























ຕາຕະລາງການເຊື່ອມຕໍ່
ໂດເມນ ແລະໜ້າວຽກ
ວຽກງານທີ່ກ່ຽວຂ້ອງ
3.1. ການຂຸດຄົ້ນຂໍ້ຄວາມ ແລະພາບລວມການຄົ້ນຄວ້າ NLP
3.2. ການຂຸດຄົ້ນຂໍ້ຄວາມແລະ NLP ໃນການນໍາໃຊ້ອຸດສາຫະກໍາ
4.4. ການກວດສອບລາຍການຫຼາຍ
4.6. ການວິເຄາະ XML, ການເຂົ້າຮ່ວມຂໍ້ມູນ, ແລະການພັດທະນາດັດຊະນີຄວາມສ່ຽງ
ການທົດລອງແລະການສາທິດ
ສົນທະນາ
6.1. ຈຸດສຸມ 'ອຸດສາຫະກໍາ' ຂອງໂຄງການ
6.2. ຄວາມຫຼາກຫຼາຍຂອງຂໍ້ມູນ, ລັກສະນະຫຼາຍພາສາ ແລະຫຼາຍໜ້າວຽກ
2. ໂດເມນ ແລະໜ້າວຽກ
ວຽກງານນີ້ເນັ້ນໃສ່ການຈັດຊື້ສຸຂະພາບ, ເຊິ່ງບໍ່ຄ່ອຍໄດ້ສຶກສາໃນວັນນະຄະດີ. ເປົ້າຫມາຍຕົ້ນຕໍຂອງໂຄງການແມ່ນການພັດທະນາເວທີທີ່ອະນຸຍາດໃຫ້ສ້າງແບບເຄື່ອນໄຫວຂອງ 'ໂປຣໄຟລ໌ຄວາມສ່ຽງຂອງຜູ້ສະຫນອງ' ສໍາລັບຜູ້ສະຫນອງການດູແລສຸຂະພາບແຕ່ລະຄົນ. ພວກເຮົາຄາດຄະເນຂໍ້ມູນດັ່ງກ່າວປະກອບດ້ວຍ 'ຕົວຊີ້ວັດ' ທີ່ແຕກຕ່າງກັນທີ່ປະເມີນທັດສະນະທີ່ແຕກຕ່າງກັນ (ຕົວຢ່າງ, ຄວາມສາມາດໃນການສະຫນອງຜະລິດຕະພັນບາງຢ່າງ, ການຄຸ້ມຄອງທາງພູມສາດ) ຂອງ 'ຄວາມສ່ຽງ' ສໍາລັບຜູ້ຊື້ທີ່ມີທ່າແຮງທີ່ຈະເຊັນສັນຍາກັບຜູ້ສະຫນອງ. ນີ້ຈະຊ່ວຍໃຫ້ຄໍາຖາມເຊັ່ນ: 'ໃຜເປັນຜູ້ສະຫນອງສາມາດສະຫນອງຢາຊະນິດນີ້', 'ພວກເຂົາມີຄວາມສາມາດທີ່ຈະສະຫນອງໃຫ້ແກ່ປະເທດນີ້ໃນລະດັບໃດ', ຫຼື 'ພວກເຂົາສາມາດສະຫນອງປະລິມານດັ່ງກ່າວ' ເພື່ອຕອບໄດ້ງ່າຍ. ຄໍາຖາມດັ່ງກ່າວມັກຈະສໍາຄັນສໍາລັບການຕັດສິນໃຈຂອງຜູ້ຊື້. ຢ່າງໃດກໍ່ຕາມ, ຂະບວນການຈັດຊື້ໃນປະຈຸບັນແມ່ນອີງໃສ່ການແຍກດ້ວຍຕົນເອງໂດຍຜ່ານເອກະສານທີ່ມີຄວາມຍາວຫຼາຍເພື່ອຄົ້ນຫາຄໍາຕອບ. ນີ້ແມ່ນຂະບວນການບໍລິໂພກຊັບພະຍາກອນຫຼາຍ. ເຂົ້າໃຈໄດ້, ຜູ້ເປີດໃຊ້ເປົ້າຫມາຍຕົ້ນຕໍຂອງພວກເຮົາຈະເປັນຖານຂໍ້ມູນທີ່ມີໂຄງສ້າງຂອງຂໍ້ມູນສັນຍາປະຫວັດສາດຂອງຜູ້ສະຫນອງການດູແລສຸຂະພາບ. ດັ່ງນັ້ນ, ເປົ້າຫມາຍທີສອງຂອງໂຄງການແມ່ນເພື່ອພັດທະນາຖານຂໍ້ມູນດັ່ງກ່າວແລະຕື່ມຂໍ້ມູນໃນການຈັດຊື້ດ້ານສຸຂະພາບປະຫວັດສາດ. ໃນຂະນະທີ່ຂໍ້ມູນການຈັດຊື້ສາທາລະນະແມ່ນມີຢ່າງຫຼວງຫຼາຍ, ດັ່ງທີ່ພວກເຮົາຈະອະທິບາຍຕໍ່ໄປນີ້, ມີການປະສົມຂອງຂໍ້ມູນຫຼາຍພາສາທີ່ມີໂຄງສ້າງ, ເຄິ່ງໂຄງສ້າງ, ແລະບໍ່ມີໂຄງສ້າງທີ່ຕ້ອງໄດ້ຮັບການຂຸດຄົ້ນແລະເຊື່ອມໂຍງ. ດັ່ງນັ້ນ, ສ່ວນຫນຶ່ງຂອງວຽກງານຂອງໂຄງການແມ່ນການພັດທະນາການຂຸດຄົ້ນຂໍ້ຄວາມແລະການແກ້ໄຂ NLP ທີ່ອັດຕະໂນມັດການປຸງແຕ່ງຂໍ້ມູນການຈັດຊື້ທີ່ບໍ່ມີໂຄງສ້າງໃນຈໍານວນຂະຫນາດໃຫຍ່ໂດຍອັດຕະໂນມັດກັບຂໍ້ມູນຂຸດຄົ້ນບໍ່ແຮ່ທີ່ສາມາດນໍາໃຊ້ເຂົ້າໃນຖານຂໍ້ມູນ. ເປົ້າຫມາຍຂອງບົດຄວາມນີ້ແມ່ນດັ່ງນັ້ນ, ເພື່ອລາຍງານການພັດທະນາຂອງວິທີການຂຸດຄົ້ນຂໍ້ຄວາມເຫຼົ່ານີ້ແລະ NLP.
2.1. ແຫຼ່ງຂໍ້ມູນແລະຄວາມສັບສົນ
ໂຄງການດັ່ງກ່າວໄດ້ແນໃສ່ຂໍ້ມູນການຈັດຊື້ຈາກເວທີ 'Tenders Electronic ປະຈໍາວັນ' (TED), ເຊິ່ງໄດ້ຖືກນໍາໃຊ້ໂດຍລັດຖະບານ EU ເພື່ອເຜີຍແຜ່ໂຄງການທີ່ກ່ຽວຂ້ອງກັບການຈັດຊື້ສາທາລະນະຂອງເຂົາເຈົ້າ. TED ເຜີຍແຜ່ຫຼາຍກວ່າ 460,000 ຮຽກຮ້ອງການປະມູນແລະສັນຍາລາງວັນໃນ 26 ພາສາເອີຣົບຢ່າງເປັນທາງການຕໍ່ປີ, ສໍາລັບມູນຄ່າປະມານ 420 ຕື້ເອີໂຣ. ແຕ່ລະການປະມູນອາດຈະແບ່ງອອກເປັນຫຼາຍ 'ຫຼາຍ', ເຊິ່ງຫຼາຍແມ່ນຫົວໜ່ວຍສັນຍາທີ່ນ້ອຍທີ່ສຸດ. ແຕ່ລະ lots ອາດຈະປະກອບມີຫຼາຍລາຍການທີ່ຕ້ອງການ. ເປັນຕົວຢ່າງ, ປະກາດການປະມູນ '2019/S 180-437985'[1] ລາຍຊື່ 