























لنکس کی میز
ڈومین اور ٹاسک
متعلقہ کام
3.1 ٹیکسٹ مائننگ اور NLP تحقیق کا جائزہ
3.2 صنعت کے استعمال میں ٹیکسٹ مائننگ اور این ایل پی
تجربہ اور مظاہرہ
بحث
2. ڈومین اور ٹاسک
یہ کام صحت کی دیکھ بھال کے حصول پر مرکوز ہے، جس کا ادب میں شاذ و نادر ہی مطالعہ کیا گیا ہے۔ پروجیکٹ کا بنیادی مقصد ایک ایسا پلیٹ فارم تیار کرنا ہے جو ہر ہیلتھ کیئر سپلائر کے لیے 'سپلائر رسک پروفائل' کی متحرک تخلیق کی اجازت دیتا ہے۔ ہم ایسے پروفائل کا تصور کرتے ہیں جو مختلف 'انڈیکسز' پر مشتمل ہو جو ممکنہ خریداروں کے لیے سپلائر کے ساتھ معاہدوں پر دستخط کرنے کے لیے 'خطرات' کے مختلف تناظر (مثلاً، بعض مصنوعات کی فراہمی کی صلاحیت، جغرافیائی کوریج) کا جائزہ لیتے ہیں۔ اس سے سوالات جیسے کہ 'اس قسم کی دوائی فراہم کرنے والے کون ہیں'، 'وہ اس ملک کے لیے کس حد تک سپلائی کرنے کے قابل ہیں'، یا 'کیا وہ اتنی مقدار میں سپلائی کرنے کے قابل ہیں' جیسے سوالات کا آسانی سے جواب دیا جا سکے گا۔ خریداروں کے فیصلے کرنے کے لیے اس طرح کے سوالات اکثر اہم ہوتے ہیں۔ تاہم، موجودہ خریداری کا عمل جوابات حاصل کرنے کے لیے متعدد طویل دستاویزات کو دستی طور پر چھاننے پر انحصار کرتا ہے۔ یہ ایک بہت ہی وسائل استعمال کرنے والا عمل ہے۔ قابل فہم طور پر، ہمارے بنیادی مقصد کو فعال کرنے والا صحت کی دیکھ بھال فراہم کرنے والوں کے تاریخی معاہدے کے ڈیٹا کا ایک منظم ڈیٹا بیس ہوگا۔ اس طرح پراجیکٹ کا ثانوی مقصد اس طرح کے ڈیٹا بیس کو تیار کرنا اور اسے صحت کی دیکھ بھال کے تاریخی ڈیٹا کے ساتھ آباد کرنا ہے۔ اگرچہ پبلک پروکیورمنٹ ڈیٹا وسیع پیمانے پر دستیاب ہے، جیسا کہ ہم مندرجہ ذیل میں وضاحت کریں گے، ساختہ، نیم ساختہ، اور غیر ساختہ کثیر لسانی ڈیٹا کا ایک مرکب ہے جس کی کان کنی اور لنک کرنے کی ضرورت ہے۔ لہذا، پروجیکٹ کے کام کا ایک بڑا حصہ ٹیکسٹ مائننگ اور NLP حل تیار کرنا ہے جو خود بخود غیر ساختہ پروکیورمنٹ ڈیٹا کی بڑی مقدار کو مائن معلومات کے لیے پروسیس کرتا ہے جو ڈیٹا بیس کو آباد کرنے کے لیے استعمال کیا جا سکتا ہے۔ اس لیے اس مضمون کا مقصد ان ٹیکسٹ مائننگ اور NLP طریقوں کی ترقی کی اطلاع دینا ہے۔
2.1 ڈیٹا کے ذرائع اور پیچیدگی
