






















A LangChain gyorsan a nagy nyelvi modelleket (LLM-eket) kihasználó erőteljes alkalmazások létrehozására szolgáló keretrendszerré vált. Míg az LLM-ek az emberi nyelv megértésében kiválóak, az SQL-adatbázisokban elzárt nagy mennyiségű strukturált adathoz való hozzáférés általában speciális lekérdezési ismereteket igényel. Ez kulcsfontosságú kérdést vet fel: hogyan tudunk több felhasználót felhatalmazni az adatbázisokkal, például a MySQL-el való interakcióra egyszerű, természetes nyelven?
Ez a cikk összefoglalja a LangChain használatával végzett gyakorlati utazásomat, hogy pontosan ezt építsem ki – egy természetes nyelvi interfészt, amely képes lekérdezni egy MySQL adatbázist. Megosztom a Docker használatával a rendszer telepítéséhez kapcsolódó lépéseket, az elkerülhetetlen akadályokat (beleértve az LLM token korlátok kezelését, az érzékeny adatvédelem biztosítását és a kétértelmű utasítások kezelését), valamint a többlépcsős, több LLM megoldásokat, amelyeket kifejlesztettem.
Az itt megvitatott természetes nyelv lekérdezési eszközt végrehajtó teljes Python-kódot AI-modellek, elsősorban a ChatGPT és a Gemini segítségével hozták létre. A szerepem a követelmények meghatározása, a felhívások strukturálása, a generált kód felülvizsgálata és értékelése a funkcionalitás és a lehetséges problémák tekintetében, az AI irányítása a szükséges felülvizsgálatokon keresztül, a különböző komponensek integrálása, valamint a kritikus tesztelési és hibakeresési szakaszok végrehajtása.
Step 1: Establishing the Foundation with Docker
- Az
- A cél: Stabil, elszigetelt multi-container környezet létrehozása. Az
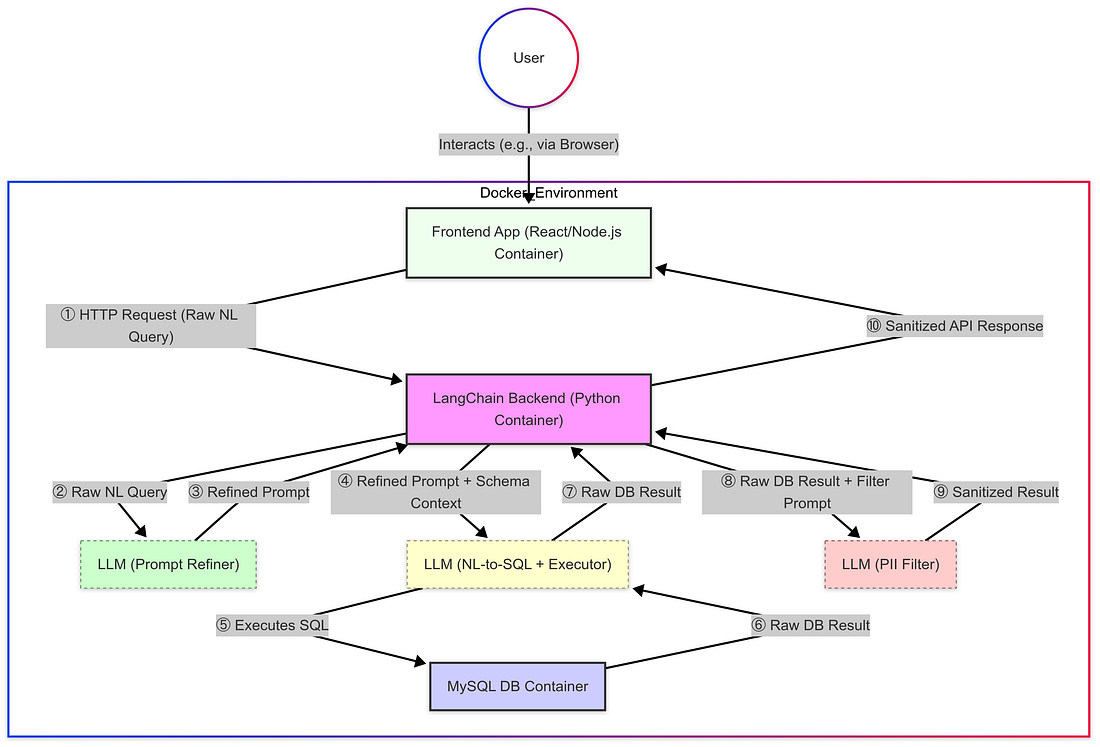
- A módszer: Az első gyakorlati lépésem egy megbízható és reprodukálható környezet létrehozása volt a Docker használatával. Az építészet három különböző konténerrel foglalkozott: az egyik futtatta a Frontend alkalmazást (React/Node.js), az egyik a Backend szolgáltatást (Python a LangChain segítségével), és egy másik a MySQL adatbázis példányára volt szentelve. Az
- Beállítás részletei: A Docker használata tiszta sávot biztosított.Az AI-támogatás segítségével felgyorsult a Dockerfiles és a docker-compose.yml létrehozása, amelyek szükségesek a három szolgáltatás és azok függőségeinek meghatározásához (például Python, LangChain, Node.js, MySQL csatlakozó). A kritikus konfigurációk közé tartozott a Docker hálózatok létrehozása a szükséges konténerek közötti kommunikációhoz (például lehetővé téve a Frontend számára, hogy beszéljen a Backenddel) és biztonságosan kezelje az adatbázis-hitelesítőket a környezeti változók segítségével. Az
- Eredmény és átmenet: Miután futott, a konténerek megfelelően kommunikálhatnak, biztosítva a szükséges infrastruktúrát.Az alapítvány létrehozásával a következő lépések különösen az építészeti tervezésre és a Backend Python szolgáltatásban felmerülő kihívásokra összpontosítanak, mivel ez az, ahol a LangChain alapvető logikáját, az LLM orchestrációját és az adatfeldolgozási csővezetéket végrehajtották. Az


