






















Este artículo comienza con los transformadores y analiza sus deficiencias como modelo de incrustación. A continuación, ofrece una descripción general de BERT y profundiza en Sentence BERT (SBERT), que es el modelo de incrustación de oraciones más avanzado para los programas de maestría en derecho y RAG.
Explicación visual
Si eres una persona visual como yo y te gustaría ver una explicación visual, mira este video:
Transformadores
Los Transformers no necesitan presentación. Aunque inicialmente fueron diseñados para tareas de traducción de idiomas, son el motor que impulsa a casi todos los LLM actuales.
En un nivel alto, se componen de dos bloques: el codificador y el decodificador. El bloque codificador toma la entrada y genera una representación matricial. El bloque decodificador toma la salida del último codificador y produce la salida. Los bloques codificador y decodificador pueden estar compuestos de varias capas, aunque el transformador original tiene 6 capas en cada bloque.


Todas las capas están compuestas de autoatención de múltiples cabezas. Sin embargo, la única diferencia entre el codificador y el decodificador es que la salida del codificador se envía a cada capa del decodificador. En términos de las capas de atención, las capas de atención del decodificador están enmascaradas. Por lo tanto, la salida en cualquier posición se ve influenciada por la salida en posiciones anteriores.
El bloque codificador y decodificador se compone además de capas de norma de capa y capas de red neuronal de avance.
A diferencia de los modelos anteriores, como las RNN o los LSTM, que procesaban los tokens de forma independiente, el poder de los transformadores reside en su capacidad de capturar el contexto de cada token con respecto a la secuencia completa. Por lo tanto, captura una gran cantidad de contexto en comparación con cualquier arquitectura anterior diseñada para el procesamiento del lenguaje.
¿Qué pasa con los Transformers?
Los transformadores son las arquitecturas más exitosas que impulsan la revolución de la IA en la actualidad. Por lo tanto, es posible que me muestren la puerta si señalo limitaciones con ellos. Sin embargo, de hecho, para reducir la sobrecarga computacional, sus capas de atención están diseñadas solo para prestar atención a los tokens pasados. Esto está bien para la mayoría de las tareas, pero puede no ser suficiente para una tarea como la de responder preguntas. Tomemos el siguiente ejemplo.
John vino con Milo a la fiesta. Milo se divirtió mucho en la fiesta. Es un hermoso gato blanco con pelo.
Digamos que hacemos la pregunta: "¿Milo bebió en la fiesta con John?". Solo con base en las primeras dos oraciones del ejemplo anterior, es muy probable que el LLM responda: "Dado que Milo se divirtió mucho, esto indica que Milo bebió en la fiesta".
Sin embargo, un modelo entrenado con contexto directo sería consciente de la tercera oración, que es: “Es un gato hermoso y amigable”. Y, por lo tanto, respondería: “Milo es un gato, por lo que es poco probable que haya bebido en la fiesta”.
Aunque se trata de un ejemplo hipotético, ya se entiende la idea. En una tarea de preguntas y respuestas, aprender tanto el contexto anterior como el posterior resulta crucial. Aquí es donde entra en juego el modelo BERT.
BERT
BERT son las siglas de Bidirectional Encoder Representations from Transformers (Representaciones de codificador bidireccional a partir de transformadores). Como sugiere el nombre, se basa en transformadores e incorpora contexto tanto hacia adelante como hacia atrás. Aunque inicialmente se publicó para tareas como la respuesta a preguntas y la realización de resúmenes, tiene el potencial de producir incrustaciones potentes debido a su naturaleza bidireccional.
Modelo BERT
BERT no es más que los codificadores del transformador apilados en secuencia. La única diferencia es que BERT utiliza autoatención bidireccional , mientras que el transformador tradicional utiliza autoatención restringida, donde cada token solo puede prestar atención al contexto que se encuentra a su izquierda.
Nota: secuencia vs. oración. Solo una nota sobre la terminología para evitar confusiones al trabajar con el modelo BERT. Una oración es una serie de palabras separadas por un punto. Una secuencia puede ser cualquier cantidad de oraciones apiladas.
Para entender BERT, tomemos como ejemplo la respuesta a una pregunta. Como la respuesta a una pregunta implica un mínimo de dos oraciones, BERT está diseñado para aceptar un par de oraciones en el formato <pregunta-respuesta>. Esto hace que se pasen tokens separadores como [CLS] al principio para indicar el comienzo de la secuencia. Luego, se utiliza el token [SEP] para separar la pregunta y la respuesta.
Entonces, una entrada simple ahora se convierte en [CLS]<pregunta>[SEP]<respuesta>[SEP] como se muestra en la siguiente figura.


