






















Ushbu maqola transformatorlardan boshlanadi va uning kamchiliklarini o'rnatish modeli sifatida ko'rib chiqadi. Keyin u BERT haqida umumiy ma'lumot beradi va LLM va RAG quvurlari uchun jumlalarni joylashtirish bo'yicha eng so'nggi ilg'or bo'lgan Sentence BERT (SBERT) ga chuqur kirib boradi.
Vizual tushuntirish
Agar siz men kabi vizual odam bo'lsangiz va vizual tushuntirishni ko'rmoqchi bo'lsangiz, iltimos, ushbu videoni ko'ring:
Transformatorlar
Transformatorlarga kirish kerak emas. Ular dastlab tilni tarjima qilish vazifalari uchun ishlab chiqilgan bo'lsa-da, ular bugungi kunda deyarli barcha LLMlarning orqasida harakatlanuvchi otlardir.
Yuqori darajada ular ikkita blokdan iborat - kodlovchi va dekoder. Kodlovchi bloki kirishni qabul qiladi va matritsa tasvirini chiqaradi. Dekoder bloki oxirgi kodlovchining chiqishini oladi va chiqishni ishlab chiqaradi. Kodlovchi va dekoder bloklari bir nechta qatlamlardan iborat bo'lishi mumkin, garchi asl transformatorda har bir blokda 6 ta qatlam mavjud.


Barcha qatlamlar ko'p boshli o'z-o'ziga e'tibordan iborat. Shu bilan birga, kodlovchi va dekoder o'rtasidagi yagona farq - kodlovchining chiqishi dekoderning har bir qatlamiga beriladi. Diqqat qatlamlari nuqtai nazaridan, dekoder diqqat qatlamlari maskalanadi. Shunday qilib, har qanday pozitsiyadagi chiqish oldingi pozitsiyalardagi chiqishga ta'sir qiladi.
Kodlovchi va dekoder bloki bundan tashqari qatlam normasi va oldinga uzatiladigan neyron tarmoq qatlamlaridan iborat.
Tokenlarni mustaqil ravishda qayta ishlaydigan RNN yoki LSTM kabi oldingi modellardan farqli o'laroq, transformatorlarning kuchi ularning har bir token kontekstini butun ketma-ketlikka nisbatan qo'lga kiritish qobiliyatidadir. Shunday qilib, u tilni qayta ishlash uchun mo'ljallangan har qanday oldingi arxitektura bilan solishtirganda juda ko'p kontekstni qamrab oladi.
Transformerlar bilan nima yomon?
Transformatorlar bugungi kunda AI inqilobini boshqarayotgan eng muvaffaqiyatli arxitekturalardir. Shunday qilib, agar cheklovlarni aniqlasam, menga eshik ko'rsatilishi mumkin. Biroq, aslida, hisoblash uchun qo'shimcha xarajatlarni kamaytirish uchun uning diqqat qatlamlari faqat o'tgan tokenlarga murojaat qilish uchun mo'ljallangan. Bu ko'pchilik vazifalar uchun yaxshi. Ammo savol-javob kabi vazifa uchun etarli bo'lmasligi mumkin. Quyidagi misolni olaylik.
Jon bayramga Milo bilan keldi. Milo ziyofatda juda xursand bo'ldi. U go'zal, mo'ynali oq mushuk.
Aytaylik, “Milo Jon bilan ziyofatda ichganmi?” degan savolni beramiz. Yuqoridagi misoldagi dastlabki 2 jumlaga asoslanib, LLM javob berishi ehtimoldan yiroq: "Milo juda ko'p zavqlanganini hisobga olsak, Milo ziyofatda ichganligini ko'rsatadi."
Biroq, oldinga kontekst bilan o'qitilgan model 3-jumladan xabardor bo'ladi, ya'ni "U chiroyli, do'stona mushuk ". Shunday qilib, "Milo mushuk, shuning uchun u ziyofatda ichgan bo'lishi dargumon", deb javob berdi.
Bu faraziy misol bo'lsa-da, siz g'oyani olasiz. Savol-javob vazifasida oldinga va orqaga kontekstni o'rganish hal qiluvchi ahamiyatga ega bo'ladi. Bu erda BERT modeli paydo bo'ladi.
BERT
BERT "Transformatorlardan ikki yo'nalishli kodlovchi tasvirlari" degan ma'noni anglatadi. Nomidan ko'rinib turibdiki, u Transformers-ga asoslangan va u oldinga va orqaga kontekstni o'z ichiga oladi. Dastlab u savollarga javob berish va umumlashtirish kabi vazifalar uchun nashr etilgan bo'lsa-da, u ikki tomonlama tabiati tufayli kuchli o'rnatishlarni yaratish imkoniyatiga ega.
BERT modeli
BERT - bu ketma-ketlikda yig'ilgan transformator enkoderlaridan boshqa narsa emas. Yagona farq shundaki, BERT ikki tomonlama o'z-o'ziga e'tiborni ishlatadi, vanil transformatori esa cheklangan o'z-o'ziga e'tiborni ishlatadi, bunda har bir token faqat chap tomondagi kontekstga murojaat qilishi mumkin.
Eslatma: ketma-ketlik va jumla. BERT modeli bilan ishlashda chalkashmaslik uchun terminologiya haqida eslatma. Gap nuqta bilan ajratilgan so'zlar turkumidir. Ketma-ketlik har qanday sonli jumlalar bo'lishi mumkin.
BERTni tushunish uchun savolga javob berish misolini olaylik. Savol-javob kamida ikkita jumlani o'z ichiga olganligi sababli, BERT <savol-javob> formatidagi juft jumlalarni qabul qilish uchun mo'ljallangan. Bu ketma-ketlikning boshlanishini ko'rsatish uchun boshida o'tkazilgan [CLS] kabi ajratuvchi tokenlarga olib keladi. [SEP] tokeni keyin savol va javobni ajratish uchun ishlatiladi.
Shunday qilib, oddiy kiritish endi quyidagi rasmda ko'rsatilganidek, [CLS]<question>[SEP]<answer>[SEP] bo'ladi.


