






















LangChain は、大規模な言語モデル (LLM) を活用する強力なアプリケーションを構築するためのフレームワークとなっています。LLM は人間の言語を理解する上で優れている一方で、SQL データベースに閉じ込められた膨大な量の構造化データにアクセスするには、通常、専門的なクエリ知識が必要です。
この記事は、MySQL データベースをクエリできる自然言語のインターフェイスを構築するために LangChain を使用した私の実践的な旅程を記録します。私は Docker を使用してシステムを構築する際のステップ、必然的な障害(LLM トークンの限界を管理し、敏感なデータのプライバシーを確保し、曖昧なプロンプトに対処するなど)、そして私が開発した複数のステップ、複数のLLM ソリューションを共有します。
ここで議論された自然言語のクエリングツールを実装するPythonコードの全体は、主にChatGPTとGeminiのAIモデルの助けを借りて生成されました。私の役割は、要件を定義し、プロンプトを構造化し、生成されたコードを機能性と潜在的な問題の見直しと評価し、AIを必要な修正を通じて導き、さまざまなコンポーネントを統合し、重要なテストとデバッグの段階を実行することでした。
Step 1: Establishing the Foundation with Docker
- ♪
- 目標:安定した、孤立した複数のコンテナ環境を作成する。 ♪
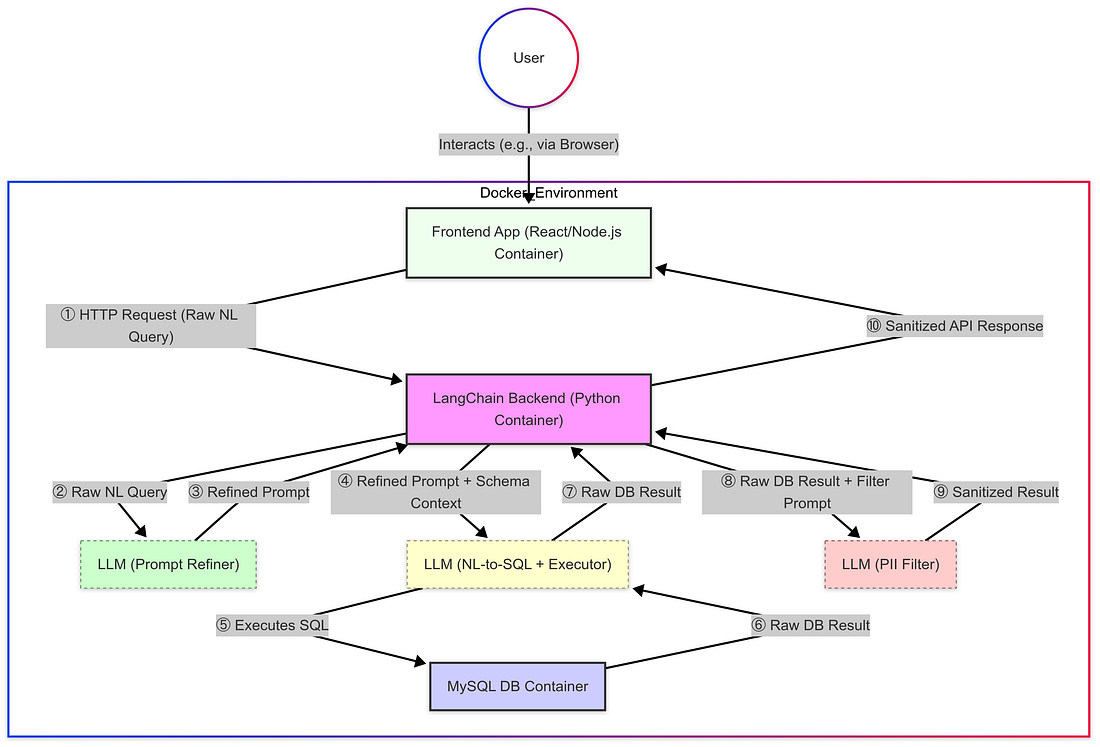
- The Method: My first practical step was to create a reliable and reproducible environment using Docker. The architecture involved three distinct containers: one running the Frontend application (React/Node.js), one for the Backend service (Python with LangChain), and another dedicated to the MySQL database instance. This containerized approach became necessary after encountering frustrating difficulties installing the required Python libraries locally due to dependency conflicts and platform incompatibilities. このアーキテクチャには、Frontendアプリケーション(React/Node.js)を実行する3つの異なるコンテナが含まれていた。 ♪
- インストールの詳細: Docker を使用するとクリーンなスライドが提供されました. AI サポートを活用することで、Dockerfiles と docker-compose.yml の作成を加速させ、これらの 3 つのサービスとその依存性 (Python、LangChain、Node.js、MySQL コネクタなど) を定義するのに必要でした。 ♪
- Outcome & Transition: Once running, the containers could communicate appropriately, providing the necessary infrastructure. With this foundation established, the following steps will zoom in specifically on the architecture design and challenges encountered within the Backend Python service, as this is where the core LangChain logic, LLM orchestration, and data processing pipeline were implemented. この基礎が確立されると、次のステップは、バックエンドPythonサービス内で直面するアーキテクチャの設計と課題に特化されます。 ♪