Step 2: First Queries and the Schema Size Challenge
- Az
- Kezdeti siker: A konténeres beállítás működött, lehetővé téve a sikeres természetes nyelvi lekérdezéseket az adatbázis ellen. Az
- The Challenge: Token Limits: However, a major bottleneck quickly emerged: API errors due to exceeding token limits. This happened because the context provided to the LLM often includes database schema details (table/column names, types), and with hundreds of tables, this schema information made the prompts too large for the LLM’s limits. Az
- The Workaround: Subsetting: Azonnali megoldásom az volt, hogy korlátozzam az LLM-nek nyújtott vázlatinformációkat, talán csak az adatbázis-táblák kis, manuálisan meghatározott alcsoportjának figyelembevételével, vagy olyan paraméterek használatával, mint a top_k=1, ha alkalmazható a LangChain komponens kezelési vázlat reprezentációjára. Az
- Korlátozások: Bár funkcionális, ez egy törékeny megoldás.Az LLM nem ismeri a korlátozott nézeten kívüli táblákat, megakadályozza a bonyolultabb lekérdezéseket és kézi frissítéseket igényel. Az


Step 3: Implementing PII/PHI Filtering via a Dedicated LLM Prompt
- Az
- Az alapvető követelményeknek való megfelelés kritikus szükségessége: Az alapvető lekérdezések engedélyezése után a következő prioritás az adatvédelmi megfelelés volt. A vállalatok számára, különösen az olyan szabályozott ágazatokban, mint az egészségügy és a banki szektor, az érzékeny PII/PHI szűrése gyakran szigorú jogi követelmény (például a HIPAA vagy a pénzügyi szabályozás miatt), amelyre szigorú büntetések elkerülése érdekében van szükség. Az
- A megoldás: A „Data Security Bot”: Az én megközelítésem egy dedikált adatkezelési réteg hozzáadásával foglalkozott... (az LLM szűrő megvalósítását leíró bekezdés többi része ugyanaz marad) Az
- Szűrési logika: Belül egy részletes utasítás (get_sanitize_prompt) utasította ezt a második LLM-t, hogy "adatvédelmi szűrőként" járjon el. Elsődleges feladata az volt, hogy felülvizsgálja a nyers szöveges válaszokat és szerkeszti az azonosított PHI és PII-t. Az


- Az
- Példa: Egy olyan eredmény, mint a {'member_id': 12345, 'member_name': 'Jane Doe', 'cím': '123 Main Street, Mercy City'} az LLM szűrővel {'member_id': 12345, 'member_name': '[REDACTED]', 'cím': '[REDACTED]'} alakul át. Az
Íme a teljes diagram a változás után


Step 4: Refining Prompts for Raw SQL Generation
- Az
- A kihívás: félreértés: A PII szűrő végrehajtása után megbirkóztam azzal a kihívással, hogy a fő NL-to-SQL LLM (MainLLM) pontosan megérti a felhasználó szándékát, mielőtt végrehajtaná a potenciálisan összetett vagy kétértelmű lekérdezéseket az adatbázis ellen.
- A megoldás: A "Prompt Refinement Bot": A végrehajtás megbízhatóságának javítása érdekében bevezettem az előzetes "Prompt Refinement Bot" - egy harmadik LLM hívást. Az
- A cél az volt, hogy megfogalmazzon egy utasítást, amely egyértelműen irányítja a MainLLM-et, hogy milyen táblák, oszlopok és feltételek szükségesek voltak, maximalizálva annak esélyét, hogy a helyes lekérdezést végrehajtja az adatbázis ellen, és visszaszerezze a tervezett adatokat.
- Eredmény: Ez az előfeldolgozási lépés jelentősen javította a MainLLM által gyűjtött adatok következetességét és pontosságát. Az

