






















LangChain đã nhanh chóng trở thành một framework để xây dựng các ứng dụng mạnh mẽ tận dụng các mô hình ngôn ngữ lớn (LLMs). Trong khi LLMs xuất sắc trong việc hiểu ngôn ngữ của con người, truy cập vào lượng lớn dữ liệu có cấu trúc bị khóa trong cơ sở dữ liệu SQL thường đòi hỏi kiến thức truy vấn chuyên môn. điều này đặt ra một câu hỏi quan trọng: làm thế nào chúng ta có thể trao quyền cho nhiều người dùng để tương tác với cơ sở dữ liệu, chẳng hạn như MySQL, bằng cách sử dụng ngôn ngữ đơn giản, tự nhiên?
Bài viết này ghi lại hành trình thực tế của tôi bằng cách sử dụng LangChain để xây dựng chính xác điều đó – một giao diện ngôn ngữ tự nhiên có khả năng truy vấn cơ sở dữ liệu MySQL. Tôi sẽ chia sẻ các bước liên quan đến việc thiết lập hệ thống bằng cách sử dụng Docker, những trở ngại không thể tránh khỏi gặp phải (bao gồm quản lý giới hạn mã thông báo LLM, đảm bảo quyền riêng tư dữ liệu nhạy cảm và xử lý lời nhắc mơ hồ), và các giải pháp đa bước, đa LLM mà tôi đã phát triển.
Toàn bộ mã Python thực hiện công cụ truy vấn ngôn ngữ tự nhiên được thảo luận ở đây đã được tạo ra với sự giúp đỡ của các mô hình AI, chủ yếu là ChatGPT và Gemini. vai trò của tôi liên quan đến việc xác định các yêu cầu, cấu trúc các yêu cầu, xem xét và đánh giá mã được tạo ra cho chức năng và các vấn đề tiềm năng, hướng dẫn AI thông qua các sửa đổi cần thiết, tích hợp các thành phần khác nhau, và thực hiện các giai đoạn kiểm tra và xử lý lỗi quan trọng.
Step 1: Establishing the Foundation with Docker
- Thì
- Mục tiêu: Tạo ra một môi trường đa container ổn định, cô lập. Thì
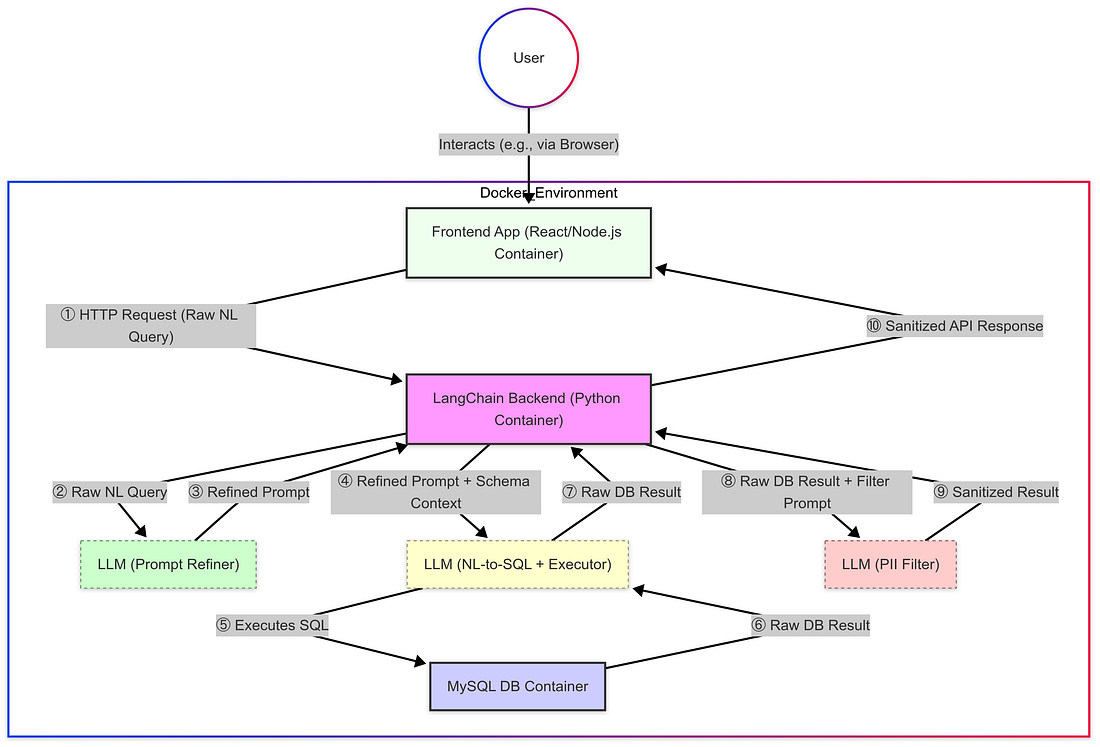
- Phương pháp: Bước thực tế đầu tiên của tôi là tạo ra một môi trường đáng tin cậy và có thể tái tạo bằng cách sử dụng Docker. Kiến trúc liên quan đến ba container khác nhau: một chạy ứng dụng Frontend (React/Node.js), một cho dịch vụ Backend (Python với LangChain), và một dành riêng cho phiên bản cơ sở dữ liệu MySQL. Cách tiếp cận chứa này trở nên cần thiết sau khi gặp phải những khó khăn thất vọng khi cài đặt các thư viện Python cần thiết tại địa phương do xung đột phụ thuộc và không tương thích nền tảng. Thì
- Chi tiết cài đặt: Sử dụng Docker cung cấp một bảng tính sạch sẽ. Tận dụng hỗ trợ AI giúp tăng tốc tạo Dockerfiles và docker-compose.yml cần thiết để xác định ba dịch vụ này và các phụ thuộc của chúng (như Python, LangChain, Node.js, kết nối MySQL). cấu hình quan trọng bao gồm thiết lập mạng Docker để liên lạc giữa các container cần thiết (ví dụ, cho phép Frontend nói chuyện với Backend) và xử lý an toàn các thông tin cơ sở dữ liệu bằng cách sử dụng các biến môi trường. Thì
