






















यो लेख ट्रान्सफर्मरबाट सुरु हुन्छ र यसको कमजोरीहरूलाई एम्बेडिङ मोडेलको रूपमा हेर्छ। त्यसपछि यसले BERT को एक सिंहावलोकन दिन्छ र वाक्य BERT (SBERT) मा गहिरो डाइभ्स दिन्छ जुन LLMs र RAG पाइपलाइनहरूको लागि वाक्य इम्बेडिङहरूमा अत्याधुनिक छ।
दृश्य व्याख्या
यदि तपाईं म जस्तै दृश्य व्यक्ति हुनुहुन्छ र दृश्य व्याख्या हेर्न चाहनुहुन्छ भने, कृपया यो भिडियो हेर्नुहोस्:
ट्रान्सफर्मर
ट्रान्सफर्मरलाई कुनै परिचय चाहिँदैन। यद्यपि तिनीहरू प्रारम्भमा भाषा अनुवाद कार्यहरूको लागि डिजाइन गरिएको थियो, तिनीहरू आज लगभग सबै LLMs पछाडि ड्राइभिङ घोडाहरू हुन्।
उच्च स्तरमा, तिनीहरू दुई ब्लकहरू - एन्कोडर र डिकोडरबाट बनेका छन्। एन्कोडर ब्लकले इनपुट लिन्छ र म्याट्रिक्स प्रतिनिधित्व आउटपुट गर्दछ। डिकोडर ब्लकले अन्तिम एन्कोडरको आउटपुटमा लिन्छ र आउटपुट उत्पादन गर्दछ। एन्कोडर र डिकोडर ब्लकहरू धेरै तहहरूबाट बन्न सकिन्छ, यद्यपि मूल ट्रान्सफर्मरमा प्रत्येक ब्लकमा 6 तहहरू छन्।


सबै तहहरू बहु-हेडेड आत्म-ध्यानबाट बनेका छन्। यद्यपि, एन्कोडर र डिकोडर बीचको मात्र फरक यो हो कि एन्कोडरको आउटपुट डिकोडरको प्रत्येक तहमा खुवाइन्छ। ध्यान तहहरूको सन्दर्भमा, डिकोडर ध्यान तहहरू मास्क गरिएका छन्। त्यसोभए, कुनै पनि स्थितिमा आउटपुट अघिल्लो स्थानहरूमा आउटपुटबाट प्रभावित हुन्छ।
एन्कोडर र डिकोडर ब्लक थप स्तर मानक र फिड-फर्वार्ड न्यूरल नेटवर्क तहहरू मिलेर बनेको छ।
पहिलेका मोडेलहरू जस्तै RNNs वा LSTMs जसले टोकनहरूलाई स्वतन्त्र रूपमा प्रशोधन गर्छ, ट्रान्सफर्मरहरूको शक्ति सम्पूर्ण अनुक्रमको सन्दर्भमा प्रत्येक टोकनको सन्दर्भ क्याप्चर गर्ने क्षमतामा हुन्छ। यसरी, यसले भाषा प्रशोधनका लागि डिजाइन गरिएको कुनै पनि अघिल्लो वास्तुकलाको तुलनामा धेरै सन्दर्भहरू क्याप्चर गर्दछ।
ट्रान्सफर्मरमा के गल्ती छ?