Las dos oraciones A y B pasan a través del modelo de incrustación de WordPiece después de incluir los tokens [CLS] y [SEP]. Como tenemos dos oraciones, el modelo necesita incrustaciones adicionales para diferenciarlas. Esto se presenta en forma de incrustaciones de segmento y posición.
La incrustación de segmentos que se muestra en verde a continuación indica si los tokens de entrada pertenecen a la oración A o B. Luego viene la incrustación de posición, que indica la posición de cada token en la secuencia.


Figura tomada del artículo BERT que muestra la representación de entrada del modelo.
Las tres incorporaciones se suman y se envían al modelo BERT, que es bidireccional, como se muestra en la figura anterior. Captura no solo el contexto directo, sino también el contexto inverso antes de brindarnos los resultados para cada token.
BERT previo al entrenamiento
Hay dos formas en las que se entrena previamente el modelo BERT utilizando dos tareas no supervisadas:
Modelo de lenguaje enmascarado (MLM). Aquí enmascaramos una parte del porcentaje de los tokens en la secuencia y dejamos que el modelo prediga los tokens enmascarados. También se conoce como tarea cloze . En la práctica, el 15 % de los tokens se enmascaran para esta tarea.
Predicción de la siguiente oración (NSP). Aquí, hacemos que el modelo prediga la siguiente oración en la secuencia. Siempre que la oración sea la siguiente, usamos la etiqueta
IsNexty cuando no lo sea, usamos la etiquetaNotNext.



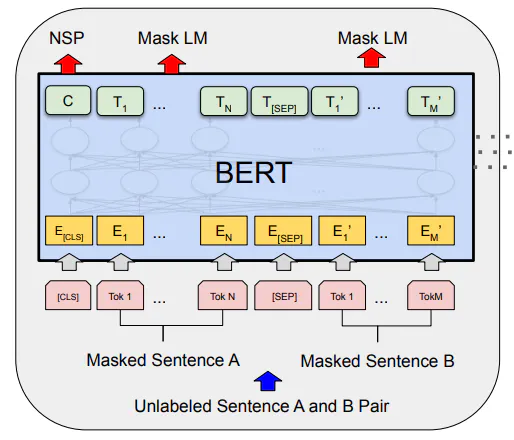
Como se puede ver en la figura anterior del documento, el primer token de salida se utiliza para la tarea NSP y los tokens en el medio que están enmascarados se utilizan para la tarea MLM.
Como estamos entrenando a nivel de token, cada token de entrada produce un token de salida. Como en cualquier tarea de clasificación, se utiliza la pérdida de entropía cruzada para entrenar el modelo.
¿Qué tiene de malo BERT?
Si bien BERT puede ser útil para capturar el contexto tanto hacia adelante como hacia atrás, es posible que no sea el más adecuado para encontrar similitudes entre miles de oraciones. Consideremos la tarea de encontrar el par de oraciones más similar en una gran colección de 10 000 oraciones. En otras palabras, nos gustaría "recuperar" la oración que sea más similar a la oración A entre 10 000 oraciones.
Para ello, necesitamos emparejar cada combinación posible de 2 oraciones de 10 000. Eso sería n * (n — 1) / 2 = 4 999 500 pares. Maldita sea, eso es complejidad cuadrática. El modelo BERT tardará 65 horas en crear incrustaciones y resolver esta comparación.
En pocas palabras, el modelo BERT no es el mejor para la búsqueda de similitudes, pero la recuperación y la búsqueda de similitudes son la base de cualquier proceso RAG. La solución está en SBERT.
SBERT — Nivel de oración BERT
La limitación de BERT se debe en gran medida a su arquitectura de codificador cruzado , en la que introducimos dos oraciones juntas en secuencia con un token [SEP] en el medio. Si tan solo se tratara cada oración por separado, podríamos calcular previamente las incrustaciones y usarlas directamente para realizar cálculos similares cuando fuera necesario. Esta es exactamente la propuesta de BERT de oraciones o SBERT, en pocas palabras.
SBERT introduce la red siamesa a la arquitectura BERT. La palabra significa gemela o estrechamente relacionada.


El significado de siamés tomado de dictionary.com
Así, en SBERT tenemos la misma red BERT conectada como “gemelos”. El modelo incorpora la primera oración seguida de la segunda en lugar de tratarlas secuencialmente.
Nota: Es una práctica bastante común dibujar dos redes una al lado de la otra para visualizar redes siamesas. Pero en la práctica, se trata de una única red que toma dos entradas diferentes.
Arquitectura SBERT
A continuación se muestra un diagrama que ofrece una descripción general de la arquitectura SBERT.


