
















































Jan 01, 1970
270 การอ่าน
การฝังสำหรับ RAG - ภาพรวมที่สมบูรณ์
นานเกินไป; อ่าน
การฝังเป็นขั้นตอนที่สำคัญและพื้นฐานในการสร้าง Retrieval Augmented Generation (RAG) BERT และ SBERT เป็นโมเดลการฝังที่ทันสมัย Sententce transformers คือไลบรารี Python ที่นำโมเดลทั้งสองมาใช้ บทความนี้จะเจาะลึกทั้งทฤษฎีและการปฏิบัติจริงบทความนี้เริ่มต้นด้วยตัวแปลงและพิจารณาข้อบกพร่องของตัวแปลงในฐานะโมเดลการฝังตัว จากนั้นจะสรุปภาพรวมของ BERT และเจาะลึกเกี่ยวกับ Sentence BERT (SBERT) ซึ่งเป็นเทคโนโลยีล้ำสมัยสำหรับการฝังตัวประโยคสำหรับ LLM และ RAG pipeline
คำอธิบายภาพ
หากคุณเป็นคนที่ชอบดูภาพเหมือนฉันและอยากดูคำอธิบายแบบเห็นภาพ โปรดดูวิดีโอนี้:
หม้อแปลงไฟฟ้า
ไม่จำเป็นต้องมีการแนะนำเกี่ยวกับ Transformers แม้ว่าในตอนแรก Transformers ถูกออกแบบมาเพื่อการแปลภาษา แต่ในปัจจุบัน Transformers ถือเป็นม้าขับเคลื่อนเบื้องหลังหลักสูตร LLM เกือบทั้งหมด
ในระดับสูง จะประกอบด้วยบล็อกสองบล็อก ได้แก่ ตัวเข้ารหัสและตัวถอดรหัส บล็อกตัวเข้ารหัสจะรับอินพุตและส่งออกการแสดงเมทริกซ์ บล็อกตัวถอดรหัสจะรับเอาต์พุตของตัวเข้ารหัสตัวสุดท้ายและสร้างเอาต์พุต บล็อกตัวเข้ารหัสและตัวถอดรหัสอาจประกอบด้วยหลายชั้น แม้ว่าหม้อแปลงเดิมจะมี 6 ชั้นในแต่ละบล็อกก็ตาม
เลเยอร์ทั้งหมดประกอบด้วยการใส่ใจตัวเองหลายหัว อย่างไรก็ตาม ความแตกต่างเพียงอย่างเดียวระหว่างตัวเข้ารหัสและตัวถอดรหัสคือเอาต์พุตของตัวเข้ารหัสจะถูกป้อนไปยังเลเยอร์ของตัวถอดรหัสแต่ละเลเยอร์ ในแง่ของเลเยอร์การใส่ใจ เลเยอร์การใส่ใจของตัวถอดรหัสจะถูกปิดบัง ดังนั้นเอาต์พุตในตำแหน่งใดๆ ก็ตามจะได้รับอิทธิพลจากเอาต์พุตในตำแหน่งก่อนหน้า
บล็อกตัวเข้ารหัสและตัวถอดรหัสยังประกอบด้วยเลเยอร์บรรทัดฐานและเลเยอร์เครือข่ายประสาทฟีดฟอร์เวิร์ดอีกด้วย
ต่างจากโมเดลก่อนหน้าอย่าง RNN หรือ LSTM ที่ประมวลผลโทเค็นแยกกัน พลังของหม้อแปลงอยู่ที่ความสามารถในการจับบริบทของแต่ละโทเค็นโดยสัมพันธ์กับลำดับทั้งหมด ดังนั้น จึงจับบริบทได้มากเมื่อเทียบกับสถาปัตยกรรมก่อนหน้าที่ออกแบบมาสำหรับการประมวลผลภาษา
มีอะไรผิดปกติกับหม้อแปลง?
