






















LangChain- ը արագորեն դարձել է հզոր ծրագրերի կառուցման համար, որոնք օգտագործում են Large Language Models (LLMs): Երբ LLM-ները գերազանցում են մարդային լեզուի հասկանալը, ստանալը SQL- ի տվյալների բազաններում բեռված խոշոր մանրամասն տվյալների մանրամասները սովորաբար պահանջում են մասնագիտացված հարցերի գիտելիքներ: Այսպիսով մի կարեւոր հարց է: Ինչպե՞ս կարող ենք ավելի օգտվողներին հզորել տվյալների բազանների, ինչպիսիք են MySQL- ը, օգտագործելով պարզ, բնական լեզուը:
Այս հոդվածը գրում է իմ գործնական ճանապարհը LangChain- ի օգտագործման համար, որպեսզի ստեղծել ճշգրտապես այն - բնական լեզուային ինտերֆեյս, որը կարող է հարցնել MySQL բազանը: Ես կասկածեմ համակարգի տեղադրման քայլերը, որոնք օգտագործում են Docker- ը, սխալները, որոնք կասկածվում են (կամ LLM token limits- ի կառավարման, sensitive data privacy- ի ապահովման, եւ համոզված կասկածների կառավարման համար), եւ բազմաթիվ քայլերի, multi-LLM լուծումներ, որոնք ես ստեղծել եմ: Հետեւեք այն, որ կասկածեք կասկածված AI- ի փոխանցման փորձները եւ հաջողություններ.
Բոլոր Python- ի կոդը, որը կատարում է այստեղ խոսված բնական լեզուների հարցման գործիքը, ստեղծվել է AI մոդելների օգնությամբ, հիմնականում ChatGPT- ի եւ Gemini- ի հետ: Իմ աշխատանքը ներառում է պահանջների սահմանափակման, պրպտների կառուցման, արտադրված կոդը վերլուծման եւ evaluation- ի համար գործառույթների եւ հնարավոր խնդիրների համար, AI- ի վերլուծման համար անհրաժեշտ վերլուծությունների միջոցով, տարբեր բաղադրիչների ինտեգրման, եւ կատարելու կարեւոր փորձարկման եւ debugging փուլներ:
Step 1: Establishing the Foundation with Docker
- Հիմնական
- Հիմնական նպատակը: ստեղծել պլաստիկ, հուսալի Multi-Containers միջավայրի. Հիմնական
- The Method: Իմ առաջին ճշգրիտ քայլը էր ստեղծել հավասարավետ եւ վերլուծելի միջավայք օգտագործելով Docker- ը: Այս դիզայնը ներառում է երեք տարբեր բաղադրիչներ: մեկը աշխատում է Frontend ծրագրի (React/Node.js), մեկը Backend ծառայության համար (Python with LangChain), եւ մեկը մասնագիտացած է MySQL բաղադրիչների բաղադրիչների բաղադրիչների համար: Այս բաղադրիչների բաղադրիչը անհրաժեշտ էր, երբ պետք է տեղադրել պահանջվող Python բաղադրիչները տեղականորեն բաղադրիչների բաղադրիչների եւ հարմարավետության պատճառով. Հիմնական
- Docker- ի օգտագործումը ապահովել է ճշգրտությունը: AI- ի օգնությունը օգնում է արագացնել Dockerfiles- ի եւ docker-compose.yml- ի ստեղծումը, որը անհրաժեշտ է այդ երեք ծառայությունների եւ իրենց բուժման համար (հարկե Python, LangChain, Node.js, MySQL connector): Հիմնական konfiguration- ը ներառում է Docker- ի ցանցերի ստեղծման համար, որոնք անհրաժեշտ են միասնական բուժիչների կապի համար (հարկե, թույլ է տալիս Frontend- ը խոսել Backend- ի հետ) եւ անվտանգորեն կառավարել բազան բազան հավելվածքները, օգտագործելով միջավայրի տարբերակներ: Հիմնական
