






















この記事では、まずトランスフォーマーについて説明し、埋め込みモデルとしての欠点を見ていきます。次に、BERT の概要を示し、LLM および RAG パイプラインのセンテンス埋め込みの最先端の技術である Sentence BERT (SBERT) について詳しく説明します。
視覚的な説明
私のように視覚重視の人や、視覚的な説明を見たい人は、このビデオをご覧ください。
トランスフォーマー
Transformer については説明の必要はありません。Transformer はもともと言語翻訳タスク用に設計されましたが、現在ではほぼすべての LLM の原動力となっています。
大まかに言うと、これらはエンコーダーとデコーダーの 2 つのブロックで構成されています。エンコーダー ブロックは入力を受け取り、マトリックス表現を出力します。デコーダー ブロックは最後のエンコーダーの出力を受け取り、出力を生成します。エンコーダー ブロックとデコーダー ブロックは複数のレイヤーで構成できますが、元のトランスフォーマーは各ブロックに 6 つのレイヤーがあります。


すべてのレイヤーは、マルチヘッドのセルフアテンションで構成されています。ただし、エンコーダーとデコーダーの唯一の違いは、エンコーダーの出力がデコーダーの各レイヤーに供給されることです。アテンションレイヤーに関しては、デコーダーのアテンションレイヤーはマスクされています。そのため、どの位置の出力も、前の位置の出力の影響を受けます。
エンコーダー ブロックとデコーダー ブロックは、さらにレイヤー ノルム レイヤーとフィードフォワード ニューラル ネットワーク レイヤーで構成されます。
トークンを個別に処理する RNN や LSTM などの以前のモデルとは異なり、トランスフォーマーの強みは、シーケンス全体に対する各トークンのコンテキストをキャプチャする機能にあります。そのため、言語処理用に設計された以前のアーキテクチャと比較して、多くのコンテキストをキャプチャします。
トランスフォーマーの何が問題なのか?
トランスフォーマーは、今日の AI 革命を推進する最も成功したアーキテクチャです。そのため、その限界を指摘すると、却下される可能性があります。ただし、実際のところ、計算オーバーヘッドを削減するために、そのアテンション レイヤーは過去のトークンにのみ注意を払うように設計されています。これはほとんどのタスクには適しています。ただし、質問応答などのタスクには十分ではない可能性があります。以下の例を見てみましょう。
ジョンはミロと一緒にパーティーに来ました。ミロはパーティーをとても楽しんでいました。彼は毛皮のある美しい白い猫です。
「ミロはジョンと一緒にパーティーでお酒を飲みましたか?」という質問をしたとします。上記の例の最初の 2 つの文だけに基づくと、LLM は「ミロがとても楽しんだということは、ミロがパーティーでお酒を飲んだことを示しています」と答える可能性が非常に高くなります。
しかし、前向きコンテキストでトレーニングされたモデルは、3 番目の文「彼は美しく、人懐っこい猫です」を認識します。そのため、「ミロは猫なので、パーティーで飲酒した可能性は低いです」と返答します。
これは仮説的な例ですが、要点は理解していただけると思います。質問応答タスクでは、前方コンテキストと後方コンテキストの両方を学習することが重要になります。ここで BERT モデルが役立ちます。
バート
BERT は、Bidirectional Encoder Representations from Transformers の略です。名前が示すように、これは Transformers に基づいており、前方コンテキストと後方コンテキストの両方を組み込んでいます。当初は質問応答や要約などのタスク用に公開されましたが、双方向性があるため、強力な埋め込みを生成する可能性があります。
BERT モデル
BERT は、トランスフォーマー エンコーダーを順番に積み重ねたものにすぎません。唯一の違いは、BERT が双方向の自己注意を使用するのに対し、通常のトランスフォーマーは、すべてのトークンが左側のコンテキストにのみ注意を向けることができる制約付き自己注意を使用することです。
注: シーケンスと文。BERT モデルを扱う際に混乱を避けるための用語に関する注意です。文はピリオドで区切られた一連の単語です。シーケンスは任意の数の文を積み重ねたものになります。
BERT を理解するために、質問応答の例を見てみましょう。質問応答には最低 2 つの文が含まれるため、BERT は <質問-回答> という形式の文のペアを受け入れるように設計されています。これにより、シーケンスの開始を示すために [CLS] などの区切りトークンが最初に渡されます。次に、[SEP] トークンを使用して質問と回答を区切ります。
したがって、簡単な入力は、下の図に示すように、[CLS]<question>[SEP]<answer>[SEP] になります。