Transformers เป็นสถาปัตยกรรมที่ประสบความสำเร็จมากที่สุดที่ขับเคลื่อนการปฏิวัติ AI ในปัจจุบัน ดังนั้น ฉันอาจต้องออกจากระบบหากฉันระบุข้อจำกัดของมันได้ อย่างไรก็ตาม ตามความเป็นจริงแล้ว เพื่อลดภาระงานในการคำนวณ ชั้นความสนใจของ Transformers ได้รับการออกแบบมาให้ดูแลเฉพาะโทเค็นที่ผ่านมาเท่านั้น ซึ่งเหมาะสำหรับงานส่วนใหญ่ แต่ก็อาจไม่เพียงพอสำหรับงานอย่างการถาม-ตอบ มาดูตัวอย่างด้านล่างกัน
จอห์นมางานปาร์ตี้กับไมโล ไมโลสนุกสนานมากในงานปาร์ตี้ เขาเป็นแมวสีขาวขนฟูแสนสวย
สมมติว่าเราถามคำถามว่า “Milo ได้ดื่มที่งานปาร์ตี้กับ John หรือเปล่า” จาก 2 ประโยคแรกในตัวอย่างข้างต้น มีแนวโน้มสูงที่ LLM จะตอบว่า “เนื่องจาก Milo มีความสนุกสนานมาก แสดงว่า Milo ดื่มในงานปาร์ตี้”
อย่างไรก็ตาม โมเดลที่ได้รับการฝึกด้วยบริบทล่วงหน้าจะตระหนักถึงประโยคที่ 3 ซึ่งก็คือ “เขาเป็น แมว ที่สวยงามและเป็นมิตร” และจะตอบกลับว่า “ไมโลเป็นแมว ดังนั้นจึงไม่น่าเป็นไปได้ที่เขาจะดื่มในงานปาร์ตี้”
แม้ว่านี่จะเป็นเพียงตัวอย่างสมมติ แต่คุณก็พอจะเข้าใจแนวคิดแล้ว ในงานที่ต้องตอบคำถาม การเรียนรู้ทั้งบริบทไปข้างหน้าและข้างหลังจึงมีความสำคัญ นี่คือจุดที่โมเดล BERT เข้ามามีบทบาท
เบิร์ต
BERT ย่อมาจาก Bidirectional Encoder Representations from Transformers ตามชื่อ BERT อิงตาม Transformers และผสมผสานทั้งบริบทไปข้างหน้าและย้อนหลัง แม้ว่า BERT จะเผยแพร่ครั้งแรกสำหรับงานเช่นการตอบคำถามและการสรุป แต่ BERT มีศักยภาพในการสร้างการฝังตัวที่ทรงพลังเนื่องจากมีลักษณะทิศทางสองทาง
โมเดล BERT
BERT เป็นเพียงตัวเข้ารหัสของหม้อแปลงที่วางซ้อนกันเป็นลำดับ ความแตกต่างเพียงอย่างเดียวคือ BERT ใช้ การใส่ใจตัวเองแบบสองทิศทาง ในขณะที่หม้อแปลงแบบวานิลลาใช้การใส่ใจตัวเองแบบจำกัด ซึ่งโทเค็นแต่ละตัวสามารถใส่ใจเฉพาะบริบททางด้านซ้ายเท่านั้น
หมายเหตุ: ลำดับเทียบกับประโยค เป็นเพียงหมายเหตุเกี่ยวกับคำศัพท์เพื่อหลีกเลี่ยงความสับสนในการใช้งานโมเดล BERT ประโยคคือชุดคำที่คั่นด้วยจุด ลำดับอาจเป็นประโยคจำนวนเท่าใดก็ได้ที่ซ้อนกัน
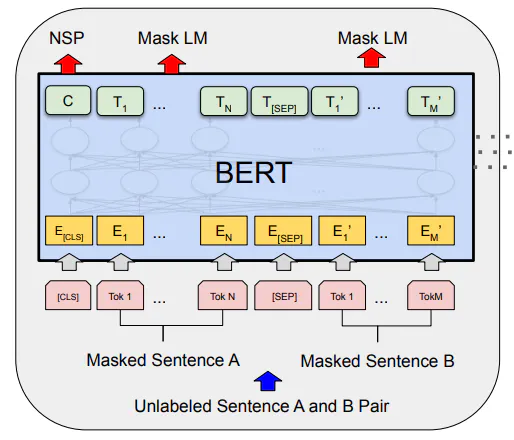