ट्रान्सफर्मरहरू सबैभन्दा सफल आर्किटेक्चर हुन् जसले आज एआई क्रान्तिलाई ड्राइभ गरिरहेका छन्। त्यसोभए, यदि मैले यसको साथ सीमितताहरू देखाउँछु भने मलाई ढोका देखाउन सकिन्छ। यद्यपि, वास्तवमा, कम्प्युटेसनल ओभरहेड कम गर्न, यसको ध्यान तहहरू केवल विगत टोकनहरूमा उपस्थित हुन डिजाइन गरिएको हो। यो धेरै कार्यहरूको लागि ठीक छ। तर प्रश्न-उत्तर जस्ता कार्यको लागि पर्याप्त नहुन सक्छ। तलको उदाहरण लिऔं।
जोन मिलोसँग पार्टीको लागि आएका थिए। मिलोले पार्टीमा धेरै रमाइलो गरे। उहाँ फर संग एक सुन्दर, सेतो बिरालो हो।
मानौं हामी प्रश्न सोध्छौं, "के मिलोले जोनसँग पार्टीमा पिउनुभयो?" माथिको उदाहरणमा पहिलो 2 वाक्यहरूमा आधारित, यो धेरै सम्भावना छ कि LLM ले जवाफ दिनेछ, "मिलोले धेरै रमाइलो गरेको कारण मिलोले पार्टीमा पिउनुभयो भन्ने संकेत गर्दछ।"
यद्यपि, अगाडिको सन्दर्भको साथ प्रशिक्षित मोडेलले तेस्रो वाक्यको बारेमा सचेत हुनेछ, जुन हो, "उहाँ एक सुन्दर, मिलनसार बिरालो हो"। र त्यसोभए, जवाफ दिनेछ, "मिलो एउटा बिरालो हो, र त्यसैले उसले पार्टीमा पिउने सम्भावना छैन।"
यद्यपि यो एक काल्पनिक उदाहरण हो, तपाईले विचार पाउनुहुन्छ। प्रश्न-उत्तर कार्यमा, अगाडि र पछाडि दुवै सन्दर्भ सिक्नु महत्त्वपूर्ण हुन्छ। यो जहाँ BERT मोडेल आउँछ।
BERT
BERT ट्रान्सफर्मरहरूबाट द्विदिशात्मक एन्कोडर प्रतिनिधित्वको लागि खडा छ। नामले सुझाव दिन्छ, यो ट्रान्सफर्मरमा आधारित छ, र यसले अगाडि र पछाडि दुवै सन्दर्भ समावेश गर्दछ। यद्यपि यो प्रारम्भिक रूपमा प्रश्न उत्तर र संक्षेपीकरण जस्ता कार्यहरूको लागि प्रकाशित गरिएको थियो, यसको द्विदिशात्मक प्रकृतिको कारण यसले शक्तिशाली इम्बेडिङहरू उत्पादन गर्ने क्षमता राख्छ।
BERT मोडेल
BERT अनुक्रममा सँगै स्ट्याक गरिएका ट्रान्सफर्मर एन्कोडरहरू बाहेक अरू केही होइन। फरक यति मात्र हो कि BERT ले द्विदिशात्मक आत्म-ध्यान प्रयोग गर्दछ, जबकि भेनिला ट्रान्सफर्मरले सीमित आत्म-ध्यान प्रयोग गर्दछ जहाँ प्रत्येक टोकनले यसको बायाँ तर्फको सन्दर्भमा मात्र उपस्थित हुन सक्छ।
नोट: अनुक्रम बनाम वाक्य। BERT मोडेलसँग व्यवहार गर्दा भ्रमबाट बच्नको लागि शब्दावलीमा मात्र एउटा नोट। वाक्य अवधि द्वारा विभाजित शब्दहरूको एक श्रृंखला हो। एक अनुक्रम एक साथ स्ट्याक गरिएका वाक्यहरूको संख्या हुन सक्छ।
BERT बुझ्नको लागि, प्रश्न उत्तरको उदाहरण लिनुहोस्। प्रश्न-उत्तरमा कम्तिमा दुई वाक्यहरू समावेश भएकाले, BERT लाई <question-answer> ढाँचामा वाक्यहरूको जोडी स्वीकार गर्न डिजाइन गरिएको हो। यसले सेपरेटर टोकनहरू जस्तै [CLS] लाई अनुक्रमको सुरुवातलाई संकेत गर्न सुरुमा पास गर्छ। [SEP] टोकन त्यसपछि प्रश्न र उत्तर अलग गर्न प्रयोग गरिन्छ।
त्यसकारण, एउटा साधारण इनपुट अब बन्छ, [CLS]<question>[SEP]<answer>[SEP] तलको चित्रमा देखाइएको छ।


