Queries and the Schema Size Challenge
- لومړنۍ بریالیتوب: د کانټینر جوړول کارول، په ډاټاټا کې د طبيعي ژوره پوښتنو ته بریالیتوب ورکوي. ساده پوښتنو له LangChain او د لومړنۍ LLM له لارې د پوښتنې منطق او معلوماتو په درست ډول ترلاسه کړ. د
- The Challenge: Token Limits: په هرصورت، یو لوی bottleneck په چټکۍ سره ښکاري: د API غلطاتو له امله د token محدودیتونو په پرتله. دا به ځکه چې د LLM ته وړاندیز شوي پروګرامونه اغیزمنه د ډاټا ډیزاین تفصيلات شامل دي (د جدول / پړاو نومونه، ډولونه)، او د ټابلیو په ډوله کې، د دې ډیزاین معلوماتو د LLM د محدودیتونو لپاره ډیر لوی کړي. د
- The Workaround: Subsetting: زما په چټکۍ سره د حل دی چې د سیسټم معلوماتو ته د LLM ته ورکړل شي، شاید یوازې د ډاټاټا جدولونو د کوچني، manually defined زیربنا په پام کې یا د پارامترونو لکه top_k=1 په کارولو سره د LangChain پارامترونو په کارولو کې د سیسټم پیژندل په کارولو سره محدود کړي. دا په عمده توګه د پروپیلټ اندازه کم کړي او د دې زیربنا کې د پوښتنو لپاره غلطاتو مخنیوی کړي. د
- محدودیتونه: که څه هم کاروي، دا یو ناڅاپي حل دی. د LLM د دې محدود نندارې څخه بهر د جدولونو په اړه پوه نه کوي، د پیچلې پوښتنو مخنیوی او د دستاوي تازه کولو ته اړتيا لري. دا په واضح ډول ښودلې چې د لوی ډاټا ډیزاینونو په اغیزمنه توګه کارولو لپاره ډیر پرمختللي لارښوونې اړتیا لري. د


Step 3: Implementing PII/PHI Filtering via a Dedicated LLM Prompt
- د
- د مطابقت وړ اړتیا: د بنسټیز پوښتنو فعالولو وروسته، بل ترټولو ترټولو ترټولو مهم دی د ډاټا پرائیویسی مطابقت. د شرکتونو لپاره، په ځانګړي ډول د مراجعینو او بانکيز په څیر تنظیم شوي برخو کې، حساس PII / PHI فلټر کولو معمولا د سخت قانونی اړتیا دی (د مثال په توګه، د HIPAA یا مالیې مقرراتو له امله) چې اړتیا لري د سخت سزاونو څخه مخنیوی. د خام معلوماتو ته وښيي هم د مشتریانو د اعتماد کښته کوي، د شهرت زیانوي، او د داخلي امنیت او اخلاقیاتو مخنیوی. د پایلو ښودلو مخکې قوي فلټر کولو د دې اړتیاوو پوره کولو لپاره مهمه وه، په ځانګړي ډول د ټیم د لاس رسی لپاره. د
- د حل: د "Data Security Bot": زما لارښوونې شامل دي چې د ډاټا د پاکولو کچه اضافه کړي ... (د LLM فلټر غوښتنلیک په اړه د برخې بډایه ورته وي) د
- Filtering منطق: په داخلي کې، يو تفصيلي لارښوونې (get_sanitize_prompt) دا دویم LLM ته د "د معلوماتو د ساتنې چاڼګر" په توګه عمل وکړي. د دې لومړنۍ کار دا دی چې د خام متن ځواب وګورئ او identified PHI او PII رامینځته کړي. د


- د
- د مثال په توګه: د {'member_id': 12345, 'member_name': 'Jane Doe', 'address': '123 Main Street, Mercy City'} د فلټر LLM به د {'member_id': 12345, 'member_name': '[REDACTED]', 'address': '[REDACTED]' ته بدل شي. د
دلته د بدلون وروسته بشپړ ډیزاین دی


Step 4: Refining Prompts for Raw SQL Generation
- د
- د چټک: غلط تفسیر: د PII فلټر پیژندل وروسته، زه د ستونزو سره حل کړم چې د اصلي NL-to-SQL LLM (MainLLM) د کاروونکي د اټکل څخه مخکې د بیلابیلو یا بیلابیلو پوښتنو سره د ډاټا بیلابیلو غوښتنلیکونه ترسره کړي. بیلابیلو غوښتنلیکونه کولی شي MainLLM ته غلط SQL ترسره کړي، غیرقانوني ډاټا ترلاسه کړي، یا ناکام شي. د
- د حل: د "Prompt Refinement Bot": د کارولو د اعتبار د ښه کولو لپاره، زه د مخکښ "Prompt Refinement Bot" - د دریم LLM تماس. دا بوټ د "داستور پروپټ انجنیر" په توګه عمل کړ، د اصلي کاروونکي پوښتنې او د ډاټا ډیزاین په توګه د غوښتنلیک لپاره د MainLLM لپاره یو ډېر واضح او غیر متناوب لارښوونې جوړ کړي. د
- هدف Refinement: هدف دا دی چې د پروګرام جوړ کړي چې په واضح ډول MainLLM ته لارښوونه ورکوي چې هغه جدولونه، پړاوونه، او شرایط ته اړتیا لري، د امکان تر ټولو زیات کړي چې دا به د ډاټا په اړه د درست پوښتنې ترسره کړي او د مقناطیسي ډاټا ترلاسه کړي. د
- پایلې: دا مخکښ پروسس مرحله د MainLLM لخوا ترلاسه شوي معلوماتو د تعقیب او دقت په عمده توګه ښه کړ. د