- Kết quả & Chuyển đổi: Một khi chạy, các container có thể giao tiếp phù hợp, cung cấp cơ sở hạ tầng cần thiết. Với nền tảng này được thiết lập, các bước sau đây sẽ tăng cường cụ thể về thiết kế kiến trúc và những thách thức gặp phải trong dịch vụ Backend Python, vì đây là nơi logic cốt lõi LangChain, tổ chức LLM và đường ống xử lý dữ liệu đã được thực hiện. Thì


Step 2: First Queries and the Schema Size Challenge
- Thì
- Thành công ban đầu: Cài đặt container đã hoạt động, cho phép truy vấn ngôn ngữ tự nhiên thành công chống lại cơ sở dữ liệu. yêu cầu đơn giản mang lại logic truy vấn và dữ liệu chính xác thông qua LangChain và LLM chính. Thì
- Thách thức: Giới hạn token: Tuy nhiên, một chướng ngại vật lớn nhanh chóng xuất hiện: lỗi API do vượt quá giới hạn token. Điều này xảy ra bởi vì bối cảnh được cung cấp cho LLM thường bao gồm chi tiết sơ đồ cơ sở dữ liệu (tấm / tên cột, loại), và với hàng trăm bảng, thông tin sơ đồ này làm cho các lời nhắc quá lớn cho giới hạn của LLM. Thì
- The Workaround: Subsetting: Giải pháp ngay lập tức của tôi là hạn chế thông tin sơ đồ được cung cấp cho LLM, có lẽ chỉ bằng cách xem xét một tiểu tập nhỏ được xác định thủ công của các bảng cơ sở dữ liệu hoặc sử dụng các thông số như top_k=1 nếu áp dụng cho đại diện sơ đồ xử lý thành phần LangChain. Thì
- Giới hạn: Mặc dù chức năng, đây là một giải pháp mỏng manh. LLM vẫn không nhận thức được các bảng bên ngoài dạng xem hạn chế này, ngăn chặn các truy vấn phức tạp hơn và yêu cầu cập nhật thủ công. Điều này cho thấy rõ ràng rằng xử lý các sơ đồ cơ sở dữ liệu lớn hiệu quả đòi hỏi một cách tiếp cận tiên tiến hơn. Thì


Step 3: Implementing PII/PHI Filtering via a Dedicated LLM Prompt
- Thì
- Nhu cầu quan trọng về tuân thủ: Sau khi kích hoạt các truy vấn cơ bản, ưu tiên tiếp theo là tuân thủ quyền riêng tư dữ liệu. Đối với các công ty, đặc biệt là trong các lĩnh vực được quy định như y tế và ngân hàng, lọc PII / PHI nhạy cảm thường là một yêu cầu pháp lý nghiêm ngặt (ví dụ, do HIPAA hoặc quy định tài chính) cần thiết để tránh các hình phạt nghiêm trọng. Thì