दुई वाक्य A र B [CLS] र [SEP] टोकनहरू समावेश गरेपछि WordPiece इम्बेडिङ मोडेल मार्फत पारित गरिन्छ। जसरी हामीसँग दुईवटा वाक्यहरू छन्, मोडेललाई तिनीहरूलाई छुट्याउन थप एम्बेडिङहरू चाहिन्छ। यो खण्ड र स्थिति इम्बेडिङ को रूप मा आउँछ।
तलको हरियोमा देखाइएको खण्ड इम्बेडिङले इनपुट टोकनहरू वाक्य A वा B सँग सम्बन्धित छन् भने संकेत गर्दछ। त्यसपछि स्थिति इम्बेडिङ आउँछ जसले अनुक्रममा प्रत्येक टोकनको स्थितिलाई संकेत गर्छ।


मोडेलको इनपुट प्रतिनिधित्व देखाउँदै BERT पेपरबाट लिइएको चित्र।
सबै तीन एम्बेडिङहरू एकसाथ जोडिएका छन् र BERT मोडेलमा खुवाइन्छ जुन अघिल्लो चित्रमा देखाइएको रूपमा द्विदिशात्मक छ। यसले हामीलाई प्रत्येक टोकनको लागि आउटपुटहरू दिनु अघि अगाडिको सन्दर्भ मात्र होइन तर पछाडिको सन्दर्भलाई पनि क्याप्चर गर्दछ।
पूर्व-प्रशिक्षण BERT
त्यहाँ दुई तरिकाहरू छन् जसमा BERT मोडेललाई दुई असुरक्षित कार्यहरू प्रयोग गरेर पूर्व-प्रशिक्षित गरिएको छ:
मास्क गरिएको भाषा मोडेल (MLM)। यहाँ हामी अनुक्रममा टोकनहरूको केही प्रतिशत मास्क गर्छौं र मोडेललाई मास्क गरिएका टोकनहरूको भविष्यवाणी गर्न दिन्छौं। यसलाई क्लोज टास्क पनि भनिन्छ। अभ्यासमा, टोकनहरूको 15% यस कार्यको लागि मास्क गरिएको छ।
अर्को वाक्य भविष्यवाणी (NSP)। यहाँ, हामी मोडेललाई अनुक्रममा अर्को वाक्य भविष्यवाणी गर्छौं। जब वाक्य वास्तविक अर्को हो, हामी लेबल
IsNextप्रयोग गर्छौं र जब यो होइन, हामी लेबलNotNextप्रयोग गर्छौं।



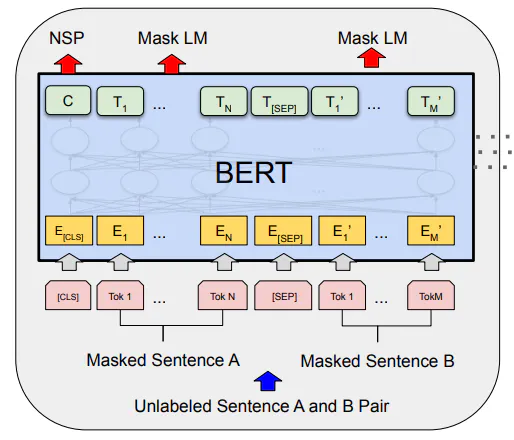
कागजबाट माथिको चित्रबाट देख्न सकिन्छ, पहिलो आउटपुट टोकन NSP कार्यको लागि प्रयोग गरिन्छ र बीचमा मास्क गरिएका टोकनहरू MLM कार्यको लागि प्रयोग गरिन्छ।
हामीले टोकन स्तरमा तालिम दिइरहेका बेला, प्रत्येक इनपुट टोकनले आउटपुट टोकन उत्पादन गर्छ। कुनै पनि वर्गीकरण कार्यको रूपमा, क्रस-एन्ट्रोपी हानि मोडेललाई तालिम दिन प्रयोग गरिन्छ।
BERT सँग के गलत छ?
जबकि BERT अगाडि र पछाडि दुवै सन्दर्भ क्याप्चर गर्न राम्रो हुन सक्छ, यो हजारौं वाक्यहरू बीच समानताहरू फेला पार्न सबैभन्दा उपयुक्त नहुन सक्छ। 10,000 वाक्यहरूको ठूलो संग्रहमा वाक्यहरूको सबैभन्दा समान जोडी खोज्ने कार्यलाई विचार गरौं। अन्य शब्दहरूमा, हामी 10,000 वाक्यहरू मध्ये वाक्य A सँग मिल्दोजुल्दो वाक्य "पुन: प्राप्त" गर्न चाहन्छौं।
यो गर्नको लागि, हामीले 10,000 बाट 2 वाक्यहरूको प्रत्येक सम्भावित संयोजन जोड्न आवश्यक छ। त्यो n * (n — 1) / 2 = 4,999,500 जोडी हुनेछ! धिक्कार छ, त्यो द्विघातीय जटिलता हो। इम्बेडिङहरू सिर्जना गर्न र यो तुलनाको लागि समाधान गर्न BERT मोडेललाई ६५ घण्टा लाग्नेछ।
सरल रूपमा भने, BERT मोडेल समानता खोजको लागि उत्तम होइन। तर पुन: प्राप्ति र समानता खोज कुनै पनि RAG पाइपलाइनको मुटुमा हुन्छ। समाधान SBERT मा छ।
SBERT - वाक्य स्तर BERT
