






















تبدأ هذه المقالة بالمحولات وتتناول عيوبها كنموذج تضمين. ثم تقدم نظرة عامة على BERT وتتعمق في Sentence BERT (SBERT) وهو أحدث ما توصلت إليه التكنولوجيا في تضمين الجمل لخطوط أنابيب LLMs وRAG.
شرح مرئي
إذا كنت شخصًا بصريًا مثلي وترغب في مشاهدة شرح مرئي، فيرجى الاطلاع على هذا الفيديو:
محولات
لا تحتاج المحولات إلى مقدمة. ورغم أنها صُممت في البداية لمهام ترجمة اللغات، إلا أنها تشكل المحرك الرئيسي وراء كل برامج الماجستير في القانون اليوم.
على مستوى عالٍ، تتكون هذه المحولات من كتلتين - المشفر وفك التشفير. تأخذ كتلة المشفر المدخلات وتخرج تمثيلًا مصفوفيًا. تأخذ كتلة فك التشفير مخرجات المشفر الأخير وتنتج المخرجات. يمكن أن تتكون كتلتا المشفر وفك التشفير من عدة طبقات، على الرغم من أن المحول الأصلي يحتوي على 6 طبقات في كل كتلة.


تتكون جميع الطبقات من انتباه ذاتي متعدد الرؤوس. ومع ذلك، فإن الاختلاف الوحيد بين المشفر وفك التشفير هو أن خرج المشفر يتم تغذيته إلى كل طبقة من فك التشفير. من حيث طبقات الانتباه، تكون طبقات انتباه فك التشفير مقنعة. وبالتالي، يتأثر الإخراج في أي موضع بالإخراج في المواضع السابقة.
تتكون كتلة التشفير وفك التشفير أيضًا من طبقات القاعدة والشبكة العصبية الأمامية.
على عكس النماذج السابقة مثل RNNs أو LSTMs التي كانت تعالج الرموز بشكل مستقل، فإن قوة المحولات تكمن في قدرتها على التقاط سياق كل رمز فيما يتعلق بالتسلسل بأكمله. وبالتالي، فإنها تلتقط قدرًا كبيرًا من السياق مقارنة بأي بنية سابقة مصممة لمعالجة اللغة.
ما هو الخطأ في المحولات؟
تُعَد المحولات أكثر الهياكل المعمارية نجاحًا والتي تقود ثورة الذكاء الاصطناعي اليوم. لذا، قد يُطلَب مني الخروج إذا حددت القيود التي قد تعيبها. ولكن في واقع الأمر، لتقليل التكاليف الحسابية، تم تصميم طبقات الانتباه الخاصة بها فقط للانتباه إلى الرموز السابقة. وهذا جيد بالنسبة لمعظم المهام. ولكن قد لا يكون كافيًا لمهمة مثل الإجابة على الأسئلة. دعنا نأخذ المثال أدناه.
حضر جون مع ميلو إلى الحفلة. استمتع ميلو كثيرًا بالحفلة. إنه قط أبيض جميل ذو فراء.
لنفترض أننا نطرح السؤال التالي: "هل شرب ميلو في الحفلة مع جون؟" بناءً على الجملتين الأوليين في المثال أعلاه، فمن المرجح أن يجيب LLM، "نظرًا لأن ميلو استمتع كثيرًا، فهذا يشير إلى أن ميلو شرب في الحفلة".
ومع ذلك، فإن النموذج الذي تم تدريبه باستخدام السياق المتقدم سوف يكون على دراية بالجملة الثالثة التي تقول "إنه قط جميل وودود". وبالتالي، سوف يجيب، "ميلو قط، ومن غير المرجح أن يكون قد شرب في الحفلة".
على الرغم من أن هذا مثال افتراضي، إلا أنك فهمت الفكرة. ففي مهمة الإجابة على الأسئلة، يصبح تعلم السياق الأمامي والخلفي أمرًا بالغ الأهمية. وهنا يأتي دور نموذج BERT.
بيرت
BERT هو اختصار لـ Bidirectional Encoder Representations from Transformers (تمثيلات الترميز ثنائية الاتجاه من المحولات). وكما يوحي الاسم، فهو يعتمد على المحولات، ويشتمل على سياق أمامي وخلفي. ورغم أنه نُشر في البداية لمهام مثل الإجابة على الأسئلة والتلخيص، إلا أنه يتمتع بالقدرة على إنتاج تضمينات قوية بسبب طبيعته ثنائية الاتجاه.
نموذج بيرت
لا يعد BERT أكثر من ترميزات المحولات المكدسة معًا في تسلسل. والفرق الوحيد هو أن BERT يستخدم الانتباه الذاتي ثنائي الاتجاه ، بينما يستخدم المحول العادي الانتباه الذاتي المقيد حيث لا يمكن لكل رمز الانتباه إلا إلى السياق الموجود على يساره.
ملاحظة: التسلسل مقابل الجملة. مجرد ملاحظة حول المصطلحات لتجنب الارتباك أثناء التعامل مع نموذج BERT. الجملة عبارة عن سلسلة من الكلمات مفصولة بنقطة. يمكن أن يكون التسلسل أي عدد من الجمل مكدسة معًا.
لفهم BERT، دعنا نأخذ مثال الإجابة على السؤال. نظرًا لأن الإجابة على السؤال تتضمن جملتين على الأقل، فإن BERT مصمم لقبول زوج من الجمل بتنسيق <question-answer>. يؤدي هذا إلى تمرير رموز فاصلة مثل [CLS] في البداية للإشارة إلى بداية التسلسل. ثم يتم استخدام رمز [SEP] لفصل السؤال عن الإجابة.
لذا، يصبح الإدخال البسيط الآن، [CLS]<question>[SEP]<answer>[SEP] كما هو موضح في الشكل أدناه.


