






















LangChain imekuwa haraka kuwa mfumo wa kuingia kwa ajili ya kujenga maombi yenye nguvu yanayotumia Models kubwa ya Lugha (LLMs). Ingawa LLMs kufaidika katika kuelewa lugha ya kibinadamu, upatikanaji wa kiasi kikubwa cha data iliyoundwa iliyohifadhiwa katika database za SQL kawaida inahitaji ujuzi wa utafutaji maalum. Hii inatoa swali muhimu: jinsi gani tunaweza kuwezesha watumiaji zaidi kuingiliana na database, kama MySQL, kwa kutumia lugha rahisi, asili?
Makala hii inashughulikia safari yangu ya vitendo kwa kutumia LangChain ili kujenga hasa hiyo - interface ya lugha ya asili inayoweza kutafuta database ya MySQL. Nitachapisha hatua zinazohusiana na kuanzisha mfumo kwa kutumia Docker, vikwazo vya kutokuwepo (ikiwa ni pamoja na kusimamia mipaka ya token ya LLM, kuhakikisha faragha ya data nyeti, na kukabiliana na maombi ya utambulisho), na ufumbuzi wa hatua nyingi wa LLM niliyojenga.
Kila msimbo wa Python unaotumia chombo cha kutafuta lugha ya asili kilichozungumzwa hapa ulizaliwa kwa msaada wa mifano ya AI, hasa ChatGPT na Gemini. Jukumu langu lilihusisha kufafanua mahitaji, muundo wa maombi, kuangalia na kutathmini msimbo uliotengenezwa kwa utendaji na matatizo ya uwezekano, kuongoza AI kupitia marekebisho muhimu, kuunganisha vipengele mbalimbali, na kufanya hatua muhimu za majaribio na udhibiti.
Step 1: Establishing the Foundation with Docker
- ya
- Hii ni changamoto kwa waandaaji wa app na programu za kompyuta kuangalia katika eneo la Machine learning na kulifanyia kazi eneo hili la sekta ya teknolojia. ya
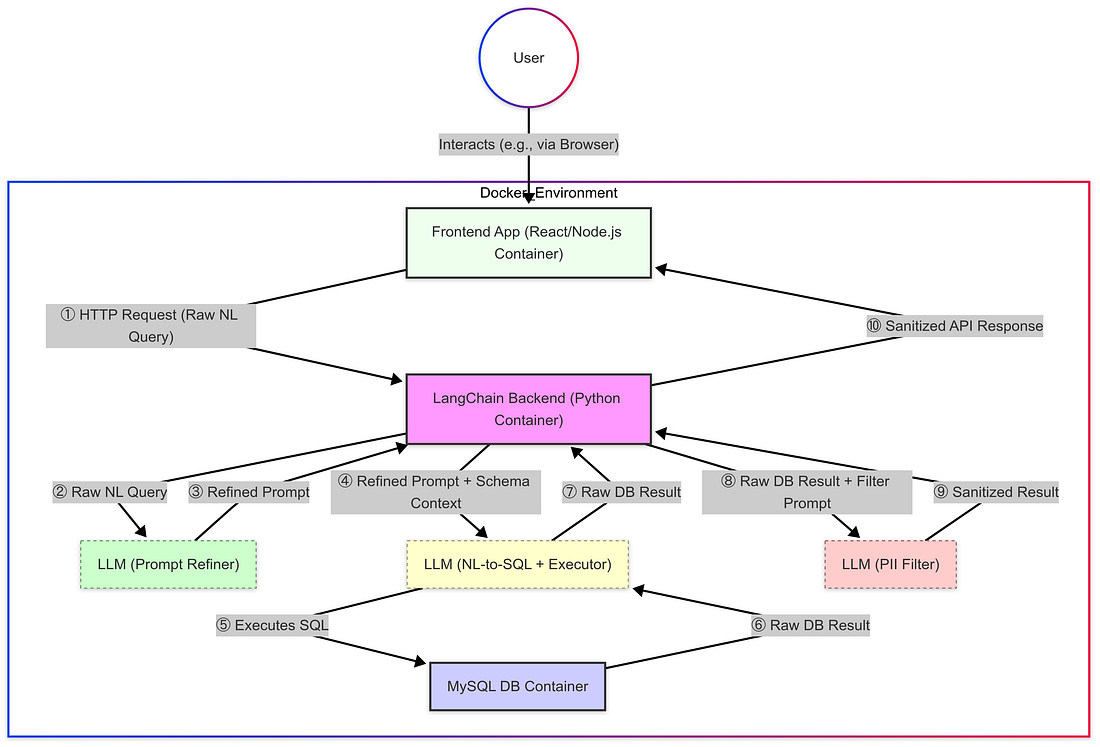
- Njia: Hatua yangu ya kwanza ya vitendo ilikuwa kujenga mazingira ya kuaminika na ya kuigiza kwa kutumia Docker. Usanifu ulihusisha containers tatu tofauti: moja iliyoendesha programu ya Frontend (React / Node.js), moja kwa huduma ya Backend (Python na LangChain), na nyingine iliyoandaliwa kwa instance ya database ya MySQL. Njia hii ilipatikana baada ya kukabiliana na matatizo ya kushangaza ya kufunga maktaba ya Python inayohitajika kwa ndani kutokana na migogoro ya kujitegemea na upungufu wa jukwaa. ya
- Maelezo ya ufungaji: Kutumia Docker ilitoa slate safi. Kutumia msaada wa AI alisaidia kuharakisha uumbaji wa Dockerfiles na docker-compose.yml zinahitajika kufafanua huduma hizi tatu na mahusiano yao (kama vile Python, LangChain, Node.js, connector MySQL). Usimamizi muhimu ulihusisha kuanzisha mtandao wa Docker kwa mawasiliano muhimu kati ya Container (kwa mfano, kuruhusu Frontend kuzungumza na Backend) na kushughulikia kwa salama vifaa vya database kutumia variables ya mazingira. ya