เพื่อทำความเข้าใจ BERT เรามาดูตัวอย่างการตอบคำถามกัน เนื่องจากคำถาม-คำตอบนั้นต้องมีอย่างน้อยสองประโยค BERT จึงได้รับการออกแบบมาให้รับประโยคคู่หนึ่งในรูปแบบ <คำถาม-คำตอบ> ซึ่งจะทำให้มีโทเค็นคั่น เช่น [CLS] ที่ส่งมาตอนต้นเพื่อระบุจุดเริ่มต้นของลำดับ จากนั้นจึงใช้โทเค็น [SEP] เพื่อแยกคำถามและคำตอบออกจากกัน
ดังนั้นอินพุตง่ายๆ ตอนนี้จะกลายเป็น [CLS]<คำถาม>[SEP]<คำตอบ>[SEP] ตามที่แสดงในรูปด้านล่าง
ประโยค A และ B สองประโยคจะถูกส่งผ่านโมเดลการฝัง WordPiece หลังจากรวมโทเค็น [CLS] และ [SEP] เนื่องจากเรามีประโยคสองประโยค โมเดลจึงต้องมีการฝังเพิ่มเติมเพื่อแยกความแตกต่างระหว่างประโยคทั้งสอง ซึ่งมาในรูปแบบของการฝังเซกเมนต์และตำแหน่ง
การฝังเซกเมนต์ที่แสดงเป็นสีเขียวด้านล่างนี้บ่งชี้ว่าโทเค็นอินพุตเป็นของประโยค A หรือ B จากนั้นก็มาถึงการฝังตำแหน่งซึ่งระบุตำแหน่งของแต่ละโทเค็นในลำดับ
รูปภาพที่นำมาจากเอกสาร BERT แสดงให้เห็นการแสดงอินพุตของแบบจำลอง
การฝังทั้งสามแบบจะถูกสรุปรวมกันและป้อนให้กับโมเดล BERT ซึ่งเป็นแบบทิศทางสองทางดังที่แสดงในรูปก่อนหน้านี้ โดยโมเดลจะจับไม่เฉพาะบริบทไปข้างหน้าเท่านั้น แต่ยังรวมถึงบริบทย้อนหลังด้วย ก่อนที่จะให้ผลลัพธ์สำหรับโทเค็นแต่ละตัวแก่เรา
การฝึกอบรมก่อน BERT
มีสองวิธีในการฝึกโมเดล BERT ล่วงหน้าโดยใช้สองงานที่ไม่มีการดูแล:
แบบจำลองภาษาที่ถูกปิดบัง (MLM) ที่นี่ เราจะปิดบังโทเค็นบางส่วนในลำดับ และปล่อยให้แบบจำลองทำนายโทเค็นที่ถูกปิดบัง เรียกอีกอย่างว่างาน cloze ในทางปฏิบัติ โทเค็น 15% จะถูกปิดบังเพื่องานนี้
การทำนายประโยคถัดไป (Next Sentence Prediction: NSP) ในที่นี้ เราสร้างโมเดลทำนายประโยคถัดไปในลำดับ เมื่อใดก็ตามที่ประโยคเป็นประโยคถัดไปจริง ๆ เราจะใช้ป้ายกำกับ
IsNextและเมื่อไม่ใช่ เราจะใช้ป้ายกำกับNotNext
ตามที่เห็นได้จากรูปด้านบนในเอกสาร โทเค็นเอาต์พุตแรกจะใช้สำหรับงาน NSP และโทเค็นตรงกลางซึ่งถูกปิดบังไว้จะใช้สำหรับงาน MLM
ขณะที่เรากำลังฝึกในระดับโทเค็น โทเค็นอินพุตแต่ละอันจะสร้างโทเค็นเอาต์พุตขึ้นมา เช่นเดียวกับงานการจำแนกประเภทอื่นๆ การสูญเสียระหว่างเอนโทรปีจะถูกใช้เพื่อฝึกโมเดล
BERT เป็นอะไรไป?