A va B ikkita jumlalar [CLS] va [SEP] tokenlarini kiritgandan so'ng WordPiece o'rnatish modeli orqali o'tkaziladi. Bizda ikkita jumla borligi sababli, ularni farqlash uchun modelga qo'shimcha joylashtirish kerak. Bu segment va pozitsiyalarni joylashtirish shaklida keladi.
Quyida yashil rangda ko'rsatilgan segmentlarni joylashtirish kirish tokenlari A yoki B jumlaga tegishli ekanligini ko'rsatadi. Keyin har bir tokenning ketma-ketlikdagi o'rnini ko'rsatadigan joylashuvni o'rnatish keladi.


Modelning kirish ko'rinishini ko'rsatadigan BERT qog'ozidan olingan rasm.
Barcha uchta o'rnatish birlashtirilib, oldingi rasmda ko'rsatilganidek, ikki tomonlama bo'lgan BERT modeliga beriladi. U bizga har bir token uchun natijalarni berishdan oldin nafaqat oldingi kontekstni, balki orqa kontekstni ham qamrab oladi.
Treningdan oldingi BERT
BERT modelini ikkita nazoratsiz vazifa yordamida oldindan tayyorlashning ikkita usuli mavjud:
Niqoblangan til modeli (MLM). Bu erda biz ketma-ketlikdagi tokenlarning bir qismini maskalaymiz va modelga niqoblangan tokenlarni bashorat qilishiga imkon beramiz. Bu, shuningdek, yopish vazifasi sifatida ham tanilgan. Amalda, tokenlarning 15% bu vazifa uchun maskalanadi.
Keyingi jumlani bashorat qilish (NSP). Bu erda biz modelni ketma-ketlikdagi keyingi jumlani bashorat qilamiz. Qachonki jumla keyingi gap bo'lsa, biz
IsNextyorlig'idan foydalanamiz va u bo'lmasa,NotNextyorlig'idan foydalanamiz.



