























តារាងតំណភ្ជាប់
ដែន និងកិច្ចការ
ការងារពាក់ព័ន្ធ
៣.១. ការជីកយករ៉ែអត្ថបទ និងទិដ្ឋភាពទូទៅនៃការស្រាវជ្រាវ NLP
៣.២. ការជីកយករ៉ែអត្ថបទ និង NLP ក្នុងការប្រើប្រាស់ឧស្សាហកម្ម
៤.៦. ការញែក XML ការភ្ជាប់ទិន្នន័យ និងការអភិវឌ្ឍន៍សន្ទស្សន៍ហានិភ័យ
ការពិសោធន៍និងការបង្ហាញ
ការពិភាក្សា
៦.១. ការផ្តោតអារម្មណ៍ 'ឧស្សាហកម្ម' នៃគម្រោង
៦.២. ភាពខុសគ្នានៃទិន្នន័យ ពហុភាសា និងធម្មជាតិនៃកិច្ចការច្រើន។
2. ដែន និងកិច្ចការ
ការងារនេះផ្តោតលើលទ្ធកម្មថែទាំសុខភាព ដែលកម្រត្រូវបានសិក្សាក្នុងអក្សរសិល្ប៍។ គោលដៅចម្បងនៃគម្រោងគឺដើម្បីបង្កើតវេទិកាមួយដែលអនុញ្ញាតឱ្យបង្កើត 'ទម្រង់ហានិភ័យរបស់អ្នកផ្គត់ផ្គង់' សម្រាប់អ្នកផ្គត់ផ្គង់ការថែទាំសុខភាពនីមួយៗ។ យើងស្រមៃមើលទម្រង់បែបនេះដើម្បីឱ្យមាន 'សន្ទស្សន៍' ផ្សេងៗគ្នាដែលវាយតម្លៃទស្សនៈផ្សេងៗគ្នា (ឧទាហរណ៍ សមត្ថភាពផ្គត់ផ្គង់ផលិតផលជាក់លាក់ ការគ្របដណ្តប់ភូមិសាស្ត្រ) នៃ 'ហានិភ័យ' សម្រាប់អ្នកទិញសក្តានុពលក្នុងការចុះកិច្ចសន្យាជាមួយអ្នកផ្គត់ផ្គង់។ នេះនឹងអនុញ្ញាតឱ្យសំណួរដូចជា 'តើអ្នកណាជាអ្នកផ្គត់ផ្គង់អាចផ្គត់ផ្គង់ថ្នាំប្រភេទនេះ' 'តើពួកគេអាចផ្គត់ផ្គង់សម្រាប់ប្រទេសនេះដល់កម្រិតណា' ឬ 'តើពួកគេអាចផ្គត់ផ្គង់បរិមាណនេះបានទេ' ដើម្បីងាយស្រួលឆ្លើយ។ សំណួរបែបនេះច្រើនតែមានសារៈសំខាន់សម្រាប់ការសម្រេចចិត្តរបស់អ្នកទិញ។ ទោះជាយ៉ាងណាក៏ដោយ ដំណើរការលទ្ធកម្មបច្ចុប្បន្នពឹងផ្អែកលើការរុះរើដោយដៃតាមរយៈឯកសារវែងៗជាច្រើន ដើម្បីស្វែងរកចម្លើយ។ នេះគឺជាដំណើរការប្រើប្រាស់ធនធានយ៉ាងខ្លាំង។ ជាការយល់ច្បាស់ អ្នកបង្កើតគោលដៅចម្បងរបស់យើងនឹងក្លាយជាមូលដ្ឋានទិន្នន័យដែលមានរចនាសម្ព័ន្ធនៃទិន្នន័យកិច្ចសន្យាជាប្រវត្តិសាស្ត្ររបស់អ្នកផ្គត់ផ្គង់ការថែទាំសុខភាព។ ដូច្នេះ គោលដៅបន្ទាប់បន្សំនៃគម្រោងគឺដើម្បីបង្កើតមូលដ្ឋានទិន្នន័យបែបនេះ ហើយបញ្ចូលវាជាមួយនឹងទិន្នន័យលទ្ធកម្មការថែទាំសុខភាពជាប្រវត្តិសាស្ត្រ។ ខណៈពេលដែលទិន្នន័យលទ្ធកម្មសាធារណៈមានយ៉ាងទូលំទូលាយ ដូចដែលយើងនឹងពន្យល់នៅខាងក្រោមនេះ វាមានល្បាយនៃទិន្នន័យពហុភាសាដែលមានរចនាសម្ព័ន្ធ ពាក់កណ្តាលរចនាសម្ព័ន្ធ និងមិនមានរចនាសម្ព័ន្ធ ដែលត្រូវការរុករក និងភ្ជាប់។ ដូច្នេះផ្នែកសំខាន់នៃការងាររបស់គម្រោងគឺកំពុងបង្កើតការជីកយករ៉ែអត្ថបទ និងដំណោះស្រាយ NLP ដែលដំណើរការដោយស្វ័យប្រវត្តិនូវបរិមាណដ៏ធំនៃទិន្នន័យលទ្ធកម្មដែលមិនមានរចនាសម្ព័ន្ធចំពោះព័ត៌មានអណ្តូងរ៉ែដែលអាចត្រូវបានប្រើដើម្បីផ្ទុកមូលដ្ឋានទិន្នន័យ។ ដូច្នេះ គោលដៅនៃអត្ថបទនេះគឺដើម្បីរាយការណ៍ពីការអភិវឌ្ឍន៍នៃការជីកយករ៉ែអត្ថបទ និងវិធីសាស្ត្រ NLP ទាំងនេះ។
២.១. ប្រភពទិន្នន័យ និងភាពស្មុគស្មាញ
គម្រោងនេះផ្តោតលើទិន្នន័យលទ្ធកម្មពីវេទិកា 'Tenders Electronic Daily' (TED) ដែលត្រូវបានប្រើប្រាស់ដោយរដ្ឋាភិបាលសហភាពអឺរ៉ុបដើម្បីផ្សព្វផ្សាយគម្រោងទាក់ទងនឹងលទ្ធកម្មសាធារណៈរបស់ពួកគេ។ TED បោះពុម្ពផ្សាយជាង 460,000 ការអំពាវនាវសម្រាប់ការដេញថ្លៃ និងពានរង្វាន់កិច្ចសន្យាជាភាសាអឺរ៉ុបផ្លូវការចំនួន 26 ក្នុងមួយឆ្នាំ ក្នុងតម្លៃប្រហែល 420 ពាន់លានអឺរ៉ូ។ ការដេញថ្លៃនីមួយៗអាចត្រូវបានបែងចែកទៅជា 'ឡូតិ៍' ជាច្រើន ដែលច្រើនគឺជាឯកតាកិច្ចសន្យាតូចបំផុត។ ឡូតិ៍នីមួយៗអាចមានធាតុជាច្រើនដែលត្រូវការ។ ជាឧទាហរណ៍ សេចក្តីជូនដំណឹងអំពីការដេញថ្លៃ '2019/S 