แม้ว่า BERT จะมีประโยชน์ในการจับบริบททั้งไปข้างหน้าและข้างหลัง แต่ก็อาจไม่เหมาะที่สุดที่จะค้นหาความคล้ายคลึงกันระหว่างประโยคหลายพันประโยค ลองพิจารณาภารกิจในการค้นหาคู่ประโยคที่คล้ายคลึงกันมากที่สุดในประโยคจำนวนมาก 10,000 ประโยค กล่าวอีกนัยหนึ่ง เราต้องการ "ดึง" ประโยคที่คล้ายกับประโยค A มากที่สุดจากประโยคทั้งหมด 10,000 ประโยค
ในการดำเนินการนี้ เราต้องจับคู่ประโยค 2 ประโยคจากทั้งหมด 10,000 ประโยคที่เป็นไปได้ทั้งหมด ซึ่งจะเท่ากับ n * (n — 1) / 2 = 4,999,500 คู่! นี่มันความซับซ้อนแบบกำลังสองชัดๆ โมเดล BERT จะใช้เวลา 65 ชั่วโมงในการสร้างการฝังและแก้ปัญหาสำหรับการเปรียบเทียบนี้
กล่าวอย่างง่ายๆ ก็คือโมเดล BERT ไม่ใช่โมเดลที่ดีที่สุดสำหรับการค้นหาความคล้ายคลึง แต่การดึงข้อมูลและการค้นหาความคล้ายคลึงถือเป็นหัวใจสำคัญของกระบวนการ RAG โซลูชันอยู่ที่ SBERT
SBERT — ระดับประโยค BERT
ข้อจำกัดของ BERT ส่วนใหญ่มาจาก สถาปัตยกรรมแบบ cross-encoder ซึ่งเราป้อนประโยคสองประโยคเข้าด้วยกันตามลำดับโดยมีโทเค็น [SEP] อยู่ตรงกลาง หากเราพิจารณาแต่ละประโยคแยกกัน เราก็สามารถคำนวณการฝังตัวล่วงหน้าและใช้การฝังตัวเหล่านั้นเพื่อคำนวณในลักษณะเดียวกันเมื่อจำเป็น นี่คือข้อเสนอของประโยค BERT หรือเรียกสั้นๆ ว่า SBERT
SBERT แนะนำ เครือข่าย Siamese ให้กับสถาปัตยกรรม BERT คำนี้หมายถึงคู่แฝดหรือมีความเกี่ยวข้องกันอย่างใกล้ชิด
ความหมายของคำว่าสยามที่นำมาจาก dictionary.com
ดังนั้น ใน SBERT เรามีเครือข่าย BERT เดียวกันที่เชื่อมต่อเป็น “ฝาแฝด” โมเดลจะฝังประโยคแรกตามด้วยประโยคที่สองแทนที่จะจัดการตามลำดับ
หมายเหตุ: การวาดเครือข่าย 2 เครือข่ายคู่กันเป็นเรื่องปกติธรรมดา แต่ในทางปฏิบัติแล้ว การวาดเครือข่ายเดียวจะรับอินพุต 2 แบบที่แตกต่างกัน
สถาปัตยกรรม SBERT
ด้านล่างนี้เป็นแผนภาพที่แสดงภาพรวมของสถาปัตยกรรม SBERT
สถาปัตยกรรมเครือข่ายสยามที่มีวัตถุประสงค์การจำแนกประเภทสำหรับการสูญเสีย เอาต์พุต U และ V จากสองสาขาจะเรียงต่อกันพร้อมกับความแตกต่าง
-
ประการแรก เราจะสังเกตได้ว่า SBERT นำเสนอเลเยอร์การรวมข้อมูลในช่วงไม่นานหลังจาก BERT เลเยอร์นี้จะลดมิติของผลลัพธ์ของ BERT เพื่อลดการคำนวณ BERT มักจะสร้างผลลัพธ์ที่มิติ 512 X 768 เลเยอร์การรวมข้อมูลจะลดมิตินี้ลงเหลือ 1 X 768 การรวมข้อมูลเริ่มต้นคือค่าเฉลี่ย แม้ว่าการรวมข้อมูลค่าเฉลี่ยและค่าสูงสุดจะใช้งานได้ก็ตาม