Step 5: Enhancing Context with Conversation Memory
- Az
- A szükséglet: Ahhoz, hogy a felhasználói élményt az egyetlen lekérdezésen túlra emeljék, és lehetővé tegyék a természetesebb párbeszédet, a beszélgetés kontextusának megjegyzése döntő fontosságú volt a nyomon követési kérdések kezeléséhez. Az
- A megvalósítás: A LangChain memóriakapacitásait a ConversationSummaryMemory használatával integráltam. Ez a megközelítés egy LLM-t (ebben az esetben gpt-3.5-turbo) használ a beszélgetés fokozatos összefoglalására, a kulcsfontosságú kontextus hozzáférhetővé tételére, miközben a token használatát kezeli (max_token_limit=500-al konfigurálva). Az
- Integráció: Ezt az összegzett {történetet} ezután közvetlenül a MainLLM (az NL-to-SQL + Executor) interakció során használt prompt sablonba építették be a felhasználó aktuális (potenciálisan finomított) {lekérdezésének} mellett. Az
- Előny: A memóriatartomány hozzáadása lehetővé tette a rendszer számára, hogy figyelembe vegye a folyamatban lévő párbeszédet, jelentősen javítva a felhasználhatóságot a kontextuálisabb és konzisztensebb beszélgetésekhez az adatbázis tartalmáról. Az
Conclusion: Lessons from Building a Multi-LLM SQL Interface
A természetes nyelvi interfész létrehozása a MySQL-hez a LangChain segítségével egy feltáró utazás volt a modern AI fejlesztés hatalmába és összetettségébe. Ami a egyszerű angol nyelvű adatbázis lekérdezésének céljaként kezdődött, egy többszintű csővezetékké alakult ki, amely három különböző LLM-hívást tartalmazott: az egyik a felhasználói utasítások finomítására, az egyik a természetes nyelv SQL-re történő lefordítására és közvetlenül az adatbázis ellen végrehajtására, és egy kritikus harmadik az érzékeny PII/PHI szűrésére az eredményekből.
Az olyan kulcsfontosságú kihívások, mint az LLM token határainak nagy rendszerekkel való kezelése, az adatvédelem szűrésen keresztül történő biztosítása és az azonnali megértés javítása, iteratív megoldásokat igényeltek.Míg az AI felhasználása a kódgeneráláshoz felgyorsította a folyamat részeit, az általános architektúra megtervezése, a konkrét logika megvalósítása, például a PII szűrő kivételek, az összetevők integrálása és a szigorú tesztelés továbbra is kulcsfontosságú emberi irányú feladatok maradtak.
Next Steps: Exploring Retrieval-Augmented Generation (RAG)
A siker aránya, különösen a bonyolultabb vagy kétértelműbb lekérdezések esetében, egyértelmű lehetőségeket jelez a jelenlegi gyors mérnöki és szűrési technikákon túlmutató fejlesztésekre.
Egy ígéretes utat tervezek felfedezni a további pontosság növelése mellettRetrieval-Augmented Generation (RAG)Ahelyett, hogy kizárólag az LLM belső ismereteire vagy a rendszer statikus megtekintésére támaszkodna, a RAG egy dinamikus keresési lépést vezet be.
Ebben az NL-to-SQL összefüggésben ez magában foglalhatja a következőket:
- Az
- A lekérdezéshez leginkább relevánsnak ítélt adatbázis-táblák és oszlopok részletes leírása vagy dokumentációja. Az
- Hasonló természetes nyelvű kérdések példái, amelyeket korábban a helyes SQL társaikra helyeztek. Az
- A kért adatokkal kapcsolatos vonatkozó üzleti szabályok vagy meghatározások. Az
Ez a visszakeresett, célzott információt ezután hozzáadjuk („bővített”) a fő NL-to-SQL LLM-hez küldött utasításhoz (MainLLMA hipotézis az, hogy ez a dinamikus kontextus jelentősen javítja az LLM megértését és képességét a pontos SQL létrehozására, potenciálisan jelentős fejlesztéseket kínál a finomhangolás kiterjedt adatkészletkövetelményei nélkül.