اس پروجیکٹ کا ہدف 'ٹینڈرز الیکٹرانک ڈیلی' (TED) پلیٹ فارم سے حصولی کے ڈیٹا کو ہے، جسے یورپی یونین کی حکومتیں اپنے پبلک پروکیورمنٹ سے متعلق منصوبوں کو شائع کرنے کے لیے استعمال کرتی ہیں۔ TED ہر سال 26 سرکاری یورپی زبانوں میں ٹینڈرز اور کنٹریکٹ ایوارڈز کے لیے 460,000 کالز شائع کرتا ہے، جس کی قیمت تقریباً 420 بلین یورو ہے۔ ہر ٹینڈر کو متعدد 'لاٹس' میں تقسیم کیا جا سکتا ہے، جہاں لاٹ سب سے چھوٹی کنٹریکٹ یونٹ ہے۔ ہر لاٹ میں متعدد اشیاء شامل ہوسکتی ہیں جن کی ضرورت ہے۔ مثال کے طور پر، ٹینڈر نوٹس '2019/S 180-437985'[1] میں NHS (UK) کے ٹینڈر سے 47 لاٹوں کی فہرست دی گئی ہے، جس کے سائز 2 سے 30 آئٹمز کے درمیان ہیں۔ اگر کوئی ٹینڈر کامیاب بولیاں حاصل کرتا ہے، تو ٹینڈر کے لیے 'کنٹریکٹ ایوارڈ' (یا متعدد ایوارڈز) بنائے جائیں گے اور اسے TED میں ریکارڈ کیا جائے گا۔ مندرجہ ذیل میں، وضاحت کی خاطر، ہم فرض کرتے ہیں کہ ہر ٹینڈر کے لیے ایک ایوارڈ ہے (تاہم عملی طور پر، ہمارے طریقے ان تمام ایوارڈز پر لاگو ہوتے ہیں جو ٹینڈر کے لیے دستیاب ہیں)۔ ایک ٹینڈر میں پیش کردہ لاٹوں کو نوٹ کریں اور کنٹریکٹ ایوارڈز ایک 'بہت سے زیادہ' رشتہ بناتے ہیں۔ یعنی، ایک ہی ہستی کو متعدد لاٹ دیئے جا سکتے ہیں اور ایک کنٹریکٹ ایوارڈ میں دستاویز کی جا سکتی ہے۔ ایک ہی لاٹ متعدد اداروں کو بھی دیا جا سکتا ہے، جس سے متعدد کنٹریکٹ ایوارڈز بنتے ہیں۔ مزید ایک کنٹریکٹ ایوارڈ میں ایک یا ایک سے زیادہ لاٹ شامل ہو سکتے ہیں۔
TED پر، ہر ٹینڈر اور اس سے متعلقہ کنٹریکٹ ایوارڈز میں ایک سٹرکچرڈ XML فائل ہوتی ہے جس میں معلومات کے اہم عناصر کو دستاویز کیا جاتا ہے۔ ہم ان کو 'ٹینڈر XML' اور 'ایوارڈ XML' کے طور پر حوالہ دیتے ہیں۔ ٹینڈر XML کی ایک مثال تصویر 1 میں دکھائی گئی ہے۔ ایوارڈ XMLs عام طور پر اسی ڈھانچے کی پیروی کرتے ہیں۔ ٹینڈر XMLs دستاویز کی معلومات جیسے خریدار، لاٹ، آئٹمز آف لاٹ، کنٹریکٹ کا معیار وغیرہ۔ ایوارڈ XMLs خریدار، لاٹ، ہر لاٹ کے لیے عطا کردہ سپلائرز، معاہدہ کی قیمت، مقدار وغیرہ کی دستاویز کرتا ہے۔ 'ملحقہ دستاویزات' کا مجموعہ جو ٹینڈر کی مزید تفصیلات فراہم کرتا ہے، خاص طور پر لاٹوں اور اشیاء پر ('ٹینڈر منسلکات')


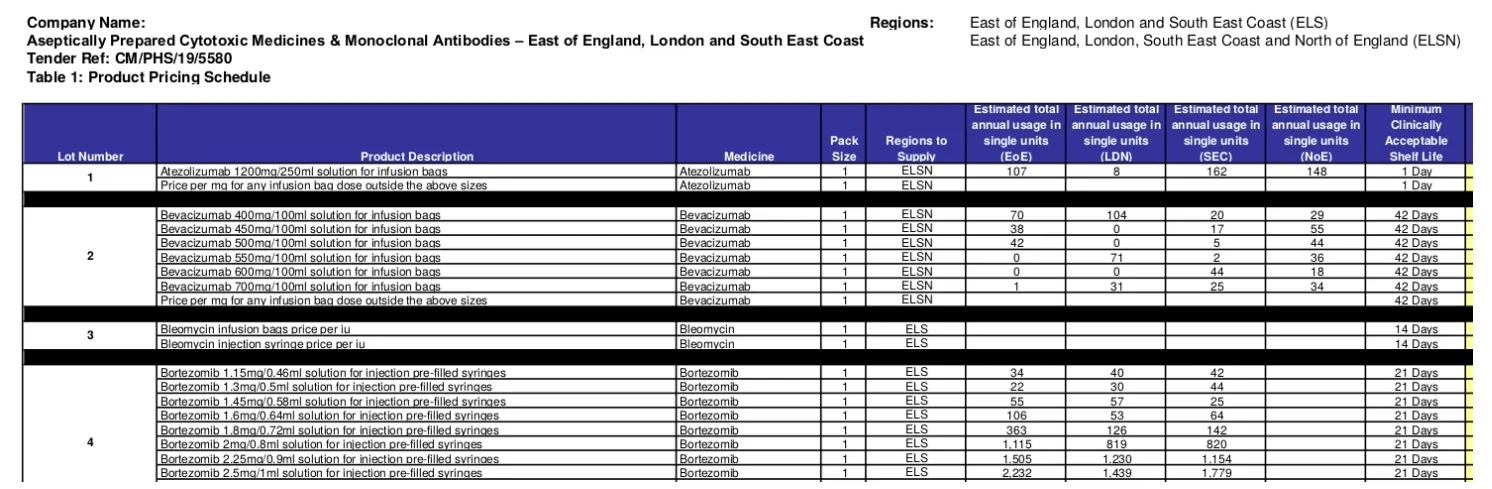
ٹینڈر اور ایوارڈ XMLs کی دستیابی کو دیکھتے ہوئے، کوئی بھی ڈیٹا بیس کو تیار کرنے اور اسے آباد کرنے کے کام کو آسان سمجھ سکتا ہے۔ تاہم، حقیقت میں ڈیٹا کہیں زیادہ پیچیدہ ہے۔ سب سے پہلے، ٹینڈر اور ایوارڈ XMLs اکثر نامکمل ہوتے ہیں۔ غالب گمشدہ معلومات بہت اور آئٹم کی معلومات ہیں۔ مثال کے طور پر، '2019/S 180-437985' کے لیے ٹینڈر XML، ٹینڈر میں 47 لاٹوں کا تذکرہ کرتا ہے، مخصوص اشیاء کی تفصیل کے بغیر لیکن بہت زیادہ حوالہ نمبر۔ یہ اہم معلومات 7 ٹینڈر منسلکات (PDFs) کے بلک ڈاؤن لوڈ سے دستیاب ہے۔ دونوں ٹینڈر اور ایوارڈ XMLs پھر لاٹ حوالہ جات کے استعمال کے ذریعے ان ڈیٹا کے ذرائع کا کراس حوالہ دیتے ہیں۔ اس طرح کی معلومات کو بازیافت کرنا سپلائر کے خطرے کا پروفائل بنانے کے لیے بہت ضروری ہے، جس میں مصنوعات کی رینج اور مقدار کا حساب ہونا ضروری ہے جو ایک سپلائر نے ماضی میں فراہم کیے ہیں۔ دوسرا، ہر ٹینڈر منسلکہ ہمارے مقصد سے متعلق نہیں ہے۔ '2019/S 180-437985' کے لیے، دو پی ڈی ایف میں اصل لاٹ اور آئٹمز کی فہرست ہے (مثال کے طور پر، شکل 2)، جب کہ دیگر دستاویزات کی وضاحتیں، ضروریات، ضوابط اور پروٹوکول وغیرہ۔ تیسرا، متعلقہ اٹیچمنٹ کا ہر صفحہ متعلقہ پر مشتمل نہیں ہے۔ معلومات مثال کے طور پر، شکل 3 سے پتہ چلتا ہے کہ ایک اور ٹینڈر میں، لاٹ اور آئٹمز کو ایک صفحے میں بیان کیا گیا ہے لیکن ایک طویل دستاویز کے مختلف حصوں میں۔ چوتھا، جیسا کہ یہ پہلے ہی اعداد و شمار 2 اور 3 میں دکھایا گیا ہے، ایک ہی ملک، یا درحقیقت، یہاں تک کہ ایک ہی تنظیم کے اندر کتنی لاٹ اور آئٹم کی معلومات بیان کی گئی ہیں اس میں ایک اہم تضاد ہے۔ یہ تضاد مختلف سطحوں پر دیکھا گیا ہے جیسے: ساختی فارمیٹنگ کا استعمال (مثلاً، مفت متن بمقابلہ میزیں/ فہرستیں)؛ انکوڈ شدہ معلومات کی مقدار (مثال کے طور پر، شکل 2 میں ٹیبل ہر آئٹم کے لیے 16 کالم (صفات) کی فہرست دیتا ہے) یہاں تک کہ ایک ہی قسم کی مصنوعات/خدمات کے لیے بھی؛ اور ساخت کی اصطلاحات جہاں ڈھانچے کو اپنایا جاتا ہے (مثال کے طور پر، کالموں کی ترتیب اور نام)۔ اس طرح کی اعلیٰ سطح کی پیچیدگی اور عدم مطابقت ایک بڑی وجہ ہو سکتی ہے کہ ٹیکسٹ مائننگ اور NLP اسٹڈیز یا ہیلتھ کیئر پروکیورمنٹ کے لیے درخواستوں کی کمی ہے۔


مصنفین:
(1) Ziqi Zhang*, Information School, University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected])؛
(2) Tomas Jasaitis, Vamstar Ltd., London ([email protected])؛
(3) رچرڈ فری مین، ویم اسٹار لمیٹڈ، لندن ([email protected])؛
(4) رویدا الفرجانی، انفارمیشن سکول، یونیورسٹی آف شیفیلڈ، ریجنٹ کورٹ، شیفیلڈ، UKS1 4DP ([email protected])؛
(5) ایڈم فنک، انفارمیشن سکول، یونیورسٹی آف شیفیلڈ، ریجنٹ کورٹ، شیفیلڈ، UKS1 4DP ([email protected])۔
یہ کاغذ ہے۔
[1] https://ted.europa.eu/udl?uri=TED:NOTICE:437985-2019:TEXT:EN:HTML، آخری بار رسائی کی گئی: نومبر 2022








