






















Šis straipsnis pradedamas nuo transformatorių ir apžvelgiami jo trūkumai kaip įterpimo modelis. Tada pateikiama BERT apžvalga ir giliai įsigilinta į sakinį BERT (SBERT), kuris yra naujausias LLM ir RAG vamzdynų sakinių įterpimo technologijas.
Vizualus paaiškinimas
Jei esate vaizdingas žmogus kaip aš ir norėtumėte žiūrėti vaizdinį paaiškinimą, žiūrėkite šį vaizdo įrašą:
Transformatoriai
Transformatorių pristatyti nereikia. Nors iš pradžių jie buvo sukurti kalbų vertimo užduotims, šiandien jie yra beveik visų LLM varomieji žirgai.
Aukštu lygiu jie susideda iš dviejų blokų - kodavimo ir dekoderio. Kodavimo blokas priima įvestį ir išveda matricos vaizdą. Dekoderio blokas priima paskutinio kodavimo įrenginio išvestį ir sukuria išvestį. Kodavimo ir dekodavimo blokai gali būti sudaryti iš kelių sluoksnių, nors originalus transformatorius turi 6 sluoksnius kiekviename bloke.


Visi sluoksniai susideda iš daugiagalvio dėmesio sau. Tačiau vienintelis skirtumas tarp kodavimo ir dekoderio yra tas, kad kodavimo įrenginio išvestis tiekiama į kiekvieną dekoderio sluoksnį. Kalbant apie dėmesio sluoksnius, dekoderio dėmesio sluoksniai yra užmaskuoti. Taigi, išvestis bet kurioje padėtyje turi įtakos ankstesnių pozicijų išvestis.
Kodavimo ir dekodavimo blokai taip pat yra sudaryti iš standartinio sluoksnio ir nukreipimo į priekį neuroninio tinklo sluoksnių.
Skirtingai nuo ankstesnių modelių, tokių kaip RNN ar LSTM, kurie savarankiškai apdorojo žetonus, transformatorių galia priklauso nuo jų gebėjimo užfiksuoti kiekvieno žetono kontekstą visos sekos atžvilgiu. Taigi, ji užfiksuoja daug konteksto, palyginti su bet kokia ankstesne architektūra, skirta kalbos apdorojimui.
Kas negerai su transformeriais?
Transformatoriai yra sėkmingiausios architektūros, kurios šiandien skatina dirbtinio intelekto revoliuciją. Taigi, man gali būti parodytos durys, jei tiksliai nustatysiu apribojimus. Tačiau, tiesą sakant, siekiant sumažinti skaičiavimo išlaidas, jo dėmesio sluoksniai yra skirti tik praeities žetonų priežiūrai. Tai tinka daugeliui užduočių. Tačiau to gali nepakakti tokiai užduočiai kaip atsakymas į klausimus. Paimkime žemiau pateiktą pavyzdį.
Jonas atvyko su Milo į vakarėlį. Milo vakarėlyje buvo labai smagu. Jis yra gražus, baltas katinas su kailiu.
Tarkime, užduodame klausimą: „Ar Milo gėrė vakarėlyje su Džonu? Remiantis pirmaisiais 2 sakiniais aukščiau pateiktame pavyzdyje, labai tikėtina, kad LLM atsakys: „Atsižvelgiant į tai, kad Milo buvo labai smagu, reiškia, kad Milo vakarėlyje gėrė“.
Tačiau modelis, apmokytas prie konteksto, žinotų trečiąjį sakinį, kuris yra: „Jis yra graži, draugiška katė “. Ir taip, atsakyčiau: „Milo yra katė, todėl mažai tikėtina, kad jis gėrė vakarėlyje“.
Nors tai yra hipotetinis pavyzdys, supranti. Atliekant atsakymų į klausimus užduotį, labai svarbu mokytis pirmyn ir atgal konteksto. Čia atsiranda BERT modelis.
BERT
BERT reiškia Transformatorių dvikrypčių kodavimo įrenginių reprezentacijas. Kaip rodo pavadinimas, jis yra pagrįstas Transformatoriais ir apima tiek pirmyn, tiek atgal kontekstą. Nors iš pradžių jis buvo paskelbtas tokioms užduotims kaip atsakymas į klausimus ir apibendrinimas, dėl savo dvikrypčio pobūdžio jis gali sukurti galingus įterpimus.
BERT modelis
BERT yra ne kas kita, kaip nuosekliai sukrauti transformatorių kodavimo įrenginiai. Vienintelis skirtumas yra tas, kad BERT naudoja dvikryptį savęs dėmesį , o vanilės transformatorius naudoja suvaržytą savęs dėmesį, kai kiekvienas prieigos raktas gali atsižvelgti tik į kontekstą, esantį jo kairėje.
Pastaba: seka prieš sakinį. Tik pastaba dėl terminijos, kad būtų išvengta painiavos dirbant su BERT modeliu. Sakinys yra žodžių, atskirtų taškais, serija. Seka gali būti bet koks sakinių skaičius, sukrautas kartu.
Norėdami suprasti BERT, paimkime atsakymo į klausimą pavyzdį. Kadangi atsakymas į klausimus apima mažiausiai du sakinius, BERT yra sukurta priimti sakinių porą formatu <klausimas-atsakymas>. Dėl to pradžioje perduodami skyriklio žetonai, pvz., [CLS], nurodantys sekos pradžią. Tada [SEP] prieigos raktas naudojamas atskirti klausimą ir atsakymą.
Taigi, paprasta įvestis dabar tampa [CLS]<klausimas>[SEP]<atsakymas>[SEP], kaip parodyta toliau pateiktame paveikslėlyje.


