






















Questo articolo inizia con i trasformatori e ne esamina le carenze come modello di embedding. Quindi fornisce una panoramica di BERT e approfondimenti su Sentence BERT (SBERT), che è lo stato dell'arte negli embedding di frasi per LLM e pipeline RAG.
Spiegazione visiva
Se sei una persona visiva come me e desideri vedere una spiegazione visiva, guarda questo video:
Trasformatori
I Transformers non hanno bisogno di presentazioni. Sebbene inizialmente fossero stati progettati per compiti di traduzione linguistica, oggi sono i cavalli trainanti di quasi tutti gli LLM.
Ad alto livello, sono composti da due blocchi: l'encoder e il decoder. Il blocco encoder accetta l'input e restituisce una rappresentazione a matrice. Il blocco decoder accetta l'output dell'ultimo encoder e produce l'output. I blocchi encoder e decoder possono essere composti da diversi strati, sebbene il trasformatore originale abbia 6 strati in ogni blocco.


Tutti gli strati sono composti da auto-attenzione multi-testa. Tuttavia, l'unica differenza tra l'encoder e il decoder è che l'output dell'encoder viene immesso in ogni strato del decoder. In termini di strati di attenzione, gli strati di attenzione del decoder sono mascherati. Quindi, l'output in qualsiasi posizione è influenzato dall'output nelle posizioni precedenti.
Il blocco codificatore e decodificatore è ulteriormente composto da strati di norme di livello e strati di rete neurale feed-forward.
A differenza dei modelli precedenti come RNN o LSTM che elaboravano i token in modo indipendente, la potenza dei trasformatori risiede nella loro capacità di catturare il contesto di ogni token rispetto all'intera sequenza. Pertanto, cattura molto contesto rispetto a qualsiasi precedente architettura progettata per l'elaborazione del linguaggio.
Cosa c'è che non va nei Transformers?
I trasformatori sono le architetture di maggior successo che stanno guidando la rivoluzione dell'intelligenza artificiale oggi. Quindi, potrei essere messo alla porta se ne individuassi i limiti. Tuttavia, in realtà, per ridurre il sovraccarico computazionale, i suoi livelli di attenzione sono progettati solo per occuparsi dei token passati. Questo va bene per la maggior parte delle attività. Ma potrebbe non essere sufficiente per un'attività come la risposta a domande. Prendiamo l'esempio seguente.
John è venuto con Milo alla festa. Milo si è divertito molto alla festa. È un bellissimo gatto bianco con la pelliccia.
Diciamo di porci la domanda: "Milo ha bevuto alla festa con John?" Basandoci solo sulle prime due frasi dell'esempio precedente, è molto probabile che l'LLM risponda: "Dato che Milo si è divertito molto, significa che Milo ha bevuto alla festa".
Tuttavia, un modello addestrato con il contesto avanzato sarebbe consapevole della terza frase che è, "È un gatto bellissimo e amichevole". E quindi, risponderebbe, "Milo è un gatto, quindi è improbabile che abbia bevuto alla festa".
Sebbene questo sia un esempio ipotetico, hai capito l'idea. In un compito di domanda-risposta, imparare sia il contesto in avanti che quello all'indietro diventa cruciale. È qui che entra in gioco il modello BERT.
BERT
BERT sta per Bidirectional Encoder Representations from Transformers. Come suggerisce il nome, si basa su Transformers e incorpora sia il contesto forward che backward. Sebbene sia stato inizialmente pubblicato per attività come la risposta alle domande e la sintesi, ha il potenziale per produrre potenti embedding grazie alla sua natura bidirezionale.
Modello BERT
BERT non è altro che i codificatori del trasformatore impilati insieme in sequenza. L'unica differenza è che BERT usa l'auto-attenzione bidirezionale , mentre il trasformatore vanilla usa l'auto-attenzione vincolata in cui ogni token può prestare attenzione solo al contesto alla sua sinistra.
Nota: sequenza vs frase. Solo una nota sulla terminologia per evitare confusione quando si ha a che fare con il modello BERT. Una frase è una serie di parole separate da un punto. Una sequenza potrebbe essere un numero qualsiasi di frasi impilate insieme.
Per comprendere BERT, prendiamo l'esempio della risposta alle domande. Poiché la risposta alle domande comporta un minimo di due frasi, BERT è progettato per accettare una coppia di frasi nel formato <domanda-risposta>. Ciò porta a token separatori come [CLS] passati all'inizio per indicare l'inizio della sequenza. Il token [SEP] viene quindi utilizzato per separare la domanda e la risposta.
Quindi, un input semplice diventa ora [CLS]<domanda>[SEP]<risposta>[SEP] come mostrato nella figura sottostante.