- Giải pháp: Một “Data Security Bot”: Cách tiếp cận của tôi liên quan đến việc thêm một lớp vệ sinh dữ liệu chuyên dụng... (các phần còn lại của đoạn mô tả việc thực hiện bộ lọc LLM vẫn giữ nguyên) Thì
- Filtering Logic: Bên trong, một lời nhắc chi tiết (get_sanitize_prompt) hướng dẫn LLM thứ hai này để hoạt động như một bộ lọc quyền riêng tư dữ liệu. nhiệm vụ chính của nó là xem xét câu trả lời bằng văn bản thô và chỉnh sửa PHI và PII được xác định. Thì


- Thì
- Ví dụ: Một kết quả như {'member_id': 12345, 'member_name': 'Jane Doe', 'address': '123 Main Street, Mercy City'} sẽ được chuyển đổi bởi bộ lọc LLM thành {'member_id': 12345, 'member_name': '[REDACTED]', 'address': '[REDACTED]'}. Thì
Dưới đây là toàn bộ biểu đồ sau khi thay đổi


Step 4: Refining Prompts for Raw SQL Generation
- Thì
- Thách thức: Giải thích sai: Sau khi thực hiện bộ lọc PII, tôi đã giải quyết thách thức đảm bảo rằng NL-to-SQL LLM chính (MainLLM) hiểu chính xác ý định của người dùng trước khi thực hiện các truy vấn có khả năng phức tạp hoặc mơ hồ chống lại cơ sở dữ liệu. lời nhắc mơ hồ có thể dẫn đến MainLLM để thực hiện SQL không chính xác, lấy dữ liệu không liên quan, hoặc thất bại. Thì
- Giải pháp: Một "Prompt Refinement Bot": Để cải thiện độ tin cậy của việc thực hiện, tôi đã giới thiệu một "Prompt Refinement Bot" sơ bộ - một cuộc gọi LLM thứ ba. bot này hoạt động như một "kỹ sư yêu cầu chuyên gia", sử dụng truy vấn người dùng ban đầu và sơ đồ cơ sở dữ liệu để viết lại yêu cầu thành một hướng dẫn rất rõ ràng và rõ ràng cho MainLLM. Thì
- Mục tiêu của Refinement: Mục tiêu là để xây dựng một lời nhắc mà hướng dẫn rõ ràng MainLLM về những gì bảng, cột, và điều kiện là cần thiết, tối đa hóa cơ hội nó sẽ thực hiện truy vấn chính xác chống lại cơ sở dữ liệu và lấy dữ liệu dự định. Thì
- Kết quả: Bước trước xử lý này đã cải thiện đáng kể tính nhất quán và độ chính xác của dữ liệu thu thập được bởi MainLLM. Thì

Step 5: Enhancing Context with Conversation Memory
- Thì
- Nhu cầu: Để nâng cao trải nghiệm người dùng vượt ra ngoài các truy vấn duy nhất và cho phép đối thoại tự nhiên hơn, ghi nhớ bối cảnh hội thoại là rất quan trọng để xử lý các câu hỏi tiếp theo. Thì
- Việc thực hiện: Tôi tích hợp khả năng bộ nhớ của LangChain bằng cách sử dụng ConversationSummaryMemory. Cách tiếp cận này sử dụng một LLM (gpt-3.5-turbo trong trường hợp này) để tóm tắt dần cuộc trò chuyện, giữ cho bối cảnh chính có thể truy cập trong khi quản lý việc sử dụng token (được cấu hình với max_token_limit=500).