180-437985'[1] រាយបញ្ជីចំនួន 47 ពីការដេញថ្លៃ NHS (UK) ដោយទំហំរបស់ពួកគេមានចាប់ពី 2 ដល់ជាង 30 ធាតុ។ ប្រសិនបើការដេញថ្លៃធានាការដេញថ្លៃជោគជ័យ 'ពានរង្វាន់កិច្ចសន្យា' (ឬពានរង្វាន់ជាច្រើន) នឹងត្រូវធ្វើឡើង និងកត់ត្រានៅក្នុង TED សម្រាប់ការដេញថ្លៃ។ ខាងក្រោមនេះ ជាប្រយោជន៍នៃការពន្យល់ យើងសន្មត់ថាមានរង្វាន់មួយសម្រាប់ការដេញថ្លៃនីមួយៗ (ទោះជាយ៉ាងណានៅក្នុងការអនុវត្ត វិធីសាស្រ្តរបស់យើងត្រូវបានអនុវត្តចំពោះរង្វាន់ទាំងអស់ដែលមានសម្រាប់ការដេញថ្លៃ)។ ចំណាំការផ្តល់ជូននៅក្នុងការដេញថ្លៃមួយ ហើយរង្វាន់កិច្ចសន្យាបង្កើតបានជាទំនាក់ទំនង 'ច្រើនទៅច្រើន' ។ ពោលគឺ ដីឡូតិ៍ជាច្រើនអាចត្រូវបានប្រគល់ជូនអង្គភាពតែមួយ និងត្រូវបានចងក្រងជាឯកសារក្នុងពានរង្វាន់កិច្ចសន្យាតែមួយ។ មួយឡូតិ៍ក៏អាចត្រូវបានផ្តល់រង្វាន់ដល់អង្គភាពជាច្រើន បង្កើតជារង្វាន់កិច្ចសន្យាជាច្រើន; រង្វាន់កិច្ចសន្យាតែមួយអាចរួមបញ្ចូលមួយ ឬច្រើន។
នៅលើ TED ការដេញថ្លៃនីមួយៗ និងពានរង្វាន់កិច្ចសន្យាដែលត្រូវគ្នារបស់វាមានឯកសារ XML ដែលមានរចនាសម្ព័ន្ធដែលចងក្រងឯកសារសំខាន់ៗនៃព័ត៌មាន។ យើងសំដៅទៅលើទាំងនេះថាជា 'XML ដេញថ្លៃ' និង 'រង្វាន់ XML' ។ ឧទាហរណ៍នៃ XML ដេញថ្លៃត្រូវបានបង្ហាញក្នុងរូបភាពទី 1 ។ ពានរង្វាន់ XML ជាទូទៅធ្វើតាមរចនាសម្ព័ន្ធដូចគ្នា។ ឯកសារ XMLs នៃការដេញថ្លៃដូចជាអ្នកទិញ ដីឡូតិ៍ ធាតុនៃដីឡូតិ៍ លក្ខខណ្ឌនៃកិច្ចសន្យា។ល។ ពានរង្វាន់ XMLs កត់ត្រាអ្នកទិញ ឡូតិ៍ អ្នកផ្គត់ផ្គង់ដែលទទួលបានរង្វាន់សម្រាប់ឡូត៍នីមួយៗ តម្លៃកិច្ចសន្យា បរិមាណ។ល។ ការដេញថ្លៃនីមួយៗក៏អាចមាន ការប្រមូលផ្ដុំនៃ 'ឯកសារភ្ជាប់" ដែលផ្តល់ព័ត៌មានលម្អិតបន្ថែមនៃការដេញថ្លៃ ជាពិសេសលើចំនួន និងវត្ថុ ('ឯកសារភ្ជាប់ដេញថ្លៃ")