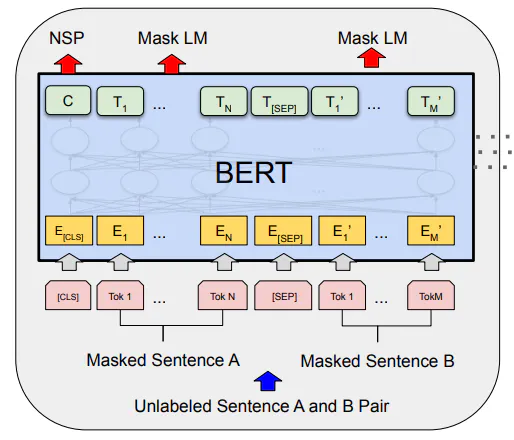
Qog'ozdagi yuqoridagi rasmdan ko'rinib turibdiki, birinchi chiqish tokeni NSP vazifasi uchun ishlatiladi va o'rtadagi maskalangan tokenlar MLM vazifasi uchun ishlatiladi.
Biz token darajasida mashq qilayotganimiz sababli, har bir kirish tokeni chiqish tokenini ishlab chiqaradi. Har qanday tasniflash vazifasida bo'lgani kabi, modelni o'rgatish uchun o'zaro entropiya yo'qolishi ishlatiladi.
BERT bilan nima bo'ldi?
BERT ham oldinga, ham orqaga kontekstni qo'lga kiritishda yaxshi bo'lishi mumkin bo'lsa-da, minglab jumlalar orasidagi o'xshashlikni topish uchun eng mos kelmasligi mumkin. Keling, 10 000 ta jumladan iborat katta to'plamdagi eng o'xshash jumlalarni topish vazifasini ko'rib chiqaylik. Boshqacha qilib aytadigan bo'lsak, biz 10 000 ta jumladan A jumlasiga eng o'xshash jumlani "qayta olishni" xohlaymiz.
Buning uchun biz 10 000 dan 2 ta jumlaning har qanday kombinatsiyasini juftlashtirishimiz kerak. Bu n * (n - 1) / 2 = 4,999,500 juft bo'ladi! Jin ursin, bu kvadratik murakkablik. BERT modeliga o'rnatishlarni yaratish va bu taqqoslashni hal qilish uchun 65 soat kerak bo'ladi.
Oddiy qilib aytganda, BERT modeli o'xshashlikni qidirish uchun eng yaxshisi emas. Ammo qidirish va o'xshashlikni qidirish har qanday RAG quvurining markazida. Yechim SBERT bilan bog'liq.
SBERT - jumla darajasi BERT
BERTning cheklanishi asosan uning oʻzaro kodlovchi arxitekturasidan kelib chiqadi, bunda biz ikkita jumlani ketma-ketlikda [SEP] tokeni bilan birga beramiz. Agar har bir jumla alohida ko'rib chiqilsa, biz o'rnatishlarni oldindan hisoblashimiz va kerak bo'lganda va shunga o'xshash hisoblash uchun to'g'ridan-to'g'ri foydalanishimiz mumkin edi. Bu aynan BERT yoki SBERT jumlasining qisqacha taklifi.
SBERT Siam tarmog'ini BERT arxitekturasi bilan tanishtiradi. Bu so'z egizak yoki chambarchas bog'liq degan ma'noni anglatadi.


Siam tilining ma'nosi dictionary.com dan olingan
Shunday qilib, SBERT-da biz "egizaklar" bilan bir xil BERT tarmog'iga egamiz. Model ular bilan ketma-ket ishlash o'rniga birinchi jumladan keyin ikkinchi jumlani joylashtiradi.
Eslatma: Siam tarmoqlarini tasavvur qilish uchun 2 ta tarmoqni yonma-yon chizish odatiy holdir. Ammo amalda bu bitta tarmoq ikki xil kirishni oladi.
SBERT arxitekturasi
Quyida SBERT arxitekturasining umumiy ko'rinishini beruvchi diagramma keltirilgan.