- Matokeo & Mabadiliko: Mara moja kuendesha, containers inaweza kuwasiliana kwa usahihi, kutoa miundombinu inayohitajika. Na msingi huu ulioanzishwa, hatua zifuatazo zitaongezeka hasa juu ya kubuni ya usanifu na changamoto zilizopatikana ndani ya huduma ya Backend Python, kama hii ndiyo ambapo mantiki ya msingi ya LangChain, orchestration ya LLM, na pipeline ya usindikaji wa data zilianzishwa. ya


Step 2: First Queries and the Schema Size Challenge
- ya
- Mafanikio ya awali: Ujenzi wa Containerized ulifanya kazi, kuruhusu maswali ya lugha ya asili ya mafanikio dhidi ya database. Maombi rahisi yalisababisha mantiki sahihi ya maswali na data kupitia LangChain na LLM ya msingi. ya
- Changamoto: Kiwango cha Token: Hata hivyo, kikwazo kikubwa kilionekana haraka: makosa ya API kutokana na kupungua kwa kiwango cha token. Hii ilitokea kwa sababu mazingira yaliyotolewa kwa LLM mara nyingi yanajumuisha maelezo ya mipangilio ya database (jina la meza / safu, aina), na na mamia ya meza, habari hii ya mipangilio ilifanya mapendekezo makubwa sana kwa mipaka ya LLM. ya
- Workaround: Subsetting: Suluhisho langu la haraka lilikuwa kuzuia habari ya mipangilio iliyotolewa kwa LLM, labda kwa kuzingatia tu sehemu ndogo, zilizotajwa kwa mikono ya meza za database au kutumia vigezo kama top_k=1 ikiwa inatumika kwa uwakilishi wa mipangilio ya usindikaji wa sehemu za LangChain. ya
- Masharti: Ingawa kazi, hii ni ufumbuzi mdogo. LLM haijakuwa na ufahamu wa meza nje ya mtazamo huu mdogo, kuzuia maswali magumu zaidi na yanahitaji updates manual. Hii ilionyesha wazi kwamba kushughulikia mipangilio ya database kubwa kwa ufanisi inahitaji mbinu ya juu zaidi. ya


Step 3: Implementing PII/PHI Filtering via a Dedicated LLM Prompt
- ya
- Mahitaji muhimu ya ufuatiliaji: Baada ya kuruhusu maswali ya msingi, kipaumbele kingine kilikuwa ufuatiliaji wa faragha ya data. Kwa makampuni, hasa katika sekta zilizosajiliwa kama huduma za afya na benki, kuvutia PII / PHI mara nyingi ni mahitaji ya kisheria (kwa mfano, kutokana na HIPAA au kanuni za kifedha) ambayo inahitajika kuepuka adhabu kali. ya
- Suluhisho: “Bot ya Usalama wa Data”: Njia yangu ilihusisha kuongeza kiwango cha kujitolea cha uchafuzi wa data... (kawaida paragraph inayoelezea utekelezaji wa filters ya LLM bado ni sawa) ya
- Filtering Logic: Ndani, mwongozo wa kina (get_sanitize_prompt) aliongoza LLM hii ya pili kutenda kama "filter ya faragha ya data." kazi yake kuu ilikuwa kuangalia majibu ya maandishi mapya na kuhariri PHI na PII zilizotambuliwa. ya