- Ապրանքը & Transition: Երբ կատարվում է, կետերները կարող են կապել հարմարավետորեն, ապահովելով անհրաժեշտ ինտրաֆորմացիա: Այս հիմնվածության հետ, հետեւյալ քայլերը կպատկեն մասնավորապես դիզայնի դիզայնի եւ խնդիրների հետ Backend Python ծառայության մեջ, քանի որ այսն է, որտեղ հիմնական LangChain logic, LLM դիզայնը, եւ տվյալների մշակման խողովակների տեղադրվել են: Հիմնական


Step 2: First Queries and the Schema Size Challenge
- Հիմնական
- Հիմնական հաջողություն: Կոնտենտերացված տեղադրումը աշխատել է, որը թույլ է տալիս բնական լեզուների պահանջները բազանի հետ: Հիմնական պահանջները արտադրել են ճշգրիտ հարցերի լոգիկը եւ տվյալները LangChain- ի եւ հիմնական LLM- ի միջոցով: Հիմնական
- The Challenge: Token Limits: Սակայն, մեծ բաղադրիչը արագ հայտնաբերվել է: API սխալներ, քանի որ լիցքավորվում են token limits. Սա կատարվել է, քանի որ LLM- ում տրամադրված բաղադրիչները հաճախ ներառում են բազանային սխալների տեղեկություններ (բանակի / սեղմների անուններ, տեսքներ), եւ սխալների կոշիկների հետ, այս սխալային տեղեկությունները դարձել են պրակտները շատ մեծ են LLM- ի սահմանափակների համար: Հիմնական
- The Workaround: Subsetting: Իմ անմիջական լուծում էր սահմանափակել schema տեղեկատվությունը, որը տրամադրվում է LLM- ում, կարող է լինել միայն օգտագործելով մի փոքր, մանրաձայնորեն սահմանափակված սարքավորումներ բազանային բազաների կամ օգտագործելով պարամետրեր, ինչպիսիք են top_k=1, եթե կիրառվում է LangChain- ի բազանային բազանների կառավարման սարքավորումների ցուցադրման համար: Այսպիսով կարեւորորեն նվազեցվել է սարքավորումների չափը եւ փրկվել են սխալները այս սարքավորումների մեջ: Հիմնական
- Պահպանումներ: Մինչեւ գործառույթային, դա մի սխալ լուծում է. LLM- ը չի իմանալ, թե այս սահմանափակ տեսակը ներառում են տեքստեր, որը թույլ է տալիս ավելի հարմարեցված հարցերը եւ պահանջում է մանրամասն update- ը: Սա բացառապես ցույց է տալիս, որ մեծ բազան բազանների սխալների արդյունավետ կառավարման համար անհրաժեշտ է ավելի առաջադեմ հարմարություններ: Հիմնական


Step 3: Implementing PII/PHI Filtering via a Dedicated LLM Prompt
- Հիմնական
- Հիմնական պահանջը հարմարավետության համար: Հիմնական հարցերի հարմարեցման հետո, հաջորդ priority- ը էր տվյալների հարմարավետությունը: Ընկերությունների համար, հատկապես բիզնեսների համար, ինչպիսիք են բժշկության եւ բանկային ոլորտներում, հարմարավետ PII/PHI- ի փաթեթավորման հաճախ մի հզոր իրավունքային պահանջը է (հարկե, HIPAA- ի կամ ֆինանսական կարգավիճակների համար), որը պահանջվում է սխալ բուժման համար: Բարձր տվյալների բացառումը նաեւ կախված է հաճախորդների հավասարությունը, կախված է հավասարությունը, եւ կախված է ներքին անվտանգության եւ սխալության: Այսպիսով, արդյունքների ցուցադրելու առաջ հզոր փաթեթավորումը կարեւոր էր այդ հարմարավետության պահանջների Հիմնական
- The Solution: A “Data Security Bot”: Իմ հարմարավետությունը ներառում է մասնավոր data sanitization layer- ի ավելացումը... (լուսանկարներ LLM Filter- ի տեղադրման համար) Հիմնական