Du sakiniai A ir B perduodami per WordPiece įdėjimo modelį, įtraukus [CLS] ir [SEP] prieigos raktus. Kadangi turime du sakinius, modeliui reikia papildomų įterpimų, kad būtų galima juos atskirti. Tai pateikiama segmentų ir pozicijų įterpimo forma.
Toliau žalia spalva rodomas segmento įterpimas rodo, ar įvesties žetonai priklauso sakiniui A ar B. Tada ateina pozicijos įterpimas, kuris nurodo kiekvieno atpažinimo ženklo padėtį sekoje.


Paveikslas paimtas iš BERT dokumento, kuriame parodytas modelio įvesties vaizdas.
Visi trys įterpimai sumuojami ir įvedami į BERT modelį, kuris yra dvikryptis, kaip parodyta ankstesniame paveikslėlyje. Jis užfiksuoja ne tik pirminį, bet ir atgalinį kontekstą, prieš pateikdamas kiekvieno prieigos rakto išvestis.
Išankstinis mokymas BERT
Yra du būdai, kaip BERT modelis iš anksto apmokomas naudojant dvi neprižiūrimas užduotis:
Užmaskuotos kalbos modelis (MLM). Čia mes užmaskuojame kai kuriuos sekos žetonų procentus ir leidžiame modeliui numatyti užmaskuotus žetonus. Tai taip pat žinoma kaip užrakinimo užduotis. Praktiškai šiai užduočiai užmaskuoti 15% žetonų.
Kito sakinio numatymas (NSP). Čia mes priverčiame modelį numatyti kitą sekos sakinį. Kai sakinys yra tikrasis kitas sakinys, naudojame etiketę
IsNext, o kai ne, naudojame etiketęNotNext.