Step 5: Enhancing Context with Conversation Memory
- د
- د اړتیا: د ګرځنده تجربې د انفرادي پوښتنو څخه ډیر لوړ کړي او ډیر طبيعي تبادلې وړاندیز کړي، د خبرې کولو کنکټور یادونه د پیژندنې پوښتنو په کارولو لپاره مهم دی. د
- د تطبیق: زه د ConversationSummaryMemory په کارولو سره د LangChain د حافظه وړتیاوې یوځای کړ. دا لارښوونې د LLM (په دې صورت کې د gpt-3.5-turbo) کاروي ترڅو په دوامداره توګه د اړیکو خلاص کړي، په داسې حال کې چې د ټکین کارولو مدیریت (د max_token_limit=500 سره ترتیب شوي) د کلیدي کنکشن ته لاس رسیږي. د
- Integration: دا خلاص شوي {history} وروسته په مستقیم ډول د MainLLM (د NL-to-SQL + Executor) سره د کاروونکي د اوسني (د احتمالي په بشپړولو کې) {query} سره د تعقیب کولو لپاره کارول شوي پروپیلن کې شامل شوی. د
- ګټور: د دې مینه کچه اضافه کول د سیسټم ته اجازه ورکوي چې د اوسني تبادلې په پام کې ونیسئ، په عمده توګه د کارولو وړتیا لپاره د ډاټا ډیزاین موادو په اړه ډیر متوازن او context-conscious بحثونه ښه کړي. د
Conclusion: Lessons from Building a Multi-LLM SQL Interface
د MySQL لپاره د دې طبيعي زبان انټرنیټ جوړولو په کارولو سره د LangChain په کارولو سره د عصري AI پراختیا د قدرت او پیچیدو په اړه یو ښکاره سفر و. هغه څه چې د ساده انګلیسي په کارولو سره د ډاټاټا کې پوښتنې هدف په توګه پیل شو، د درې مختلف LLM تماسونو سره یو څو مرحله پیاوړتیا ته وده ورکړي: یو د کاروونکي پاملرنې په پراختیا لپاره، یو د طبيعي زبان په SQL کې ترجمه کولو لپاره او دا په مستقیم ډول د ډاټاټا سره ترسره کولو لپاره، او د پایلو څخه حساس PII / PHI فلټر کولو لپاره یو مهم درې. د اړیکو یادښت د کارولو وړتیا زیات کړي، ډیر طبيعي، د اړیکو په اړه پوه شي.
لکه څنګه چې د لوی سیسټمونو سره د LLM ټوکن محدودیتونو مدیریت، د ډاټا رامینځته کولو له لارې ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا ډاټا
Next Steps: Exploring Retrieval-Augmented Generation (RAG)
د بریالیتوب کچه، په ځانګړې توګه د پیچلي یا بیلابیلو پوښتنو لپاره، د اوسني سټیټ انجنیري او فلټر کولو تکنالوژۍ څخه ډیر ښه فرصتونه ښيي.
یو پرانستلو سړک چې زه غواړم چې د اضافي دقت ته وده ورکړم دا دیRetrieval-Augmented Generation (RAG)پرته چې یوازې د LLM د داخلي معلوماتو یا د سیسټم د اټکل په اړه د اټکل په اړه د اعتماد پرته، د RAG د ډینمیکي کټګوریشن مرحله رامینځته کوي. د SQL تولید مخکې، د RAG سیستم به د کاروونکي د اوسني پوښتنې لپاره خورا مهم معلومات لپاره د تخصصي معلوماتو بیس په لټه کې وي.
په دې NL-to-SQL کنکشن کې، دا کولی شي د ترلاسه کولو شامل شي:
- د
- د ډاټا ډاټا ټابلیو او کالمونو لپاره تفصيلات یا سندونه چې د پوښتنې لپاره ترټولو مهم دي. د
- د ورته طبیعي ژبه پوښتنو مثالونه چې مخکې د دوی د درست SQL همکارانو ته نقشه شوي دي. د
- د غوښتنلیک شوي معلوماتو په اړه اړین سوداګرۍ قوانین یا تعریفونه. د
دا ترلاسه شوي، هدفي معلوماتو به د اصلي NL-to-SQL LLM (MainLLM), د دې سره د غليظ، just-in-time کنکشن وړاندې کوي. hypothesis دا دی چې دا د ډيزاينیک کنکشن به په عمده توګه د LLM درک او د دقیق SQL تولید وړتیا ته وده ورکړي، په احتمالي توګه د ډیټل ډاټا سیټ اړتیاوو پرته په پراخه توګه ښه کړي. د اغیزمن RAG ستراتیژۍ اجرا او evaluating د دې بحثي ډاټا بیس انټرنیټ پرمختګ کې د راتلونکي هیجان زده کړې مرحله ده.