- Filtering Logic: Արդյոք ներսում, մանրամասն ուղեցույց (get_sanitize_prompt) ուղեցույց է այս երկրորդ LLM- ում աշխատել որպես "Data Privacy Filter" - ում: Նրա հիմնական գործառույթը էր վերլուծել սեղմված գրքի պատասխանը եւ գրել Identified PHI եւ PII: Հիմնական


- Հիմնական
- Նշում է, որ «member_id»: 12345, «member_name»: «Jane Doe», «address»: «123 Main Street, Mercy City»} կարող է փոխվել է «member_id»: 12345, «member_name»: «[REDACTED]», «address»: «[REDACTED]»}. Հիմնական
Այսպիսին է ամբողջ դիզայնը փոխանցման հետո:


Step 4: Refining Prompts for Raw SQL Generation
- Հիմնական
- The Challenge: Բխաղադրություն: PII սեղմելուց հետո, ես լուծել եմ սխալը ապահովելու համար, որ հիմնական NL-to-SQL LLM (MainLLM) ճշգրտությամբ հասկանում է օգտվողի նպատակը, նախքան կատարելու համար կարող է հարմարավետ կամ անսահմանափակ հարցեր բազանի հետ: Vague prompts կարող է վերցնել MainLLM- ը անսահմանափակ SQL- ը, վերցնել անսահմանափակ տվյալներ, կամ սխալ. Հիմնական
- The Solution: A “Prompt Refinement Bot”: Որպես է բարելավվել կատարման հավասարությունը, ես տեղադրել եմ նախնական “Prompt Refinement Bot” – մի երեք LLM call. Այս bot- ը աշխատել է որպես “պատեգորիանային prompt ինժեներ”, օգտագործելով առաջին օգտագործողի հարցը եւ բազանային սխալը, որպեսզի վերլուծել պահանջը շատ բացառիկ եւ անսահմանափակ instructions համար MainLLM. Հիմնական
- Տեղադրման նպատակը: Նրա նպատակը էր ստեղծել մի ուղեցույց, որը բացահայտել է MainLLM- ը, թե ինչ սեղաններ, սեղաններ, եւ պայմաններ անհրաժեշտ են, maksimizing the chance it would execute the correct query against the database and retrieve the intended data. Հիմնական
- Ապրանքը: Այս pre-processing քայլը կարեւորորեն բարելավեց MainLLM- ի վերցված տվյալների միասնականությունը եւ ճշգրիտությունը: Հիմնական

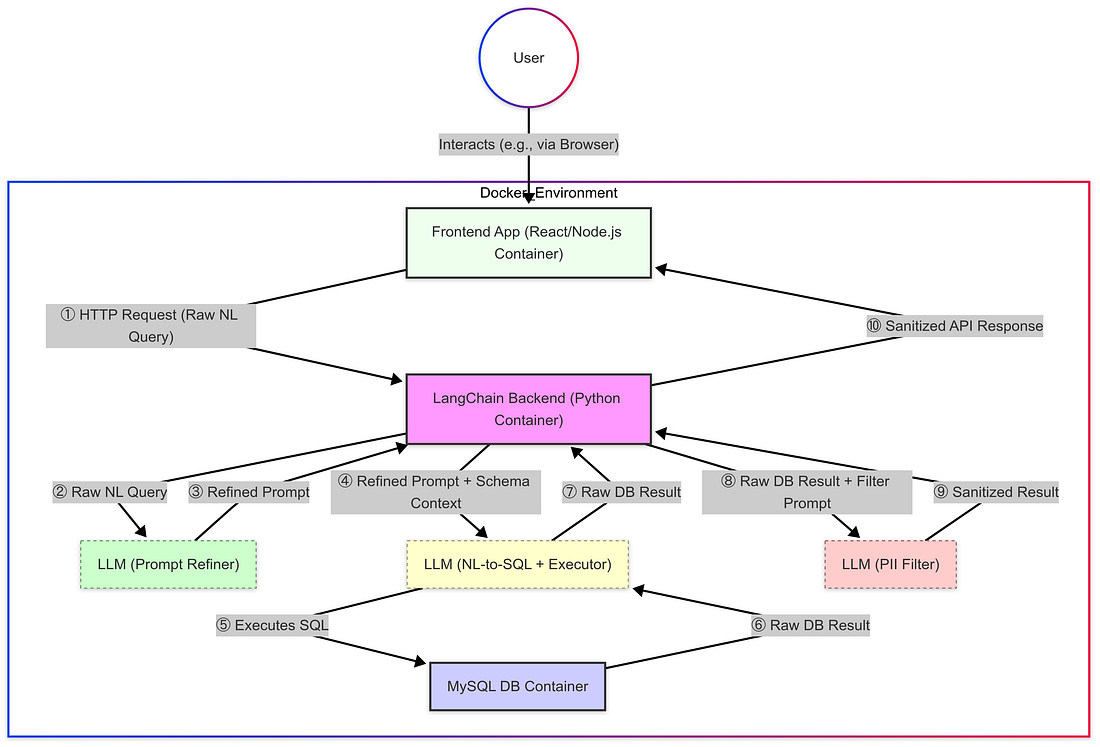
Step 5: Enhancing Context with Conversation Memory
- Հիմնական
- The Necessity: Եթե ցանկանում եք բարձրացնել օգտվողի փորձը միասին հարցերի վրա եւ թույլ տալ ավելի բնական խոսքը, մոռացեք խոսքի բաղադրիչը, որը կարեւոր է հետազոտության հարցերի կառավարման համար: Հիմնական
- The Implementation: I integrated LangChain’s memory capabilities using
ConversationSummaryMemory. This approach uses an LLM (gpt-3.5-turboin this case) to progressively summarize the conversation, keeping key context accessible while managing token usage (configured withmax_token_limit=500). Հիմնական - Հիմնադրություն: Այս վերլուծված {history}- ը այն ժամանակ, երբ օգտագործվում է MainLLM- ի (NL-to-SQL + Executor- ի) ինտեգրման ժամանակ, մուտքագրվել է օգտվողի ժամանակակից (մատավորված) { Query}- ի հետ: Հիմնական
- Ապրանքներ: Ապրանքը թույլ է տալիս համակարգը վերցնել օպերացիոն խոսքեր, որը կարեւորորեն բարելավում է օգտագործելիությունը ավելի միասնական եւ contextual- իպերացիոն խոսքերով բազանային մատակարարության մասին: Հիմնական
Conclusion: Lessons from Building a Multi-LLM SQL Interface