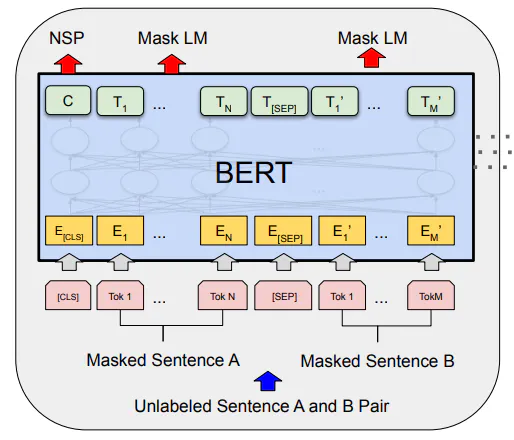
Kaip matyti iš aukščiau pateikto paveikslo iš popieriaus, pirmasis išvesties prieigos raktas naudojamas NSP užduočiai, o viduryje esantys užmaskuoti žetonai naudojami MLM užduočiai.
Kadangi mokomės prieigos rakto lygiu, kiekvienas įvesties prieigos raktas sukuria išvesties prieigos raktą. Kaip ir atliekant bet kurią klasifikavimo užduotį, modeliui mokyti naudojamas kryžminės entropijos praradimas.
Kas negerai su BERT?
Nors BERT galėtų gerai užfiksuoti tiek pirmyn, tiek atgal kontekstą, ji gali būti netinkama norint rasti panašumų tarp tūkstančių sakinių. Panagrinėkime užduotį rasti panašiausią sakinių porą didelėje 10 000 sakinių kolekcijoje. Kitaip tariant, iš 10 000 sakinių norėtume „atgauti“ sakinį, kuris labiausiai panašus į A sakinį.
Norėdami tai padaryti, turime suporuoti kiekvieną įmanomą 2 sakinių derinį iš 10 000. Tai būtų n * (n — 1) / 2 = 4 999 500 porų! Po velnių, tai kvadratinis sudėtingumas. BERT modelis užtruks 65 valandas, kad sukurtų įterpimus ir išspręstų šį palyginimą.
Paprasčiau tariant, BERT modelis nėra geriausias panašumų paieškai. Tačiau paieška ir panašumų paieška yra bet kurio RAG dujotiekio pagrindas. Sprendimas priklauso SBERT.
SBERT – sakinio lygio BERT
BERT apribojimas daugiausia kyla dėl kryžminio kodavimo architektūros , kai pateikiame du sakinius iš eilės su [SEP] prieigos raktu. Jei tik kiekvienas sakinys būtų nagrinėjamas atskirai, galėtume iš anksto apskaičiuoti įterpimus ir tiesiogiai juos naudoti, kad skaičiuotume panašiai, kai reikia. Būtent toks yra sakinio BERT arba trumpai SBERT pasiūlymas.
SBERT pristato Siamo tinklą BERT architektūrai. Žodis reiškia dvynį arba glaudžiai giminingą.


Siamo reikšmė paimta iš dictionary.com
Taigi, SBERT turime tą patį BERT tinklą, prijungtą kaip „dvyniai“. Modelis įterpia pirmąjį sakinį, po kurio seka antrasis, o ne nagrinėja juos nuosekliai.
Pastaba: Gana įprasta praktika nubrėžti du tinklus vienas šalia kito, kad būtų galima vizualizuoti Siamo tinklus. Tačiau praktiškai tai yra vienas tinklas, kuriame yra du skirtingi įėjimai.
SBERT architektūra
Žemiau yra diagrama, kurioje pateikiama SBERT architektūros apžvalga.