BERT को सीमितता धेरै हदसम्म यसको क्रस-इन्कोडर आर्किटेक्चरबाट उत्पन्न हुन्छ जहाँ हामी बीचमा [SEP] टोकनको साथ अनुक्रममा दुई वाक्यहरू खुवाउँछौं। यदि प्रत्येक वाक्यलाई मात्र छुट्टाछुट्टै व्यवहार गर्ने हो भने, हामीले इम्बेडिङहरू पूर्व-कम्प्युट गर्न सक्छौं र आवश्यक परेको बेलामा समान रूपमा गणना गर्न प्रयोग गर्न सक्छौं। यो ठ्याक्कै वाक्य BERT वा SBERT को प्रस्ताव छ।
SBERT ले BERT वास्तुकलामा Siamese नेटवर्क परिचय गराउँछ। शब्दको अर्थ जुम्ल्याहा वा नजिकको सम्बन्ध हो।


Dictionary.com बाट लिइएको Siamese को अर्थ
त्यसोभए, SBERT मा हामीसँग उही BERT नेटवर्क "जुम्ल्याहा" को रूपमा जोडिएको छ। मोडेलले पहिलो वाक्यलाई क्रमिक रूपमा व्यवहार गर्नुको सट्टा दोस्रो पछि इम्बेड गर्दछ।
नोट: सियामी नेटवर्कहरू कल्पना गर्नको लागि 2 सञ्जालहरू छेउ-छेउमा कोर्ने यो एकदम सामान्य अभ्यास हो। तर व्यवहारमा, यसको एकल नेटवर्कले दुई फरक इनपुटहरू लिन्छ।
SBERT वास्तुकला
तल एउटा रेखाचित्र हो जसले SBERT वास्तुकलाको एक सिंहावलोकन दिन्छ।


नोक्सानको लागि वर्गीकरण उद्देश्यको साथ सियामी नेटवर्क वास्तुकला। दुई शाखाहरूबाट आउटपुट U र V तिनीहरूको भिन्नता संग जोडिएको छ
।
पहिलो, हामीले याद गर्न सक्छौं कि SBERT ले BERT पछि तुरुन्तै पूलिङ लेयर प्रस्तुत गर्दछ। यसले गणना घटाउन BERT को आउटपुटको आयाम घटाउँछ। BERT ले सामान्यतया 512 X 768 आयामहरूमा आउटपुटहरू उत्पादन गर्दछ। पूलिङ तहले यसलाई 1 X 768 मा घटाउँछ। पूर्वनिर्धारित पूलिङ भनेको औसत र अधिकतम पूलिङले काम गरे तापनि औसत हो।
अर्को, प्रशिक्षण दृष्टिकोण हेरौं जहाँ SBERT BERT बाट अलग हुन्छ।
पूर्व प्रशिक्षण
SBERT ले मोडेललाई तालिम दिने तीन तरिकाहरू प्रस्ताव गर्दछ। तिनीहरूमध्ये प्रत्येकलाई हेरौं।
Natural Language Inference (NLI) — वर्गीकरण उद्देश्य
SBERT यसका लागि स्ट्यानफोर्ड नेचुरल ल्याङ्ग्वेज इन्फरेन्सन (SNLI) र बहु-विधा NLI डाटासेटहरूमा राम्रोसँग ट्युन गरिएको छ। SNLI मा 570K वाक्य जोडी र MNLI मा 430K छ। जोडीहरूमा एक आधार (P) र एक परिकल्पना (H) छ जसले 3 लेबलहरू मध्ये एकमा नेतृत्व गर्दछ:
- Eltailment - आधारले परिकल्पना सुझाव दिन्छ
- तटस्थ - आधार र परिकल्पना सत्य हुन सक्छ तर आवश्यक रूपमा सम्बन्धित छैन
- विरोधाभास - आधार र परिकल्पना एक अर्काको विरोधाभास
P र H दुई वाक्यहरूलाई दिएर, SBERT मोडेलले U र V दुई आउटपुटहरू उत्पादन गर्छ। त्यसपछि तिनीहरूलाई (U, V र |U — V|) को रूपमा जोडिन्छ।
एकीकृत आउटपुट SBERT लाई वर्गीकरण उद्देश्यसँग तालिम दिन प्रयोग गरिन्छ। यो कन्कटेनेटेड आउटपुट फिड फर्वार्ड न्यूरल नेटवर्कमा 3 वर्ग आउटपुटहरू (Eltailment, तटस्थ, र विरोधाभास) को साथ खुवाइन्छ। Softmax क्रस-प्रविष्टि प्रशिक्षणको लागि प्रयोग गरिन्छ जसरी हामी कुनै अन्य वर्गीकरण कार्यको लागि तालिम दिन्छौं।
वाक्य समानता - प्रतिगमन उद्देश्य