2 つの文 A と B は、[CLS] トークンと [SEP] トークンを含めた後、WordPiece 埋め込みモデルに渡されます。文が 2 つあるため、モデルではそれらを区別するために追加の埋め込みが必要です。これは、セグメント埋め込みと位置埋め込みの形式で提供されます。
以下に緑色で表示されるセグメント埋め込みは、入力トークンが文 A または B のどちらに属しているかを示します。次に、シーケンス内の各トークンの位置を示す位置埋め込みが続きます。


BERT 論文から引用した、モデルの入力表現を示す図。
3 つの埋め込みはすべて合計され、前の図に示すように双方向の BERT モデルに送られます。各トークンの出力を提供する前に、前方コンテキストだけでなく後方コンテキストもキャプチャします。
BERTの事前トレーニング
BERT モデルを 2 つの教師なしタスクを使用して事前トレーニングする方法は 2 つあります。
マスク言語モデル (MLM)。ここでは、シーケンス内のトークンの一部をマスクし、モデルにマスクされたトークンを予測させます。これは、クローズタスクとも呼ばれます。実際には、このタスクではトークンの 15% がマスクされます。
次の文の予測 (NSP)。ここでは、モデルにシーケンス内の次の文を予測させます。文が実際に次の文である場合は常に
IsNextラベルを使用し、そうでない場合はNotNextラベルを使用します。



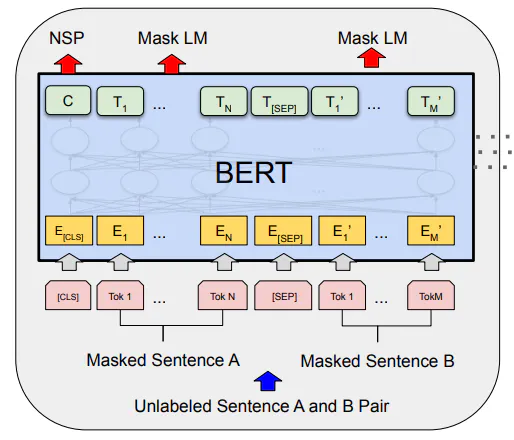
論文の上の図からわかるように、最初の出力トークンは NSP タスクに使用され、マスクされた中央のトークンは MLM タスクに使用されます。
トークン レベルでトレーニングを行っているため、各入力トークンは出力トークンを生成します。他の分類タスクと同様に、モデルのトレーニングにはクロスエントロピー損失が使用されます。
BERT の何が問題なのですか?
BERT は前方と後方の両方のコンテキストをキャプチャするのに優れていますが、何千もの文の類似点を見つけるのに最適ではない可能性があります。10,000 の文の大規模なコレクションから最も類似した文のペアを見つけるタスクを考えてみましょう。言い換えると、10,000 の文の中から文 A に最も類似した文を「取得」したいということです。
これを実行するには、10,000 個の文から 2 つの文のあらゆる可能な組み合わせをペアにする必要があります。これは n * (n — 1) / 2 = 4,999,500 ペアになります。これは 2 次式の複雑さです。BERT モデルが埋め込みを作成してこの比較を解決するには 65 時間かかります。
簡単に言えば、BERT モデルは類似性検索に最適ではありません。しかし、検索と類似性検索はあらゆる RAG パイプラインの中核です。解決策は SBERT にあります。
SBERT — 文レベル BERT
BERT の制限は、主に、2 つの文を [SEP] トークンを挟んで順番に入力するクロス エンコーダ アーキテクチャに起因します。各文を個別に処理するだけであれば、埋め込みを事前に計算しておき、必要に応じて直接使用して同様に計算することができます。これがまさに、Sentence BERT (略して SBERT) の命題です。
SBERT は、BERT アーキテクチャにSiamese ネットワークを導入します。この単語は双子または密接に関連していることを意味します。


シャムの意味はdictionary.comから引用しました
したがって、SBERT では、同じ BERT ネットワークが「双子」として接続されています。モデルは、最初の文を 2 つに続けて処理するのではなく、最初の文を埋め込み、その後に 2 番目の文を埋め込みます。
注: シャムネットワークを視覚化するために、2 つのネットワークを並べて描画することは、非常に一般的な方法です。ただし、実際には、2 つの異なる入力を受け取る単一のネットワークです。
SBERT アーキテクチャ
以下は、SBERT アーキテクチャの概要を示す図です。