- Tích hợp: Lịch sử tóm tắt này sau đó được kết hợp trực tiếp vào mẫu nhắc được sử dụng khi tương tác với MainLLM (các NL-to-SQL + Executor), cùng với người dùng hiện tại (có khả năng tinh chỉnh) {query}. Thì
- Lợi ích: Thêm lớp bộ nhớ này cho phép hệ thống xem xét các cuộc đối thoại đang diễn ra, cải thiện đáng kể khả năng sử dụng cho các cuộc trò chuyện nhất quán hơn và có ý thức về ngữ cảnh về nội dung cơ sở dữ liệu. Thì
Conclusion: Lessons from Building a Multi-LLM SQL Interface
Xây dựng giao diện ngôn ngữ tự nhiên này cho MySQL bằng cách sử dụng LangChain là một hành trình tiết lộ sức mạnh và sự phức tạp của phát triển AI hiện đại. Những gì bắt đầu với mục tiêu truy vấn một cơ sở dữ liệu bằng tiếng Anh đơn giản đã phát triển thành một đường ống đa giai đoạn liên quan đến ba cuộc gọi LLM riêng biệt: một để tinh chỉnh lời nhắc của người dùng, một để dịch ngôn ngữ tự nhiên sang SQL và thực hiện nó trực tiếp chống lại cơ sở dữ liệu, và một thứ ba quan trọng để lọc PII / PHI nhạy cảm từ kết quả.
Những thách thức chính như quản lý giới hạn mã thông báo LLM với các sơ đồ lớn, đảm bảo quyền riêng tư dữ liệu thông qua lọc và cải thiện sự hiểu biết nhanh chóng đòi hỏi các giải pháp lặp đi lặp lại.Trong khi tận dụng AI để tạo ra mã tăng tốc các phần của quá trình, thiết kế kiến trúc tổng thể, thực hiện logic cụ thể như ngoại lệ bộ lọc PII, tích hợp các thành phần và thử nghiệm nghiêm ngặt vẫn là những nhiệm vụ được thúc đẩy bởi con người quan trọng.
Next Steps: Exploring Retrieval-Augmented Generation (RAG)
Tỷ lệ thành công, đặc biệt là đối với các truy vấn phức tạp hơn hoặc mơ hồ hơn, cho thấy cơ hội rõ ràng để cải thiện vượt ra ngoài các kỹ thuật kỹ thuật nhanh và lọc hiện tại.
Một con đường đầy hứa hẹn mà tôi dự định khám phá để tăng độ chính xác hơn nữa làRetrieval-Augmented Generation (RAG)Thay vì chỉ dựa vào kiến thức nội bộ của LLM hoặc một cái nhìn tĩnh của sơ đồ, RAG giới thiệu một bước thu thập năng động.Trước khi tạo ra SQL, một hệ thống RAG sẽ tìm kiếm một cơ sở kiến thức chuyên ngành cho thông tin có liên quan cao đến truy vấn hiện tại của người dùng.
Trong bối cảnh NL-to-SQL này, điều này có thể liên quan đến việc thu thập:
- Thì
- Mô tả chi tiết hoặc tài liệu cho các bảng và cột cơ sở dữ liệu cụ thể được coi là có liên quan nhất với truy vấn. Thì
- Ví dụ về các câu hỏi ngôn ngữ tự nhiên tương tự đã được lập bản đồ trước đó với các đối tác SQL chính xác của họ. Thì
- Quy tắc kinh doanh có liên quan hoặc định nghĩa liên quan đến dữ liệu được yêu cầu. Thì
Những thông tin được thu thập, nhắm mục tiêu này sau đó sẽ được thêm (“tăng”) vào lời nhắc gửi đến LLM NL-to-SQL chính (MainLLM, cung cấp cho nó một bối cảnh phong phú hơn, chỉ trong thời gian. giả thuyết là bối cảnh năng động này sẽ tăng cường đáng kể sự hiểu biết của LLM và khả năng tạo ra SQL chính xác, có khả năng cung cấp những cải tiến đáng kể mà không cần các yêu cầu tập hợp dữ liệu rộng lớn của chỉnh sửa.