Siamo tinklo architektūra su nuostolių klasifikavimo tikslu. Dviejų šakų išėjimai U ir V yra sujungti kartu su jų skirtumu
.
Pirma, galime pastebėti, kad SBERT netrukus po BERT pristato telkimo sluoksnį. Tai sumažina BERT išvesties matmenis, kad būtų sumažintas skaičiavimas. BERT paprastai gamina 512 x 768 matmenų išvestis. Sujungimo sluoksnis sumažina tai iki 1 x 768. Numatytasis telkimas yra vidutiniškas, nors vidutinis ir maksimalus telkimas veikia.
Toliau pažvelkime į mokymo metodą, kai SBERT skiriasi nuo BERT.
Išankstinis mokymas
SBERT siūlo tris modelio mokymo būdus. Pažvelkime į kiekvieną iš jų.
Natūralios kalbos išvada (NLI) – klasifikavimo tikslas
Tam SBERT yra tiksliai suderinta Stanfordo natūralios kalbos išvados (SNLI) ir kelių žanrų NLI duomenų rinkiniuose. SNLI sudaro 570 tūkst. sakinių porų, o MNLI – 430 tūkst. Poros turi prielaidą (P) ir hipotezę (H), vedančią į vieną iš 3 etikečių:
- Eltailment – prielaida siūlo hipotezę
- Neutrali – prielaida ir hipotezė gali būti teisingos, bet nebūtinai susijusios
- Prieštaravimas - prielaida ir hipotezė prieštarauja viena kitai
Atsižvelgiant į du sakinius P ir H, SBERT modelis sukuria du išėjimus U ir V. Tada jie sujungiami kaip (U, V ir |U – V|).
Sujungta išvestis naudojama apmokyti SBERT pagal klasifikavimo tikslą. Ši sujungta išvestis tiekiama į „Fed Forward“ neuroninį tinklą su 3 klasės išėjimais (Eltailment, Neutral ir Contradiction). Softmax kryžminis įrašas naudojamas treniruotėms, panašiai kaip treniruojamės atliekant bet kurią kitą klasifikavimo užduotį.
Sakinio panašumas – regresijos tikslas
Užuot sujungę U ir V, mes tiesiogiai apskaičiuojame kosinuso panašumą tarp dviejų vektorių. Panašiai kaip ir bet kuri standartinė regresijos problema, regresijai mokyti naudojame vidutinės kvadratinės klaidos praradimą. Darant išvadą, tas pats tinklas gali būti tiesiogiai naudojamas bet kuriems dviem sakiniams palyginti. SBERT pateikia balą, kiek panašūs abu sakiniai.
Trigubo panašumas – trigubo tikslas
Trigubo panašumo tikslas pirmą kartą buvo pristatytas veido atpažinimo srityje ir pamažu buvo pritaikytas kitoms AI sritims, tokioms kaip tekstas ir robotika.
Čia į SBERT įvedami 3 įėjimai, o ne 2 – inkaras, teigiamas ir neigiamas. Tam naudojamas duomenų rinkinys turėtų būti atitinkamai parinktas. Norėdami jį sukurti, galime pasirinkti bet kokius tekstinius duomenis ir pasirinkti du iš eilės sakinius kaip teigiamą prielaidą. Tada pasirinkite atsitiktinį sakinį iš kitos pastraipos neigiamą pavyzdį.
Tada apskaičiuojamas trigubas nuostolis, lyginant, kaip arti teigiamas yra inkaras su tuo, kaip arti jis yra neigiamas.


Įvade į BERT ir SBERT pabandykime greitai suprasti, kaip naudojant šiuos modelius galime įterpti bet kurį (-ius) sakinį (-ius).
Praktinis SBERT
Net nuo pat paskelbimo oficiali SBERT biblioteka, kuri yra sentence-transformer išpopuliarėjo ir subrendo. Jis yra pakankamai geras, kad būtų galima naudoti RAG gamybos atveju. Taigi naudokite jį iš dėžutės.
Norėdami pradėti, pradėkime nuo diegimo naujoje naujoje Python aplinkoje.
!pip install sentence-transformers
Yra keletas SBERT modelio variantų, kuriuos galime įkelti iš bibliotekos. Įkelkime modelį iliustracijai.
from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens')
Galime tiesiog sukurti sakinių sąrašą ir iškviesti modelio encode funkciją, kad sukurtume įterpimus. Tai taip paprasta!
sentences = [ "The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium.", ] embeddings = model.encode(sentences) print(embeddings.shape)
Ir mes galime rasti įdėjimų panašumo balus naudodami toliau pateiktą 1 eilutę:
similarities = model.similarity(embeddings, embeddings) print(similarities)
Atkreipkite dėmesį, kad to paties sakinio panašumas yra 1, kaip ir tikėtasi:
tensor([[1.0000, 0.6660, 0.1046], [0.6660, 1.0000, 0.1411], [0.1046, 0.1411, 1.0000]])Išvada
Įterpimas yra esminis ir esminis žingsnis siekiant, kad RAG dujotiekis veiktų geriausiai. Tikimės, kad tai buvo naudinga ir atvėrė jums akis, kas vyksta po gaubtu, kai naudojame sakinio transformatorius iš dėžutės.
Stebėkite būsimus straipsnius apie RAG ir jo vidinę veiklą bei praktines pamokas.