損失の分類目的を持つシャムネットワークアーキテクチャ。2つのブランチからの出力UとVは、それらの差とともに連結されます。
。
まず、SBERT は BERT のすぐ後にプーリング レイヤーを導入していることに気がつくでしょう。これにより、BERT の出力の次元が削減され、計算量が削減されます。BERT は通常、512 x 768 次元の出力を生成します。プーリング レイヤーはこれを 1 x 768 に削減します。デフォルトのプーリングは平均ですが、平均プーリングと最大プーリングも機能します。
次に、SBERT が BERT と異なるトレーニング アプローチを見てみましょう。
事前トレーニング
SBERT はモデルをトレーニングする 3 つの方法を提案しています。それぞれ見てみましょう。
自然言語推論 (NLI) — 分類の目的
SBERT は、このためにスタンフォード自然言語推論 (SNLI) とマルチジャンル NLI データセットで微調整されています。SNLI は 57 万の文のペアで構成され、MNLI は 43 万の文のペアで構成されています。ペアには前提 (P) と仮説 (H) があり、3 つのラベルのいずれかにつながります。
- エルテイメント — 前提は仮説を示唆する
- 中立 - 前提と仮説は真実かもしれないが、必ずしも関連しているわけではない
- 矛盾 — 前提と仮説が互いに矛盾している
2 つの文 P と H が与えられると、SBERT モデルは 2 つの出力 U と V を生成します。これらは (U、V、|U — V|) として連結されます。
連結された出力は、分類目標を使用して SBERT をトレーニングするために使用されます。この連結された出力は、3 つのクラス出力 (Eltailment、Neutral、Contradiction) を持つフィードフォワード ニューラル ネットワークに送られます。他の分類タスクのトレーニングと同様に、トレーニングには Softmax クロスエントリが使用されます。
文の類似性 — 回帰目的
U と V を連結する代わりに、2 つのベクトル間のコサイン類似度を直接計算します。標準的な回帰問題と同様に、平均二乗誤差損失を使用して回帰をトレーニングします。推論中は、同じネットワークを直接使用して任意の 2 つの文を比較できます。SBERT は、2 つの文がどの程度類似しているかを示すスコアを提供します。
トリプレット類似性 — トリプレット目的
トリプレット類似性目標は、顔認識で最初に導入され、テキストやロボット工学などの AI の他の分野にも徐々に適応されてきました。
ここでは、アンカー、ポジティブ、ネガティブの 2 つではなく 3 つの入力が SBERT に入力されます。これに使用するデータセットは、それに応じて選択する必要があります。これを作成するには、任意のテキスト データを選択し、連続する 2 つの文をポジティブな含意として選択します。次に、別の段落からランダムに文を 1 つ選択してネガティブ サンプルを作成します。
次に、ポジティブがアンカーにどれだけ近いかとネガティブがどれだけ近いかを比較して、トリプレット損失を計算します。


BERT と SBERT の紹介を踏まえて、これらのモデルを使用して任意の文の埋め込みを取得する方法を理解するために、簡単なハンズオンを実施してみましょう。
実践的なSBERT
SBERT の公式ライブラリであるsentence-transformer公開されて以来、人気が高まり成熟してきました。RAG の実際のユースケースで使用できるほど優れています。では、そのまま使用してみましょう。
まず、新しい Python 環境にインストールすることから始めましょう。
!pip install sentence-transformers
ライブラリからロードできる SBERT モデルにはいくつかのバリエーションがあります。説明のためにモデルをロードしてみましょう。
from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens')
文のリストを作成し、モデルのencode関数を呼び出して埋め込みを作成するだけです。とても簡単です!
sentences = [ "The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium.", ] embeddings = model.encode(sentences) print(embeddings.shape)
そして、以下の 1 行を使用して、埋め込み間の類似度スコアを見つけることができます。
similarities = model.similarity(embeddings, embeddings) print(similarities)
同じ文間の類似度は予想どおり 1 であることに注意してください。
tensor([[1.0000, 0.6660, 0.1046], [0.6660, 1.0000, 0.1411], [0.1046, 0.1411, 1.0000]])結論
埋め込みは、RAG パイプラインを最適に動作させるための重要かつ基本的なステップです。この記事がお役に立ち、センテンス トランスフォーマーをすぐに使用するたびに、裏側で何が起こっているのかについて理解を深めていただけたら幸いです。
RAG とその内部の仕組み、および実践的なチュートリアルに関する今後の記事もお楽しみに。