ต่อไปมาดูแนวทางการฝึกอบรมที่ SBERT แตกต่างจาก BERT กัน
การฝึกอบรมเบื้องต้น
SBERT เสนอวิธีฝึกโมเดลสามวิธี มาดูแต่ละวิธีกัน
การอนุมานภาษาธรรมชาติ (NLI) — วัตถุประสงค์ในการจำแนกประเภท
SBERT ได้รับการปรับแต่งให้เหมาะกับข้อมูล Stanford Natural Language Inference (SNLI) และชุดข้อมูล NLI หลายประเภทสำหรับสิ่งนี้ SNLI ประกอบด้วยคู่ประโยค 570,000 คู่ และ MNLI มี 430,000 คู่ คู่ประโยคเหล่านี้มีสมมติฐาน (P) และสมมติฐาน (H) ที่นำไปสู่หนึ่งในสามป้ายกำกับ:
- การยื่นหางออกไป — ข้อสมมติฐานชี้ให้เห็นถึงสมมติฐาน
- เป็นกลาง — ข้อสันนิษฐานและสมมติฐานอาจเป็นจริงแต่ไม่จำเป็นต้องเกี่ยวข้องกัน
- ความขัดแย้ง — ข้อสันนิษฐานและสมมติฐานขัดแย้งกัน
เมื่อกำหนดประโยคสองประโยคคือ P และ H โมเดล SBERT จะสร้างผลลัพธ์สองประโยคคือ U และ V จากนั้นจึงต่อกันเป็น (U, V และ |U — V|)
เอาต์พุตที่ต่อกันจะใช้ในการฝึก SBERT ด้วย Classification Objective เอาต์พุตที่ต่อกันนี้จะถูกส่งไปยังเครือข่ายประสาทเทียม Feed Forward ที่มีเอาต์พุตคลาส 3 คลาส (Eltailment, Neutral และ Contradiction) การเข้าแบบไขว้ของ Softmax ใช้สำหรับการฝึกที่คล้ายกับวิธีที่เราฝึกสำหรับงานการจำแนกประเภทอื่นๆ
ความคล้ายคลึงของประโยค — วัตถุประสงค์การถดถอย
แทนที่จะต่อ U และ V เข้าด้วยกัน เราจะคำนวณความคล้ายคลึงของโคไซน์ระหว่างเวกเตอร์ทั้งสองโดยตรง คล้ายกับปัญหาการถดถอยมาตรฐานอื่นๆ เราใช้การสูญเสียข้อผิดพลาดกำลังสองเฉลี่ยเพื่อฝึกการถดถอย ในระหว่างการอนุมาน เครือข่ายเดียวกันสามารถใช้เปรียบเทียบประโยคสองประโยคได้โดยตรง SBERT จะให้คะแนนว่าประโยคทั้งสองมีความคล้ายคลึงกันมากเพียงใด
ความคล้ายคลึงของไตรเพล็ต — วัตถุประสงค์ของไตรเพล็ต
วัตถุประสงค์ของความคล้ายคลึงกันของสามกลุ่มนั้นได้รับการแนะนำครั้งแรกในระบบการจดจำใบหน้า และค่อยๆ ได้รับการปรับให้เข้ากับด้านอื่นๆ ของ AI เช่น ข้อความและหุ่นยนต์
ที่นี่ อินพุต 3 ตัวจะถูกป้อนไปยัง SBERT แทนที่จะเป็น 2 ตัว — แอนคอร์ อินพุตเชิงบวก และอินพุตเชิงลบ ควรเลือกชุดข้อมูลที่ใช้อย่างเหมาะสม ในการสร้าง เราสามารถเลือกข้อมูลข้อความใดๆ ก็ได้ และเลือกประโยคที่ต่อเนื่องกันสองประโยคเป็นความหมายเชิงบวก จากนั้นเลือกประโยคสุ่มจากย่อหน้าอื่นและตัวอย่างเชิงลบ