Arquitectura de red siamesa con el objetivo de clasificación de la pérdida. Las salidas U y V de las dos ramas se concatenan junto con su diferencia
.
En primer lugar, podemos observar que SBERT introduce una capa de agrupación poco después de BERT. Esto reduce la dimensión de la salida de BERT para reducir el cálculo. BERT generalmente produce salidas en dimensiones de 512 X 768. La capa de agrupación reduce esto a 1 X 768. La agrupación predeterminada es la media, aunque la agrupación promedio y máxima funcionan.
A continuación, veamos el enfoque de entrenamiento en el que SBERT se diferencia de BERT.
Pre-entrenamiento
SBERT propone tres formas de entrenar el modelo. Veamos cada una de ellas.
Inferencia del lenguaje natural (NLI): objetivo de clasificación
SBERT está optimizado para ello con los conjuntos de datos Stanford Natural Language Inference (SNLI) y Multi-Genre NLI. SNLI consta de 570 000 pares de oraciones y MNLI tiene 430 000. Los pares tienen una premisa (P) y una hipótesis (H) que conducen a una de las tres etiquetas siguientes:
- Eltailment — premisa sugiere la hipótesis
- Neutral: la premisa y la hipótesis pueden ser verdaderas, pero no necesariamente relacionadas.
- Contradicción: la premisa y la hipótesis se contradicen entre sí.
Dadas las dos oraciones P y H, el modelo SBERT produce dos salidas U y V. Estas luego se concatenan como (U, V y |U — V|).
La salida concatenada se utiliza para entrenar SBERT con el objetivo de clasificación. Esta salida concatenada se envía a una red neuronal de avance con 3 salidas de clase (Eltailment, Neutral y Contradiction). La entrada cruzada Softmax se utiliza para el entrenamiento de manera similar a como entrenamos para cualquier otra tarea de clasificación.
Similitud de oraciones: objetivo de regresión
En lugar de concatenar U y V, calculamos directamente una similitud de coseno entre los dos vectores. De manera similar a cualquier problema de regresión estándar, utilizamos una pérdida de error cuadrático medio para entrenar la regresión. Durante la inferencia, la misma red se puede utilizar directamente para comparar dos oraciones cualesquiera. SBERT otorga una puntuación según la similitud de las dos oraciones.
Similitud de tripletes: objetivo de tripletes
El objetivo de similitud de tripletes se introdujo por primera vez en el reconocimiento facial y poco a poco se fue adaptando a otras áreas de la IA, como el texto y la robótica.
Aquí se introducen 3 entradas en lugar de 2 en SBERT: un ancla, una positiva y una negativa. El conjunto de datos utilizado para esto debe elegirse en consecuencia. Para crearlo, podemos elegir cualquier dato de texto y elegir dos oraciones consecutivas como implicación positiva. Luego, elija una oración aleatoria de un párrafo diferente como muestra negativa.
Luego se calcula una pérdida de triplete comparando qué tan cerca está el positivo del ancla versus qué tan cerca está del negativo.


Con esa introducción a BERT y SBERT, hagamos una rápida práctica para entender cómo podemos obtener incrustaciones de cualquier oración dada usando estos modelos.
SBERT práctico
Desde su publicación, la biblioteca oficial de SBERT, que es sentence-transformer ha ganado popularidad y madurado. Es lo suficientemente buena como para usarse en casos de uso de producción para RAG. Así que vamos a usarla de inmediato.
Para comenzar, comencemos con la instalación en un nuevo entorno Python.
!pip install sentence-transformers
Existen varias variantes del modelo SBERT que podemos cargar desde la biblioteca. Carguemos el modelo para ilustrarlo.
from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens')
Podemos simplemente crear una lista de oraciones e invocar la función encode del modelo para crear las incrustaciones. ¡Así de simple!
sentences = [ "The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium.", ] embeddings = model.encode(sentences) print(embeddings.shape)
Y podemos encontrar los puntajes de similitud entre incrustaciones usando la siguiente línea:
similarities = model.similarity(embeddings, embeddings) print(similarities)
Nótese que la similitud entre la misma oración es 1 como se esperaba:
tensor([[1.0000, 0.6660, 0.1046], [0.6660, 1.0000, 0.1411], [0.1046, 0.1411, 1.0000]])Conclusión
La integración es un paso crucial y fundamental para que el flujo de trabajo de RAG funcione de forma óptima. Espero que haya sido útil y le haya abierto los ojos respecto de lo que sucede en segundo plano cada vez que usamos los transformadores de oraciones de forma inmediata.
Manténgase atento a los próximos artículos sobre RAG y su funcionamiento interno, junto con tutoriales prácticos también.