Step 2: First Queries and the Schema Size Challenge
- ♪
- 最初の成功:コンテナ化されたセットアップは機能し、データベースに対する自然言語のクエリを成功させました. Simple requests yielded correct query logic and data via LangChain and the primary LLM. ♪
- The Challenge: Token Limits: However, a major bottleneck quickly emerged: API errors due to exceeding token limits. This happened because the context provided to the LLM often includes database schema details (table/column names, types), and with hundreds of tables, this schema information made the prompts too large for the LLM’s limits. トークン制限: トークン制限: しかし、大きなボトルネームはすぐに現れた:このスケジュールのエラーは、トークン制限を超えるために起こった。 ♪
- The Workaround: Subsetting: My immediate solution was to restrict the schema information provided to the LLM, by only considering a small, manually defined subset of the database tables or using parameters such as top_k=1 if applicable to the LangChain component handling schema representation. This significantly reduced prompt size and avoided the errors for queries within that subset. データベーステーブルの小さな、手動で定義されたサブセットのみを考慮して、LLMに提供されたスケジュール情報を制限することでした。 ♪
- 制限:機能的であるにもかかわらず、これは脆弱な解決策です。LLMは、この制限されたビューの外にあるテーブルに気づいていませんが、より複雑なクエリを防止し、手動の更新を必要とします。 ♪


Step 3: Implementing PII/PHI Filtering via a Dedicated LLM Prompt
- ♪
- 重要なコンプライアンスの必要性: 基本的なクエリを有効にした後、次の優先事項はデータプライバシーの遵守でした。 特に保健や銀行などの規制分野の企業にとって、敏感なPII/PHIのフィルタリングは、厳しい法的要件(例えば、HIPAAまたは財務規制のせい)であり、厳しい罰則を避けるために必要です。 ♪
- The Solution: A “Data Security Bot”: My approach involved adding a dedicated data sanitization layer... (the rest of the paragraph describing the LLM filter implementation remains the same) ♪
- Filtering Logic: Inside, a detailed prompt (
get_sanitize_prompt) instructed this second LLM to act as a "data privacy filter." Its primary task was to review the raw text response and redact identified PHI and PII. ♪


- ♪
- 例: {'member_id': 12345, 'member_name': 'Jane Doe', 'address': '123 Main Street, Mercy City'} のような結果は、フィルター LLM によって {'member_id': 12345, 'member_name': '[REDACTED]', 'address': '[REDACTED]' に変換されます。 ♪
以下は、変更後の全体図です。