U र V लाई जोड्नुको सट्टा, हामी दुई भेक्टरहरू बीचको कोसाइन समानता सीधै गणना गर्छौं। कुनै पनि मानक रिग्रेसन समस्या जस्तै, हामी प्रतिगमनको लागि तालिम दिनको लागि औसत-वर्ग त्रुटि हानि प्रयोग गर्छौं। अनुमानको समयमा, एउटै नेटवर्क सीधा कुनै पनि दुई वाक्य तुलना गर्न प्रयोग गर्न सकिन्छ। SBERT ले दुई वाक्यहरू कत्तिको समान छन् भनेर अंक दिन्छ।
Triplet समानता - Triplet उद्देश्य
ट्रिपलेट समानता उद्देश्य पहिलो पटक अनुहार पहिचानमा प्रस्तुत गरिएको थियो र बिस्तारै पाठ र रोबोटिक्स जस्ता AI को अन्य क्षेत्रहरूमा अनुकूलित गरिएको छ।
यहाँ 2 को सट्टा SBERT लाई 3 इनपुटहरू खुवाइन्छ - एउटा एङ्कर, एक सकारात्मक, र एक नकारात्मक। यसका लागि प्रयोग गरिएको डाटासेट तदनुसार छनोट गर्नुपर्छ। यसलाई सिर्जना गर्न, हामी कुनै पनि पाठ डेटा छनोट गर्न सक्छौं, र सकारात्मक entailment को रूपमा लगातार दुई वाक्यहरू छनौट गर्न सक्छौं। त्यसपछि फरक अनुच्छेदबाट नकारात्मक नमूनाबाट अनियमित वाक्य छान्नुहोस्।
त्यसपछि एक ट्रिपलेट हानि गणना गरीएको छ कि सकारात्मक एंकर को कती नजिक छ र यो नकारात्मक को कति नजिक छ तुलना गरेर।


BERT र SBERT को परिचयको साथ, यी मोडेलहरू प्रयोग गरेर हामीले कुनै पनि वाक्य(हरू) को इम्बेडिङहरू कसरी प्राप्त गर्न सक्छौं भनेर बुझ्नको लागि द्रुत ह्यान्ड्स-अन गरौं।
ह्यान्ड्स अन SBERT
यसको प्रकाशन पछि पनि, SBERT को लागि आधिकारिक पुस्तकालय जुन sentence-transformer हो लोकप्रियता र परिपक्व भएको छ। यो RAG को लागि उत्पादन प्रयोग मामिलाहरूमा प्रयोग गर्न पर्याप्त छ। त्यसैले यसलाई बक्स बाहिर प्रयोग गरौं।
सुरु गर्नको लागि, नयाँ नयाँ पाइथन वातावरणमा स्थापनाको साथ सुरु गरौं।
!pip install sentence-transformers
हामीले पुस्तकालयबाट लोड गर्न सक्ने SBERT मोडेलका धेरै भिन्नताहरू छन्। दृष्टान्तको लागि मोडेल लोड गरौं।
from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens')
हामी केवल वाक्यहरूको सूची सिर्जना गर्न सक्छौं र एम्बेडिङहरू सिर्जना गर्न मोडेलको encode प्रकार्य आह्वान गर्न सक्छौं। यो एकदम सरल छ!
sentences = [ "The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium.", ] embeddings = model.encode(sentences) print(embeddings.shape)
र हामीले तलको १ रेखा प्रयोग गरी इम्बेडिङहरू बीच समानता स्कोरहरू फेला पार्न सक्छौं:
similarities = model.similarity(embeddings, embeddings) print(similarities)
ध्यान दिनुहोस् कि समान वाक्य बीच समानता 1 अपेक्षित रूपमा छ:
tensor([[1.0000, 0.6660, 0.1046], [0.6660, 1.0000, 0.1411], [0.1046, 0.1411, 1.0000]])निष्कर्ष
इम्बेडिङ RAG पाइपलाइनलाई उत्कृष्ट रूपमा काम गर्नको लागि एक महत्त्वपूर्ण र आधारभूत चरण हो। आशा छ कि उपयोगी थियो र हुड मुनि के भइरहेको छ भनेर तपाइँको आँखा खोल्यो जब हामी बाकस बाहिर वाक्य ट्रान्सफर्मर प्रयोग गर्छौं।
RAG मा आगामी लेखहरू र यसका भित्री कार्यहरू र ह्यान्ड्स-अन ट्यूटोरियलहरूका लागि पनि सम्पर्कमा रहनुहोस्।