จากนั้นจะคำนวณการสูญเสียสามเท่าโดยการเปรียบเทียบว่าค่าบวกอยู่ใกล้กับจุดยึดมากเพียงใดกับค่าลบอยู่ใกล้กับจุดยึดมากเพียงใด
จากการแนะนำ BERT และ SBERT ดังกล่าว มาลองปฏิบัติจริงอย่างรวดเร็วเพื่อทำความเข้าใจว่าเราสามารถรับการฝังประโยคที่กำหนดโดยใช้โมเดลเหล่านี้ได้อย่างไร
การฝึกปฏิบัติจริง SBERT
ตั้งแต่มีการเผยแพร่ ไลบรารีอย่างเป็นทางการสำหรับ SBERT ซึ่งเป็น sentence-transformer ก็ได้รับความนิยมและพัฒนาขึ้นเรื่อยๆ ไลบรารีนี้ดีพอที่จะใช้ในกรณีการใช้งานจริงของ RAG ดังนั้นมาลองใช้กันเลย
ในการเริ่มต้น ให้เราเริ่มด้วยการติดตั้งในสภาพแวดล้อม Python ใหม่ล่าสุด
!pip install sentence-transformers
มีโมเดล SBERT หลายรูปแบบที่เราสามารถโหลดจากไลบรารีได้ มาโหลดโมเดลนี้เพื่อประกอบการอธิบายกัน
from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens')
เราสามารถสร้างรายการประโยคและเรียกใช้ฟังก์ชัน encode ของโมเดลเพื่อสร้างเอ็มเบ็ดดิ้งได้อย่างง่ายดาย ง่ายๆ แค่นั้นเอง!
sentences = [ "The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium.", ] embeddings = model.encode(sentences) print(embeddings.shape)
และเราสามารถหาคะแนนความคล้ายคลึงระหว่างการฝังโดยใช้บรรทัดด้านล่าง 1 บรรทัด:
similarities = model.similarity(embeddings, embeddings) print(similarities)
สังเกตว่าความคล้ายคลึงกันระหว่างประโยคเดียวกันคือ 1 ตามที่คาดไว้:
tensor([[1.0000, 0.6660, 0.1046], [0.6660, 1.0000, 0.1411], [0.1046, 0.1411, 1.0000]])บทสรุป
การฝังเป็นขั้นตอนที่สำคัญและพื้นฐานในการทำให้ท่อ RAG ทำงานได้อย่างเต็มประสิทธิภาพ หวังว่าข้อมูลนี้จะเป็นประโยชน์และเปิดหูเปิดตาให้คุณเห็นว่ามีอะไรเกิดขึ้นบ้างทุกครั้งที่เราใช้ตัวแปลงประโยคตั้งแต่แกะกล่อง
ติดตามบทความที่จะเผยแพร่เร็วๆ นี้เกี่ยวกับ RAG การทำงานภายใน รวมถึงบทช่วยสอนแบบปฏิบัติจริง
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
แขวนแท็ก
บทความนี้ถูกนำเสนอใน...
เรื่องราวที่เกี่ยวข้อง
MOCKING AT FATE
#sci-fi

THE OAK EGGAR, OR BANDED MONK #non-fiction
Jan 01, 1970