يتم تمرير الجملتين A وB من خلال نموذج تضمين WordPiece بعد تضمين رمزي [CLS] و[SEP]. نظرًا لوجود جملتين، يحتاج النموذج إلى تضمينات إضافية للتمييز بينهما. يأتي هذا في شكل تضمينات مقطعية وموضعية.
يشير تضمين المقطع الموضح باللون الأخضر أدناه إلى ما إذا كانت رموز الإدخال تنتمي إلى الجملة A أو B. ثم يأتي تضمين الموضع الذي يشير إلى موضع كل رمز في التسلسل.


الشكل مأخوذ من ورقة BERT التي توضح التمثيل المدخل للنموذج.
يتم جمع كل التضمينات الثلاثة معًا وإدخالها إلى نموذج BERT الذي يعمل في اتجاهين كما هو موضح في الشكل السابق. فهو لا يلتقط السياق الأمامي فحسب، بل يلتقط أيضًا السياق الخلفي قبل أن يعطينا المخرجات لكل رمز.
تدريب مسبق على BERT
هناك طريقتان يتم من خلالهما تدريب نموذج BERT مسبقًا باستخدام مهمتين غير خاضعتين للإشراف:
نموذج اللغة المقنعة (MLM). هنا نقوم بإخفاء بعض النسب المئوية للرموز في التسلسل ونترك النموذج يتنبأ بالرموز المقنعة. يُعرف هذا أيضًا باسم مهمة الإكمال . في الممارسة العملية، يتم إخفاء 15% من الرموز لهذه المهمة.
التنبؤ بالجملة التالية (NSP). هنا، نجعل النموذج يتنبأ بالجملة التالية في التسلسل. كلما كانت الجملة هي الجملة التالية الفعلية، نستخدم العلامة
IsNextوعندما لا تكون كذلك، نستخدم العلامةNotNext.



