























Bağlantılar Tablosu
Alan ve Görev
İlgili Çalışmalar
3.1. Metin madenciliği ve NLP araştırmalarına genel bakış
3.2. Metin madenciliği ve NLP'nin endüstride kullanımı
4.6. XML ayrıştırma, veri birleştirme ve risk endeksleri geliştirme
Deney ve Gösterim
Tartışma
6.1. Projenin 'endüstri' odağı
6.2. Veri çeşitliliği, çok dillilik ve çoklu görev niteliği
2. Alan ve Görev
Bu çalışma, literatürde nadiren incelenen sağlık hizmeti tedarikine odaklanmaktadır. Projenin birincil amacı, her sağlık hizmeti tedarikçisi için dinamik bir 'tedarikçi risk profili' oluşturulmasına olanak tanıyan bir platform geliştirmektir. Bu tür bir profilin, potansiyel alıcıların tedarikçiyle sözleşme imzalaması için 'risklerin' farklı perspektiflerini (örneğin, belirli ürünleri tedarik etme kapasitesi, coğrafi kapsam) değerlendiren farklı 'endekslerden' oluşmasını öngörüyoruz. Bu, 'tedarikçiler bu tür ilaçları tedarik edebilir mi', 'bu ülke için ne ölçüde tedarik edebilirler' veya 'bu miktarda tedarik edebilirler mi' gibi soruların kolayca yanıtlanmasını sağlayacaktır. Bu tür sorular genellikle alıcı karar alma süreci için çok önemlidir. Ancak, mevcut tedarik süreci yanıt aramak için birden fazla uzun belgeyi manuel olarak elemeye dayanmaktadır. Bu çok fazla kaynak tüketen bir süreçtir. Anlaşılabilir bir şekilde, birincil hedefimizin bir kolaylaştırıcısı, sağlık hizmeti tedarikçilerinin geçmiş sözleşme verilerinin yapılandırılmış bir veritabanı olacaktır. Bu nedenle projenin ikincil hedefi böyle bir veritabanı geliştirmek ve onu tarihsel sağlık hizmeti tedarik verileriyle doldurmaktır. Aşağıda açıklayacağımız gibi kamu tedarik verileri büyük ölçüde erişilebilir olsa da, çıkarılması ve bağlanması gereken yapılandırılmış, yarı yapılandırılmış ve yapılandırılmamış çok dilli verilerin bir karışımı vardır. Bu nedenle, projenin çalışmalarının önemli bir kısmı, veritabanını doldurmak için kullanılabilecek bilgileri çıkarmak üzere büyük miktarda yapılandırılmamış tedarik verisini otomatik olarak işleyen metin madenciliği ve NLP çözümleri geliştirmektir. Bu makalenin amacı bu nedenle, bu metin madenciliği ve NLP yöntemlerinin gelişimini bildirmektir.
2.1. Veri kaynakları ve karmaşıklık
Proje, AB hükümetlerinin kamu alımlarıyla ilgili projelerini yayınlamak için kullandığı 'Tenders Electronic Daily' (TED) platformundan tedarik verilerini hedeflemektedir. TED, yılda 26 resmi Avrupa dilinde yaklaşık 420 milyar avro değerinde 460.000'den fazla ihale çağrısı ve sözleşme ödülü yayınlamaktadır. Her ihale, lotun en küçük sözleşme birimi olduğu birden fazla 'lota' bölünebilir. Her lot, gerekli olan birden fazla öğeyi içerebilir. Örneğin, '2019/S 180-437985'[1] ihale duyurusu, boyutları 2 ila 30'dan fazla öğe arasında değişen bir NHS (İngiltere) ihalesinden 47 lotu listeler. Bir ihale başarılı teklifler sağlarsa, ihale için bir 'sözleşme ödülü' (veya birden fazla ödül) yapılır ve TED'e kaydedilir. Aşağıda, açıklanabilirlik adına, her ihale için bir ödül olduğunu varsayıyoruz (ancak pratikte, yöntemlerimiz bir ihale için mevcut olan tüm ödüllere uygulanır). Bir ihalede sunulan lotların ve sözleşme ödüllerinin 'çoktan çoğa' ilişkisi oluşturduğuna dikkat edin. Yani, birden fazla lot tek bir varlığa verilebilir ve tek bir sözleşme ödülünde belgelenebilir; tek bir lot ayrıca birden fazla varlığa verilebilir ve birden fazla sözleşme ödülü oluşturabilir; ayrıca tek bir sözleşme ödülü bir veya birden fazla lot içerebilir.
TED'de her ihale ve buna karşılık gelen sözleşme ödülü(leri), temel bilgi öğelerini belgelendiren yapılandırılmış bir XML dosyasına sahiptir. Bunlara 'ihale XML'i' ve 'ödül XML'i diyoruz. Bir ihale XML örneği Şekil 1'de gösterilmiştir. Ödül XML'leri genellikle aynı yapıyı izler. İhale XML'leri alıcı, lotlar, lot öğeleri, sözleşme kriterleri vb. gibi bilgileri belgelendirir. Ödül XML'leri alıcıyı, lotları, her lot için ödül alan tedarikçileri, sözleşme değerini, miktarı vb. belgelendirir. Her ihale ayrıca, özellikle lotlar ve öğeler hakkında ihale hakkında daha fazla ayrıntı sağlayan bir 'ek belgeler' koleksiyonuna sahip olabilir ('ihale ekleri')