- ya
- Mfano: Matokeo kama {'member_id': 12345, 'member_name': 'Jane Doe', 'address': '123 Main Street, Mercy City'} yatabadilishwa na filters LLM kwa {'member_id': 12345, 'member_name': '[REDACTED]', 'address': '[REDACTED]'}. ya
Hapa ni ripoti nzima baada ya mabadiliko


Step 4: Refining Prompts for Raw SQL Generation
- ya
- Changamoto: Ufafanuzi mbaya: Baada ya kutekeleza filters ya PII, nilijibu changamoto ya kuhakikisha LLM kuu ya NL-to-SQL (MainLLM) ilijua kwa usahihi nia ya mtumiaji kabla ya kutekeleza maswali yanayoweza kuwa magumu au ya udanganyifu dhidi ya database. maelekezo ya udanganyifu yanaweza kusababisha MainLLM kutekeleza SQL isiyo sahihi, kupata data isiyofaa, au kushindwa. ya
- Suluhisho: "Prompt Refinement Bot": Ili kuboresha uaminifu wa utekelezaji, nilianzisha "Prompt Refinement Bot" awali - wito wa tatu wa LLM. Bot hii alifanya kazi kama "mchambuzi wa wataalam wa prompt," kuchukua query ya mtumiaji ya awali na mpango wa database kuandika upya ombi katika maelekezo ya wazi sana na ya wazi kwa MainLLM. ya
- Lengo la Ufafanuzi: Lengo lilikuwa kuunda mwongozo ambao uliongoza wazi MainLLM juu ya meza, safu, na hali zinahitajika, kuongeza uwezekano wa kuendesha query sahihi dhidi ya database na kupata data iliyotajwa. ya
- Matokeo: Hatua hii ya kabla ya usindikaji iliboresha kwa kiasi kikubwa utaratibu na usahihi wa data zilizopatikana na MainLLM. ya

Step 5: Enhancing Context with Conversation Memory
- ya
- Mahitaji: Ili kuongeza uzoefu wa mtumiaji zaidi ya queries moja na kuruhusu mazungumzo ya asili zaidi, kukumbuka mazingira ya mazungumzo yalikuwa muhimu kwa kushughulikia maswali ya kufuatilia. ya
- Utekelezaji: Niliunganisha uwezo wa kumbukumbu wa LangChain kwa kutumia ConversationSummaryMemory. mbinu hii inatumia LLM (gpt-3.5-turbo katika kesi hii) kwa hatua kwa hatua kwa kuzingatia mazungumzo, kuweka mazingira muhimu inapatikana wakati wa kusimamia matumizi ya token (kuwekwa na max_token_limit=500). ya
- Ushirikiano: Historia hii iliyoungwa mkono baadaye iliingizwa moja kwa moja kwenye template ya prompt iliyotumika wakati wa kuingiliana na MainLLM (de NL-to-SQL + Executor), pamoja na mtumiaji wa sasa (ambayo inaweza kuimarishwa) {query}. ya
- Faida: Kuongezea kiwango hiki cha kumbukumbu iliruhusu mfumo kuzingatia mazungumzo yanayoendelea, kwa kiasi kikubwa kuboresha matumizi kwa mazungumzo ya pamoja na ya mazingira kuhusu maudhui ya database. ya