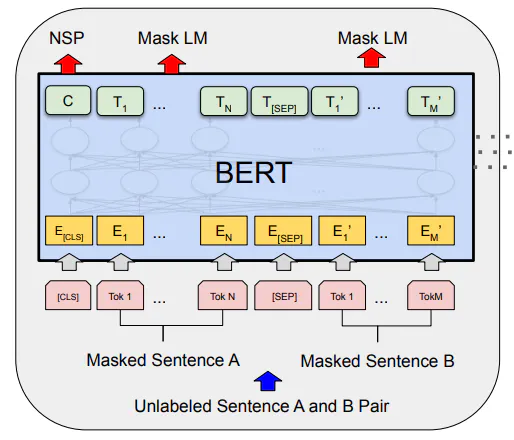
كما يمكن أن نرى من الشكل أعلاه من الورقة، يتم استخدام رمز الإخراج الأول لمهمة NSP ويتم استخدام الرموز الموجودة في المنتصف والتي يتم إخفاءها لمهمة MLM.
نظرًا لأننا نقوم بالتدريب على مستوى الرمز، فإن كل رمز إدخال ينتج رمز إخراج. وكما هو الحال مع أي مهمة تصنيف، يتم استخدام فقدان الإنتروبيا المتقاطعة لتدريب النموذج.
ما هو الخطأ في BERT؟
في حين أن BERT قد يكون جيدًا في التقاط السياق الأمامي والخلفي، فقد لا يكون الأنسب للعثور على أوجه التشابه بين آلاف الجمل. دعنا نفكر في مهمة العثور على الزوج الأكثر تشابهًا من الجمل في مجموعة كبيرة من 10000 جملة. بعبارة أخرى، نود "استرجاع" الجملة الأكثر تشابهًا مع الجملة (أ) من بين 10000 جملة.
للقيام بذلك، نحتاج إلى إقران كل تركيبة ممكنة من جملتين من 10000. سيكون ذلك n * (n — 1) / 2 = 4,999,500 زوج! يا إلهي، هذا تعقيد تربيعي. سيستغرق نموذج BERT 65 ساعة لإنشاء التضمينات وحل هذه المقارنة.
ببساطة، لا يعد نموذج BERT هو الأفضل للبحث عن التشابه. ولكن الاسترجاع والبحث عن التشابه هما جوهر أي خط أنابيب RAG. والحل يكمن في SBERT.
SBERT — مستوى الجملة BERT
إن القيود التي يفرضها BERT تنبع إلى حد كبير من بنيته المتداخلة حيث نقوم بإدخال جملتين معًا بالتتابع مع وجود رمز [SEP] بينهما. وإذا تم التعامل مع كل جملة على حدة، فيمكننا حساب التضمينات مسبقًا واستخدامها مباشرة للحساب بشكل مماثل عند الحاجة. هذا هو بالضبط اقتراح الجملة BERT أو SBERT باختصار.
يقدم SBERT الشبكة السيامية إلى بنية BERT. وتعني الكلمة توأمًا أو وثيق الصلة.


معنى كلمة سيامي مأخوذ من dictionary.com
لذا، في SBERT لدينا نفس شبكة BERT المتصلة كـ "توأم". يدمج النموذج الجملة الأولى متبوعة بالثانية بدلاً من التعامل معهما بشكل تسلسلي.
ملاحظة: من الشائع جدًا رسم شبكتين جنبًا إلى جنب لتصور الشبكات السيامية. ولكن في الممارسة العملية، تكون الشبكة واحدة وتستقبل مدخلين مختلفين.
هندسة SBERT
فيما يلي رسم تخطيطي يقدم نظرة عامة على بنية SBERT.