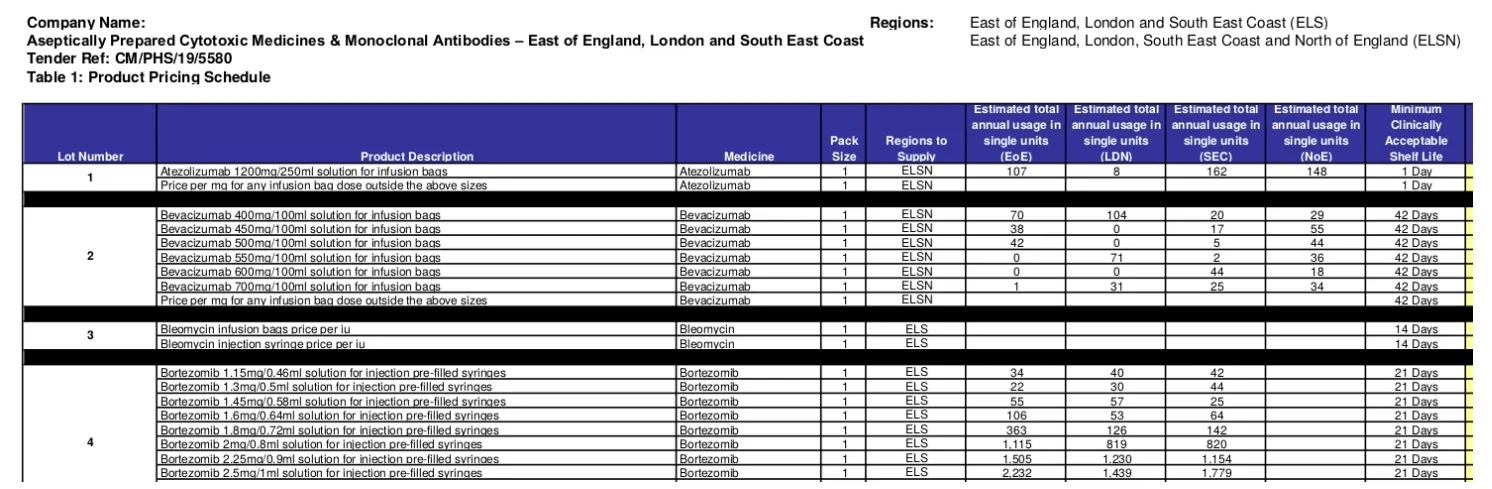
ដោយសារភាពអាចរកបាននៃការដេញថ្លៃ និងការផ្តល់រង្វាន់ XMLs មនុស្សម្នាក់អាចពិចារណាលើភារកិច្ចនៃការអភិវឌ្ឍន៍ និងបង្កើតមូលដ្ឋានទិន្នន័យឱ្យមានភាពងាយស្រួល។ ទោះជាយ៉ាងណាក៏ដោយ ទិន្នន័យនៅក្នុងការពិតគឺកាន់តែស្មុគស្មាញ។ ជាដំបូង និងសំខាន់បំផុត ការដេញថ្លៃ និងពានរង្វាន់ XML ជាញឹកញាប់មិនពេញលេញ។ ព័ត៌មានដែលបាត់លេចធ្លោជាងគេគឺព័ត៌មានច្រើន និងព័ត៌មាន។ ជាឧទាហរណ៍ ការដេញថ្លៃ XML សម្រាប់ '2019/S 180-437985' លើកឡើងចំនួន 47 នៅក្នុងការដេញថ្លៃ ដោយមិនលម្អិតអំពីធាតុជាក់លាក់ ប៉ុន្តែមានលេខយោងច្រើន។ ព័ត៌មានសំខាន់នេះអាចរកបានពីការទាញយកភាគច្រើននៃឯកសារភ្ជាប់ដេញថ្លៃចំនួន 7 (PDF) ។ ទាំង XMLs ដេញថ្លៃ និងផ្តល់រង្វាន់ បន្ទាប់មកឆ្លងកាត់ប្រភពទិន្នន័យទាំងនេះ តាមរយៈការប្រើប្រាស់ឯកសារយោងច្រើន។ ការយកមកវិញនូវព័ត៌មានបែបនេះគឺមានសារៈសំខាន់ណាស់ក្នុងការកសាងទម្រង់ហានិភ័យរបស់អ្នកផ្គត់ផ្គង់ ដែលចាំបាច់ត្រូវគិតគូរពីជួរ និងបរិមាណនៃផលិតផលដែលអ្នកផ្គត់ផ្គង់បានផ្គត់ផ្គង់នាពេលកន្លងមក។ ទីពីរ មិនមែនរាល់ឯកសារភ្ជាប់ដេញថ្លៃសុទ្ធតែពាក់ព័ន្ធសម្រាប់គោលបំណងរបស់យើងនោះទេ។ ក្នុងចំណោមឯកសារទាំងនោះសម្រាប់ '2019/S 180-437985' ឯកសារ PDF ពីររាយបញ្ជីចំនួន និងធាតុជាក់ស្តែង (ឧទាហរណ៍ រូបភាពទី 2) ខណៈពេលដែលឯកសារផ្សេងទៀតបង្ហាញពីលក្ខណៈបច្ចេកទេស តម្រូវការ បទប្បញ្ញត្តិ និងពិធីការ។ ព័ត៌មាន។ ឧទាហរណ៍ រូបភាពទី 3 បង្ហាញថានៅក្នុងការដេញថ្លៃមួយផ្សេងទៀត ច្រើន និងធាតុត្រូវបានពិពណ៌នានៅក្នុងទំព័រមួយ ប៉ុន្តែផ្នែកផ្សេងគ្នានៃឯកសារវែងមួយ។ ទីបួន ដូចដែលវាត្រូវបានបង្ហាញរួចហើយនៅក្នុងរូបភាពទី 2 និងទី 3 មានភាពមិនស្របគ្នាយ៉ាងសំខាន់ចំពោះចំនួនព័ត៌មាន និងធាតុត្រូវបានពិពណ៌នានៅក្នុងប្រទេសតែមួយ ឬជាការពិត សូម្បីតែអង្គការដូចគ្នាក៏ដោយ។ ភាពខុសគ្នានេះត្រូវបានគេសង្កេតឃើញនៅកម្រិតផ្សេងៗគ្នាដូចជា៖ ការប្រើប្រាស់ទម្រង់រចនាសម្ព័ន្ធ (ឧទាហរណ៍ អត្ថបទឥតគិតថ្លៃទល់នឹងតារាង/បញ្ជី); ចំនួននៃព័ត៌មានដែលបានអ៊ិនកូដ (ឧទាហរណ៍ តារាងក្នុងរូបភាពទី 2 រាយជួរ 16 ជួរ (គុណលក្ខណៈ) សម្រាប់ធាតុនីមួយៗ) សូម្បីតែសម្រាប់ប្រភេទផលិតផល/សេវាកម្មដូចគ្នាក៏ដោយ។ និងអត្ថន័យនៃរចនាសម្ព័ន្ធដែលរចនាសម្ព័ន្ធត្រូវបានអនុម័ត (ឧទាហរណ៍លំដាប់និងឈ្មោះនៃជួរឈរ) ។ កម្រិតខ្ពស់នៃភាពស្មុគស្មាញ និងភាពមិនស៊ីសង្វាក់គ្នាបែបនេះអាចជាហេតុផលចម្បងមួយដែលហេតុអ្វីបានជាមានការខ្វះខាតនៃការជីកយករ៉ែអត្ថបទ និងការសិក្សា NLP ឬកម្មវិធីសម្រាប់លទ្ធកម្មថែទាំសុខភាព។


អ្នកនិពន្ធ៖
(1) Ziqi Zhang*, សាលាព័ត៌មាន, សាកលវិទ្យាល័យ Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(2) Tomas Jasaitis, Vamstar Ltd., London ([email protected]);
(3) Richard Freeman, Vamstar Ltd., London ([email protected]);
(4) Rowida Alfrjani, សាលាព័ត៌មាន, សាកលវិទ្យាល័យ Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(5) Adam Funk, សាលាព័ត៌មាន, សាកលវិទ្យាល័យ Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]) ។
ក្រដាសនេះគឺ
[1] https://ted.europa.eu/udl?uri=TED:NOTICE:437985-2019:TEXT:EN:HTML, ចូលប្រើចុងក្រោយ៖ ខែវិច្ឆិកា ឆ្នាំ 2022