Step 4: Refining Prompts for Raw SQL Generation
- ♪
- 課題:誤解: PII フィルターを実装した後、私は主要な NL-to-SQL LLM (MainLLM) が、データベースに対して潜在的に複雑または曖昧なクエリを実行する前にユーザーの意図を正確に理解するという課題に直面しました。 ♪
- The Solution: A “Prompt Refinement Bot”: 実行の信頼性を向上させるために、私は初期の “Prompt Refinement Bot” を導入しました – 第三の LLM 呼び出し. このボットは“専門的なプロンプトエンジニア”として機能し、元のユーザー クエリとデータベース スケジュールを MainLLM のために非常に明確で曖昧な指示にリリースします。 ♪
- Goal of Refinement: The goal was to formulate a prompt that clearly guided MainLLM on what tables, columns, and conditions were needed, maximizing the chance it would execute the correct query against the database and retrieve the intended data. ターゲットは、メインLLMがどのテーブル、列、および条件が必要であるかを明確に指示するプロンプトを作成し、データベースに対して正しいクエリを実行し、意図されたデータを取得する可能性を最大化することでした。 ♪
- 結果:この前処理ステップは MainLLM が取得したデータの一貫性と正確性を大幅に改善しました。 ♪

Step 5: Enhancing Context with Conversation Memory
- ♪
- 必要性:単一のクエリを超えてユーザー体験を高め、より自然な対話を可能にするために、会話の文脈を覚えて、フォローアップの質問を扱うために重要でした。 ♪
- The Implementation: I integrated LangChain’s memory capabilities using ConversationSummaryMemory. This approach uses an LLM (gpt-3.5-turbo in this case) to progressively summarize the conversation, keeping key context accessible while managing token usage (configured with max_token_limit=500). このアプローチはLLM(この場合のgpt-3.5-turbo)を使用して、会話を段階的にまとめ、キーコンテキストをアクセスし、トークンの使用を管理します。 ♪
- Integration: This summarized {history} was then incorporated directly into the prompt template used when interacting with the MainLLM (the NL-to-SQL + Executor), alongside the user's current (potentially refined) {query}. この概要した {history} は、ユーザーの現在の {query} に直接組み込まれました。 ♪
- 利点:このメモリ層を追加することで、システムは継続的な対話を検討し、データベースのコンテンツに関するより一貫性と文脈意識の高い会話のための可用性を大幅に向上させました。 ♪
Conclusion: Lessons from Building a Multi-LLM SQL Interface
このLangChainを使用してMySQLへの自然言語インターフェイスを構築することは、現代のAI開発の強さと複雑さを明らかにする旅でした。単純英語を使用してデータベースをクエリするという目標として始まったことは、3つの異なるLLM呼び出しを含む複数の段階のパイプラインに発展しました: 1つはユーザーのプロンプトの精密化、1つは自然言語をSQLに翻訳し、データベースに直接実行し、そして3つ目は結果から敏感なPII/PHIをフィルタリングするための重要な3つです。
LLMのトークン制限を大規模なスケジュールで管理し、フィルタリングを通じてデータのプライバシーを確保し、迅速な理解を向上させるなどの重要な課題は、コード生成のためのAIを活用する一方で、プロセスの部分を加速させる一方で、全体的なアーキテクチャを設計し、PIIフィルタ例外のような特定の論理を実装し、コンポーネントを統合し、厳格なテストは重要な人間主導のタスクにとどまりました。
Next Steps: Exploring Retrieval-Augmented Generation (RAG)
特に複雑または曖昧なクエリの場合、成功率は、現在の迅速なエンジニアリングおよびフィルタリング技術を超える改善のための明確な機会を示しています。
さらに精度を高めるために探求する予定の有望な1つの道は、Retrieval-Augmented Generation (RAG)単にLLMの内部知識やスケジュールの静的見解に依存するのではなく、RAGは動的検索ステップを導入します。
この NL-to-SQL コンテキストでは、以下をリクエストする場合があります。
- ♪
- 特定のデータベースのテーブルや列の詳細な説明またはドキュメントは、クエリに最も関連していると考えられます。 ♪
- 類似した自然言語の質問の例は、以前に正しい SQL 同僚にマッピングしたものです。 ♪
- 要求されたデータに関連する関連するビジネスルールまたは定義。 ♪
次に、この情報は、主な NL-to-SQL LLM に送信されたプロンプトに追加されます(「拡大」)。MainLLM仮説は、このダイナミックな文脈は、LLMの理解と正確なSQLを生成する能力を大幅に向上させ、細かい調整の幅広いデータセット要件なしに実質的な改善を提供する可能性があります。