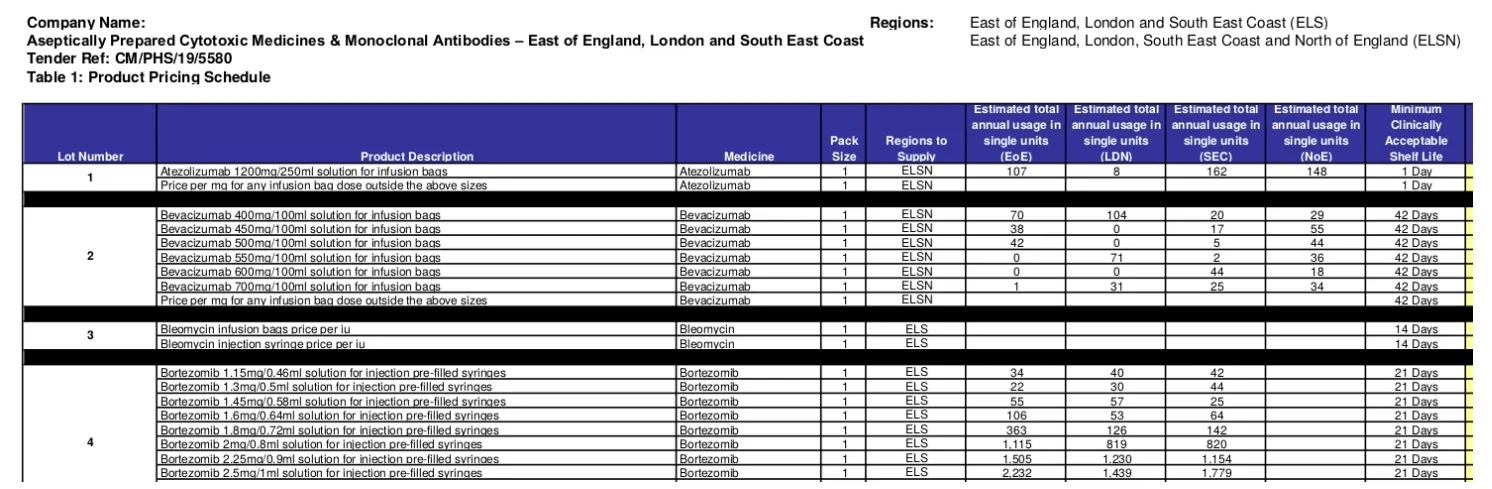
İhale ve ödül XML'lerinin kullanılabilirliği göz önüne alındığında, veritabanını geliştirme ve doldurma görevinin kolay olduğu düşünülebilir. Ancak, gerçekte veriler çok daha karmaşıktır. İlk ve en önemlisi, ihale ve ödül XML'leri genellikle eksiktir. Eksik bilgilerin çoğunluğu lot ve ürün bilgisidir. Örneğin, '2019/S 180-437985' için ihale XML'i, ihalede belirli ürünleri ayrıntılandırmadan ancak lot referans numarasını belirterek 47 lottan bahseder. Bu kritik bilgiler, 7 ihale eki (PDF) toplu olarak indirilerek edinilebilir. Hem ihale hem de ödül XML'leri daha sonra lot referanslarını kullanarak bu veri kaynaklarını çapraz referanslar. Bu tür bilgileri kurtarmak, bir tedarikçinin geçmişte tedarik ettiği ürün yelpazesini ve miktarını hesaba katması gereken tedarikçi risk profilini oluşturmak için çok önemlidir. İkincisi, her ihale eki amacımız için uygun değildir. '2019/S 180-437985' için olanlar arasında, iki PDF gerçek partileri ve kalemleri listelerken (örneğin, Şekil 2), diğerleri şartnameleri, gereksinimleri, yönetmelikleri ve protokolleri vb. belgelendirir. Üçüncüsü, ilgili bir ekteki her sayfa ilgili bilgileri içermez. Örneğin, Şekil 3 başka bir ihalede partilerin ve kalemlerin bir sayfada, ancak uzun bir belgenin farklı bölümlerinde açıklandığını göstermektedir. Dördüncüsü, Şekil 2 ve 3'te zaten gösterildiği gibi, aynı ülke veya hatta aynı kuruluş içinde parti ve kalem bilgilerinin nasıl açıklandığı konusunda önemli bir tutarsızlık vardır. Bu tutarsızlık farklı düzeylerde gözlemlenmiştir, örneğin: yapılandırılmış biçimlendirmenin kullanımı (örneğin, serbest metin ile tablolar/listeler); aynı tür ürünler/hizmetler için bile kodlanan bilgi miktarı (örneğin, Şekil 2'deki tablo her bir kalem için 16 sütun (öznitelik) listeler); ve yapıların benimsendiği yapı semantiği (örneğin, sütunların sırası ve adları). Bu kadar yüksek düzeyde karmaşıklık ve tutarsızlık, sağlık hizmetleri tedarikinde metin madenciliği ve NLP çalışmalarının veya uygulamalarının eksikliğinin başlıca nedenlerinden biri olabilir.


Yazarlar:
(1) Ziqi Zhang*, Bilgi Okulu, Sheffield Üniversitesi, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(2) Tomas Jasaitis, Vamstar Ltd., Londra ([email protected]);
(3) Richard Freeman, Vamstar Ltd., Londra ([email protected]);
(4) Rowida Alfrjani, Bilgi Okulu, Sheffield Üniversitesi, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(5) Adam Funk, Bilgi Okulu, Sheffield Üniversitesi, Regent Court, Sheffield, UKS1 4DP ([email protected]).
Bu makale
[1] https://ted.europa.eu/udl?uri=TED:NOTICE:437985-2019:TEXT:EN:HTML, son erişim: Kasım 2022