هندسة الشبكة السيامية بهدف التصنيف للخسارة. يتم ربط المخرجات U وV من الفرعين مع اختلافهما
.
أولاً، يمكننا ملاحظة أن SBERT يقدم طبقة تجميع بعد BERT بفترة وجيزة. وهذا يقلل من أبعاد مخرجات BERT لتقليل الحساب. ينتج BERT عمومًا مخرجات بأبعاد 512 × 768. تقلل طبقة التجميع هذا إلى 1 × 768. التجميع الافتراضي هو المتوسط على الرغم من أن التجميع المتوسط والأقصى يعملان.
بعد ذلك، دعونا نلقي نظرة على نهج التدريب حيث يختلف SBERT عن BERT.
التدريب المسبق
يقترح SBERT ثلاث طرق لتدريب النموذج. دعونا نلقي نظرة على كل منها.
الاستدلال على اللغة الطبيعية (NLI) - هدف التصنيف
تم ضبط SBERT على أساس مجموعات بيانات Stanford Natural Language Inference (SNLI) وMulti-Genre NLI لهذا الغرض. تتكون SNLI من 570 ألف زوج جملة بينما تحتوي MNLI على 430 ألف زوج جملة. تحتوي الأزواج على فرضية (P) وفرضية (H) تؤدي إلى أحد التصنيفات الثلاثة التالية:
- التفضيل - الفرضية تشير إلى الفرضية
- محايد - يمكن أن تكون المقدمة والفرضية صحيحتين ولكن ليس بالضرورة أن تكونا مرتبطتين
- التناقض - المقدمة والفرضية تتناقضان مع بعضهما البعض
بالنظر إلى الجملتين P وH، ينتج نموذج SBERT مخرجين U وV. ثم يتم ربطهما معًا على النحو التالي (U وV و|U — V|).
يتم استخدام الناتج المتسلسل لتدريب SBERT باستخدام هدف التصنيف. يتم تغذية هذا الناتج المتسلسل إلى شبكة عصبية تغذية أمامية بثلاثة مخرجات فئة (Eltailment وNeutral وContradiction). يتم استخدام الإدخال المتبادل Softmax للتدريب على غرار الطريقة التي نتدرب بها على أي مهمة تصنيف أخرى.
تشابه الجمل - هدف الانحدار
بدلاً من ربط U وV معًا، نحسب مباشرةً تشابه جيب التمام بين المتجهين. وعلى غرار أي مشكلة انحدار قياسية، نستخدم خسارة الخطأ التربيعي المتوسط للتدريب على الانحدار. أثناء الاستدلال، يمكن استخدام نفس الشبكة مباشرةً لمقارنة أي جملتين. يعطي SBERT درجة حول مدى تشابه الجملتين.
تشابه الثلاثيات — هدف الثلاثيات
تم تقديم هدف التشابه الثلاثي لأول مرة في التعرف على الوجوه وتم تكييفه ببطء إلى مجالات أخرى من الذكاء الاصطناعي مثل النصوص والروبوتات.
هنا يتم تغذية 3 مدخلات إلى SBERT بدلاً من 2 — مرساة وإيجابية وسلبية. يجب اختيار مجموعة البيانات المستخدمة لهذا وفقًا لذلك. لإنشائها، يمكننا اختيار أي بيانات نصية واختيار جملتين متتاليتين كنتيجة إيجابية. ثم اختيار جملة عشوائية من فقرة مختلفة كعينة سلبية.
يتم بعد ذلك حساب الخسارة الثلاثية عن طريق مقارنة مدى قرب الموجب من المرساة مقابل مدى قربه من السالب.


بعد هذه المقدمة عن BERT وSBERT، دعونا نلقي نظرة سريعة على كيفية الحصول على تضمينات لأي جملة (جمل) معينة باستخدام هذه النماذج.
التدريب العملي على SBERT
منذ نشرها، اكتسبت المكتبة الرسمية لـ SBERT، وهي sentence-transformer شعبية ونضجت. وهي جيدة بما يكفي لاستخدامها في حالات الاستخدام الإنتاجية لـ RAG. لذا فلنستخدمها فورًا.
للبدء، دعنا نبدأ بالتثبيت في بيئة Python جديدة تمامًا.
!pip install sentence-transformers
هناك عدة أشكال مختلفة لنموذج SBERT يمكننا تحميلها من المكتبة. دعنا نحمل النموذج للتوضيح.
from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens')
يمكننا ببساطة إنشاء قائمة من الجمل واستدعاء وظيفة encode الخاصة بالنموذج لإنشاء التضمينات. الأمر بهذه البساطة!
sentences = [ "The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium.", ] embeddings = model.encode(sentences) print(embeddings.shape)
ويمكننا العثور على درجات التشابه بين التضمينات باستخدام السطر أدناه:
similarities = model.similarity(embeddings, embeddings) print(similarities)
لاحظ أن التشابه بين نفس الجملة هو 1 كما هو متوقع:
tensor([[1.0000, 0.6660, 0.1046], [0.6660, 1.0000, 0.1411], [0.1046, 0.1411, 1.0000]])خاتمة
يعد التضمين خطوة أساسية وحاسمة لجعل خط أنابيب RAG يعمل بأفضل أداء. آمل أن يكون ذلك مفيدًا وأن يفتح أعينك على ما يحدث تحت الغطاء كلما استخدمنا محولات الجملة خارج الصندوق.
ترقبوا المقالات القادمة حول RAG وكيفية عملها الداخلي بالإضافة إلى البرامج التعليمية العملية أيضًا.