Conclusion: Lessons from Building a Multi-LLM SQL Interface
Kujenga interface hii ya lugha ya asili kwa MySQL kwa kutumia LangChain ilikuwa safari ya kufichua nguvu na utata wa maendeleo ya kisasa ya AI. Kile kilichotokea kama lengo la kutafuta database kwa kutumia Kiingereza ya kawaida kilibadilika kuwa mstari wa pipeline unaohusisha wito watatu tofauti wa LLM: moja kwa ajili ya kufafanua maombi ya mtumiaji, moja kwa kutafsiri lugha ya asili kwa SQL na kuendesha moja kwa moja dhidi ya database, na tatu muhimu kwa ajili ya kuvutia PII / PHI kutoka kwa matokeo.
Changamoto muhimu kama vile kusimamia mipaka ya token ya LLM na mipangilio makubwa, kuhakikisha faragha ya data kwa njia ya kupima, na kuboresha ufahamu wa haraka unahitaji ufumbuzi wa iterative. Wakati kutumia AI kwa kuzalisha msimbo iliongezeka sehemu za mchakato, kubuni usanifu wa jumla, kutekeleza mantiki maalum kama kivuli cha filters ya PII, kuunganisha vipengele, na majaribio ya dhati yalikuwa majukumu muhimu ya mwanadamu.
Next Steps: Exploring Retrieval-Augmented Generation (RAG)
Kiwango cha mafanikio, hasa kwa maswali magumu au ambiguous, inaonyesha fursa wazi ya kuboresha zaidi ya mbinu za sasa za uhandisi wa haraka na filters.
Moja ya barabara ya kuahidi nina mpango wa kuchunguza karibu na kuongeza zaidi usahihi niRetrieval-Augmented Generation (RAG)Badala ya kutegemea tu maarifa ya ndani ya LLM au mtazamo wa static wa mfumo, RAG inachukua hatua ya kutafuta nguvu. kabla ya kuzalisha SQL, mfumo wa RAG utafuta msingi wa maarifa maalum kwa habari muhimu sana kwa swali la sasa la mtumiaji.
Katika muktadha huu wa NL-to-SQL, hii inaweza kuhusisha kutafuta:
- ya
- Maelezo ya kina au nyaraka kwa meza na safu za database maalum ambazo zinaonekana kuwa muhimu zaidi kwa query. ya
- Mifano ya maswali sawa ya lugha ya asili yaliyopangwa hapo awali kwa washiriki wao sahihi wa SQL. ya
- Kanuni za biashara au ufafanuzi unaohusiana na data iliyohitajika. ya
Ujumbe huu uliopatikana, ufuatiliaji wa taarifa hiyo utaongezwa ("kuongezeka") kwenye mwongozo uliotumwa kwa LLM kuu ya NL-to-SQL (MainLLM), kutoa kwa utajiri zaidi, tu-katika wakati mazingira. Madhumuni ni kwamba mazingira haya ya nguvu itaongeza kwa kiasi kikubwa ufahamu wa LLM na uwezo wa kuzalisha SQL sahihi, uwezekano wa kutoa uboreshaji mkubwa bila mahitaji makubwa ya dataset ya fine-tuning. kutekeleza na tathmini ya mkakati wa ufanisi wa RAG inawakilisha hatua inayovutia ya pili katika kuboresha interface hii ya database ya mazungumzo.