Yo'qotish uchun tasniflash maqsadi bilan Siam tarmoq arxitekturasi. Ikkala filialdan U va V chiqishlari ularning farqi bilan birlashtiriladi
.
Birinchidan, biz SBERT BERTdan keyin tez orada birlashtiruvchi qatlamni joriy qilganini payqashimiz mumkin. Bu hisoblashni kamaytirish uchun BERTning chiqishi hajmini kamaytiradi. BERT odatda 512 X 768 o'lchamdagi chiqishlarni ishlab chiqaradi. Birlashtiruvchi qatlam buni 1 X 768 ga qisqartiradi. O'rtacha va maksimal birlashma ishlayotgan bo'lsa-da, standart birlashtirish ma'nosini anglatadi.
Keyinchalik, SBERT BERTdan ajralib turadigan o'quv yondashuvini ko'rib chiqaylik.
Oldindan tayyorgarlik
SBERT modelni o'qitishning uchta usulini taklif qiladi. Keling, ularning har birini ko'rib chiqaylik.
Tabiiy til xulosasi (NLI) - tasniflash maqsadi
SBERT buning uchun Stenford Natural Language Inference (SNLI) va ko'p janrli NLI ma'lumotlar to'plamlarida yaxshi sozlangan. SNLI 570K jumla juftlaridan iborat va MNLI 430Kga ega. Bu juftliklar 3 ta belgidan biriga olib keladigan asosiy (P) va gipotezaga (H) ega:
- Eltailment - asos gipotezani taklif qiladi
- Neytral - asos va gipoteza haqiqat bo'lishi mumkin, lekin bir-biriga bog'liq emas
- Qarama-qarshilik - asos va gipoteza bir-biriga zid
Ikkita P va H jumlalarini hisobga olgan holda, SBERT modeli ikkita U va V chiqishini hosil qiladi. Keyin ular (U, V va |U — V|) sifatida birlashtiriladi.
Birlashtirilgan chiqish SBERTni tasniflash maqsadi bilan o'qitish uchun ishlatiladi. Ushbu birlashtirilgan chiqish 3 sinf chiqishi (Eltailment, Neytral va Contradiction) bilan Feed Forward neyron tarmog'iga beriladi. Softmax cross-entry boshqa tasniflash topshirig'iga o'xshash mashg'ulotlar uchun ishlatiladi.
Gapning o'xshashligi - regressiya maqsadi
U va V ni birlashtirish o'rniga, biz to'g'ridan-to'g'ri ikkita vektor o'rtasidagi kosinus o'xshashligini hisoblaymiz. Har qanday standart regressiya muammosiga o'xshab, biz regressiyaga o'rgatish uchun o'rtacha kvadrat xatolikdan foydalanamiz. Xulosa qilish paytida har qanday ikkita jumlani solishtirish uchun bir xil tarmoqdan bevosita foydalanish mumkin. SBERT ikkala jumla qanchalik o'xshashligi haqida ball beradi.
Uchlik o'xshashligi - Triplet maqsadi
Uchlik o'xshashlik maqsadi birinchi marta yuzni aniqlashda joriy qilingan va asta-sekin matn va robototexnika kabi sun'iy intellektning boshqa sohalariga moslashtirildi.
Bu erda SBERTga 2 ta o'rniga 3 ta kirish beriladi - langar, ijobiy va salbiy. Buning uchun ishlatiladigan ma'lumotlar to'plami mos ravishda tanlanishi kerak. Uni yaratish uchun biz har qanday matn ma'lumotlarini tanlashimiz va ikkita ketma-ket jumlani ijobiy ta'sir sifatida tanlashimiz mumkin. Keyin boshqa xatboshidan tasodifiy jumlani salbiy namunani tanlang.
Keyin uchlik yo'qotish musbatning langarga qanchalik yaqinligini va salbiyga qanchalik yaqinligini solishtirish orqali hisoblanadi.


BERT va SBERTga kirish bilan keling, ushbu modellar yordamida har qanday berilgan jumla(lar)ni qanday qilib kiritish mumkinligini tushunish uchun tezkor amaliy mashg'ulotlarni bajaramiz.
Amaliy SBERT
Hatto nashr etilgan kundan boshlab, sentence-transformer SBERT uchun rasmiy kutubxona mashhurlikka erishdi va etuklashdi. RAG uchun ishlab chiqarishdan foydalanish holatlarida foydalanish uchun etarlicha yaxshi. Shunday qilib, keling, uni qutidan tashqarida ishlataylik.
Boshlash uchun yangi Python muhitida o'rnatishdan boshlaylik.
!pip install sentence-transformers
Kutubxonadan yuklashimiz mumkin bo'lgan SBERT modelining bir nechta o'zgarishlari mavjud. Keling, illyustratsiya uchun modelni yuklaymiz.
from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens')
Biz shunchaki jumlalar ro'yxatini yaratishimiz va o'rnatishlarni yaratish uchun modelning encode funktsiyasini chaqirishimiz mumkin. Bu juda oddiy!
sentences = [ "The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium.", ] embeddings = model.encode(sentences) print(embeddings.shape)
Va biz quyida joylashgan 1 qatordan foydalanib, joylashtirishlar o'rtasidagi o'xshashlik ballarini topamiz:
similarities = model.similarity(embeddings, embeddings) print(similarities)
E'tibor bering, xuddi shu jumla o'rtasidagi o'xshashlik kutilganidek 1 ga teng:
tensor([[1.0000, 0.6660, 0.1046], [0.6660, 1.0000, 0.1411], [0.1046, 0.1411, 1.0000]])Xulosa
O'rnatish RAG quvurining eng yaxshi ishlashi uchun muhim va asosiy qadamdir. Umid qilamanki, bu foydali bo'ldi va biz har safar jumla transformatorlarini qutidan tashqarida ishlatganimizda, kaput ostida nima sodir bo'layotgani haqida ko'zingizni ochdi.
RAG va uning ichki ishi va amaliy qo'llanmalar haqidagi kelgusi maqolalarni kuzatib boring.