Le due frasi A e B vengono passate attraverso il modello di incorporamento di WordPiece dopo aver incluso i token [CLS] e [SEP]. Poiché abbiamo due frasi, il modello necessita di incorporamenti aggiuntivi per differenziarle. Ciò avviene sotto forma di incorporamenti di segmento e posizione.
L'incorporamento del segmento mostrato in verde qui sotto indica se i token di input appartengono alla frase A o B. Poi c'è l'incorporamento della posizione che indica la posizione di ciascun token nella sequenza.


Figura tratta dal documento BERT che mostra la rappresentazione di input del modello.
Tutti e tre gli embedding vengono sommati insieme e immessi nel modello BERT che è bidirezionale come mostrato nella figura precedente. Cattura non solo il contesto forward ma anche quello backward prima di fornirci gli output per ogni token.
Pre-addestramento BERT
Esistono due modi in cui il modello BERT viene pre-addestrato utilizzando due attività non supervisionate:
Modello di linguaggio mascherato (MLM). Qui mascheriamo una parte della percentuale di token nella sequenza e lasciamo che il modello preveda i token mascherati. È anche noto come cloze task. In pratica, il 15% dei token è mascherato per questo task.
Next Sentence Prediction (NSP). Qui, facciamo in modo che il modello preveda la frase successiva nella sequenza. Ogni volta che la frase è quella effettiva successiva, utilizziamo l'etichetta
IsNexte quando non lo è, utilizziamo l'etichettaNotNext.



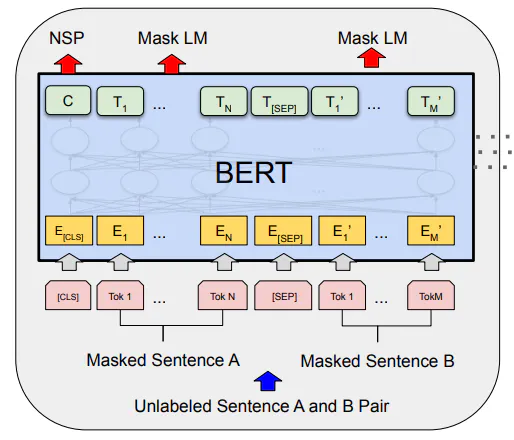
Come si può vedere dalla figura soprastante del documento, il primo token di output viene utilizzato per l'attività NSP, mentre i token al centro, che sono mascherati, vengono utilizzati per l'attività MLM.
Poiché stiamo addestrando a livello di token, ogni token di input produce un token di output. Come per qualsiasi attività di classificazione, la perdita di entropia incrociata viene utilizzata per addestrare il modello.
Cosa c'è che non va in BERT?
Sebbene BERT possa essere utile per catturare sia il contesto in avanti che quello all'indietro, potrebbe non essere il più adatto a trovare somiglianze tra migliaia di frasi. Consideriamo il compito di trovare la coppia di frasi più simili in una grande raccolta di 10.000 frasi. In altre parole, vorremmo "recuperare" la frase più simile alla frase A tra 10.000 frasi.
Per fare questo, dobbiamo accoppiare ogni possibile combinazione di 2 frasi da 10.000. Ciò sarebbe n * (n — 1) / 2 = 4.999.500 coppie! Accidenti, questa è complessità quadratica. Ci vorranno 65 ore al modello BERT per creare gli embedding e risolvere questo confronto.
In parole povere, il modello BERT non è il migliore per la ricerca di similarità. Ma il recupero e la ricerca di similarità sono al centro di qualsiasi pipeline RAG. La soluzione sta in SBERT.
SBERT — Livello frase BERT
La limitazione di BERT deriva in gran parte dalla sua architettura cross-encoder in cui inseriamo due frasi insieme in sequenza con un token [SEP] in mezzo. Se solo ogni frase dovesse essere trattata separatamente, potremmo pre-calcolare gli embedding e usarli direttamente per calcolare in modo simile quando e come necessario. Questa è esattamente la proposizione della frase BERT o SBERT in breve.
SBERT introduce la rete siamese nell'architettura BERT. La parola significa gemello o strettamente correlato.


Il significato di Siamese è tratto da dictionary.com
Quindi, in SBERT abbiamo la stessa rete BERT connessa come "gemelli". Il modello incorpora la prima frase seguita dalla seconda invece di gestirle in sequenza.
Nota: è una pratica abbastanza comune disegnare 2 reti affiancate per visualizzare le reti siamesi. Ma in pratica, è una singola rete che accetta due input diversi.
Architettura SBERT
Di seguito è riportato uno schema che fornisce una panoramica dell'architettura SBERT.