Այս բաղադրիչը ստեղծել MySQL- ում LangChain- ի օգտագործում է, որը բացահայտել է ժամանակակից AI- ի մշակման հզորությունը եւ հարմարավետությունը: Այն, ինչ սկսվել է բաղադրիչների բազաների համար, օգտագործելով անգլերենը, զարգացվել է բազմաթիվ մակարդակային խողովակով, որը ներառում է երեք տարբեր LLM- ի զանգվածներ: մեկը օգտագործողը մատակարարելու համար, մեկը բաղադրիչների համար SQL- ի համար, եւ այն անմիջապես գործելու համար բազաների հետ, եւ մեկը, որը կարեւոր է զգալի PII / PHI- ի փաթեթավորման համար արդյունքների վրա: Համատեղելի խոսքի մանրամասը ավելին բարձրացել է օգտագործողությունը, որը թույլ է տալիս ավելի բնական, բաղադրիչ- իման
Հիմնական խնդիրները, ինչպիսիք են LLM- ի token limits- ի կառավարումը մեծ սխալների հետ, տվյալների անվտանգության ապահովումը փաթեթավորման միջոցով, եւ բարելավման արագ հասկանալը պահանջվում են թվային լուծումներ: Երբ AI- ի օգտագործումը կոդը արտադրման համար արագեցվել է գործընթացի մասերը, նախագծման ամբողջական դիզայնը, օգտագործման մասնավոր լոգիկայի, ինչպիսիք են PII փաթեթավորման բացառություններ, ինտեգրման գործառույթները, եւ ճշգրիտ փորձարկման, շարունակել են կարեւոր անձնական գործառույթներ:
Next Steps: Exploring Retrieval-Augmented Generation (RAG)
Հիմնականապես ավելի խոշոր կամ անսահմանափակ հարցերի համար, հաջողության մակարդակը ցույց է տալիս, որ հասանելի է բարելավման հնարավորությունները, այլեւ առաջադեմ տեխնոլոգիաների եւ փաթեթավորման տեխնոլոգիաների վրա:
Մարդիկ, ովքեր պետք է անում են, կարող են ավելի լավ ստանալRetrieval-Augmented Generation (RAG)Արդյոք, այնպես էլ, որ RAG- ը պարզապես հավատում է LLM- ի ներքին գիտելիքի կամ սմարթի ստանդարտ տեսակը, RAG- ը ներառում է Dynamic Retrieval- ի քայլը: Նախորդում, RAG- ի սմարթը ստանում է RAG- ի մասնագիտացված գիտելիքի բազան, որը պետք է գտնել տեղեկատվություն, որը շատ կարեւոր է օգտագործողի ժամանակակից հարցի համար:
Այս NL-to-SQL միջավայում, դա կարող է ներառում վերցնել:
- Հիմնական
- Արդյունաբերական մանրամասներ կամ մանրամասներ մասնավոր բազանային բազաների եւ բազաների համար, որոնք իմանալ են, որ ամենամեծ կարեւոր են հարցի համար: Հիմնական
- Ապրանքներ, ինչպիսիք են բնական լեզուների հարցեր, որոնք նախընտրում են թարմացնել իրենց ճշգրտական SQL- ի միասին: Հիմնական
- Relevant business rules or definitions related to the data requested. Հիմնական
Այս վերցված, տեղադրված տեղեկատվություն հետո ավելացվի (“augmented”) ուղարկել է հիմնական NL-to-SQL LLM- ին (MainLLM), ապահովելով այն ավելի խոշոր, just-in-time միջավայրի. Հիմնականը այն է, որ այս դինամիկ միջավայրի կարեւորորեն կօգնեն LLM- ի հասկանալը եւ կարողությունը ստեղծել ճշգրիտ SQL, կարող է առաջարկել կարեւոր բարելավություններ, առանց լայն dataset պահանջները fine-tuning. Implementing and evaluating an effective RAG strategy represents the next exciting phase in enhancing this conversational database interface.