L'architettura di rete siamese con l'obiettivo di classificazione per la perdita. Gli output U e V dai due rami sono concatenati insieme alla loro differenza
.
Innanzitutto, possiamo notare che SBERT introduce un livello di pooling subito dopo BERT. Ciò riduce la dimensione dell'output di BERT per ridurre il calcolo. BERT generalmente produce output con dimensioni 512 X 768. Il livello di pooling riduce questo a 1 X 768. Il pooling predefinito è mean, anche se il pooling average e max funzionano.
Ora diamo un'occhiata all'approccio formativo in cui SBERT si differenzia da BERT.
Pre-allenamento
SBERT propone tre modi per addestrare il modello. Diamo un'occhiata a ciascuno di essi.
Inferenza del linguaggio naturale (NLI) — Obiettivo di classificazione
SBERT è ottimizzato per questo sui dataset Stanford Natural Language Inference (SNLI) e Multi-Genre NLI. SNLI è composto da 570K coppie di frasi e MNLI ne ha 430K. Le coppie hanno una premessa (P) e un'ipotesi (H) che portano a una delle 3 etichette:
- Eltailment — la premessa suggerisce l'ipotesi
- Neutrale: la premessa e l'ipotesi potrebbero essere vere ma non necessariamente correlate
- Contraddizione: premessa e ipotesi si contraddicono a vicenda
Date le due frasi P e H, il modello SBERT produce due output U e V. Questi vengono poi concatenati come (U, V e |U — V|).
L'output concatenato viene utilizzato per addestrare SBERT con l'obiettivo di classificazione. Questo output concatenato viene immesso in una rete neurale Feed Forward con 3 output di classe (Eltailment, Neutral e Contradiction). Softmax cross-entry viene utilizzato per l'addestramento in modo simile a come ci alleniamo per qualsiasi altro compito di classificazione.
Somiglianza delle frasi — Obiettivo della regressione
Invece di concatenare U e V, calcoliamo direttamente una similarità del coseno tra i due vettori. Similmente a qualsiasi problema di regressione standard, utilizziamo una perdita di errore quadratico medio per addestrare la regressione. Durante l'inferenza, la stessa rete può essere utilizzata direttamente per confrontare due frasi qualsiasi. SBERT fornisce un punteggio su quanto sono simili le due frasi.
Somiglianza di tripletta — Obiettivo di tripletta
L'obiettivo di similarità di triplette è stato introdotto per la prima volta nel riconoscimento facciale e gradualmente è stato adattato ad altri ambiti dell'intelligenza artificiale, come il testo e la robotica.
Qui vengono forniti 3 input a SBERT anziché 2: un'ancora, un positivo e un negativo. Il set di dati utilizzato per questo dovrebbe essere scelto di conseguenza. Per crearlo, possiamo scegliere qualsiasi dato di testo e scegliere due frasi consecutive come implicazione positiva. Quindi scegliere una frase casuale da un paragrafo diverso come campione negativo.
Si calcola quindi una perdita di tripletta confrontando la vicinanza del positivo all'ancora con quella del negativo.


Dopo questa introduzione a BERT e SBERT, facciamo una rapida esercitazione pratica per capire come possiamo ottenere gli embedding di qualsiasi frase utilizzando questi modelli.
SBERT pratico
Anche dalla sua pubblicazione, la libreria ufficiale per SBERT, che è sentence-transformer ha guadagnato popolarità e maturato. È abbastanza buona da essere usata in casi d'uso di produzione per RAG. Quindi usiamola subito.
Per iniziare, iniziamo con l'installazione in un nuovo ambiente Python.
!pip install sentence-transformers
Ci sono diverse varianti del modello SBERT che possiamo caricare dalla libreria. Carichiamo il modello per l'illustrazione.
from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens')
Possiamo semplicemente creare un elenco di frasi e invocare la funzione encode del modello per creare gli embedding. È così semplice!
sentences = [ "The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium.", ] embeddings = model.encode(sentences) print(embeddings.shape)
E possiamo trovare i punteggi di similarità tra gli embedding utilizzando la riga sottostante:
similarities = model.similarity(embeddings, embeddings) print(similarities)
Si noti che la somiglianza tra le stesse frasi è 1 come previsto:
tensor([[1.0000, 0.6660, 0.1046], [0.6660, 1.0000, 0.1411], [0.1046, 0.1411, 1.0000]])Conclusione
L'incorporamento è un passaggio cruciale e fondamentale per far funzionare al meglio la pipeline RAG. Spero che sia stato utile e che vi abbia aperto gli occhi su cosa succede sotto il cofano ogni volta che utilizziamo i trasformatori di frasi out of the box.
Restate sintonizzati per i prossimi articoli su RAG e sul suo funzionamento interno, oltre a tutorial pratici.