47 lots ຈາກ NHS (UK) tender, ມີຂະຫນາດຂອງເຂົາເຈົ້າຕັ້ງແຕ່ 2 ຫາຫຼາຍກວ່າ 30 ລາຍການ. ຖ້າການປະມູນຮັບປະກັນການປະມູນທີ່ປະສົບຜົນສໍາເລັດ, 'ລາງວັນສັນຍາ' (ຫຼືຫຼາຍລາງວັນ) ຈະຖືກເຮັດແລະບັນທຶກໄວ້ໃນ TED ສໍາລັບການປະມູນ. ຕໍ່ໄປນີ້, ສໍາລັບເຫດຜົນຂອງການອະທິບາຍ, ພວກເຮົາສົມມຸດວ່າມີລາງວັນຫນຶ່ງສໍາລັບແຕ່ລະການປະມູນ (ຢ່າງໃດກໍ່ຕາມໃນການປະຕິບັດ, ວິທີການຂອງພວກເຮົາແມ່ນໃຊ້ກັບລາງວັນທັງຫມົດທີ່ມີຢູ່ສໍາລັບການປະມູນ). ຫມາຍເຫດຈໍານວນຫລາຍທີ່ສະເຫນີໃນການສະເຫນີລາຄາແລະລາງວັນສັນຍາສ້າງຄວາມສໍາພັນ 'ຫຼາຍຕໍ່ຫຼາຍ'. ຄື, ຫຼາຍ lots ສາມາດມອບໃຫ້ຫນ່ວຍງານດຽວແລະເອກະສານໃນລາງວັນສັນຍາດຽວ; ຈໍານວນດຽວຍັງສາມາດມອບໃຫ້ຫຼາຍຫນ່ວຍງານ, ປະກອບເປັນລາງວັນສັນຍາຫຼາຍ; ນອກຈາກນັ້ນ, ລາງວັນສັນຍາດຽວສາມາດປະກອບມີຫນຶ່ງຫຼືຫຼາຍ lots.
ໃນ TED, ແຕ່ລະການປະມູນແລະລາງວັນສັນຍາທີ່ສອດຄ້ອງກັນຂອງມັນມີໄຟລ໌ XML ທີ່ມີໂຄງສ້າງທີ່ບັນທຶກອົງປະກອບທີ່ສໍາຄັນຂອງຂໍ້ມູນ. ພວກເຮົາອ້າງເຖິງສິ່ງເຫຼົ່ານີ້ເປັນ 'XML ທີ່ອ່ອນໂຍນ' ແລະ 'ລາງວັນ XML'. ຕົວຢ່າງຂອງ XML ທີ່ອ່ອນໂຍນແມ່ນສະແດງຢູ່ໃນຮູບ 1. ລາງວັນ XMLs ໂດຍທົ່ວໄປແມ່ນປະຕິບັດຕາມໂຄງສ້າງດຽວກັນ. Tender XMLs ຂໍ້ມູນເອກະສານເຊັ່ນ: ຜູ້ຊື້, lots, ລາຍການຂອງ lots, ເງື່ອນໄຂຂອງສັນຍາ, ແລະອື່ນໆ ລາງວັນ XMLs ເອກະສານຜູ້ຊື້, lots, ຜູ້ສະຫນອງທີ່ໄດ້ຮັບຮາງວັນສໍາລັບແຕ່ລະ lots, ມູນຄ່າສັນຍາ, ປະລິມານ, ແລະອື່ນໆ. ການເກັບກຳ 'ເອກະສານຄັດຕິດ' ທີ່ໃຫ້ລາຍລະອຽດເພີ່ມເຕີມຂອງການປະມູນ, ໂດຍສະເພາະໃນຈຳນວນ ແລະ ລາຍການ ('ເອກະສານແນບການປະມູນ')


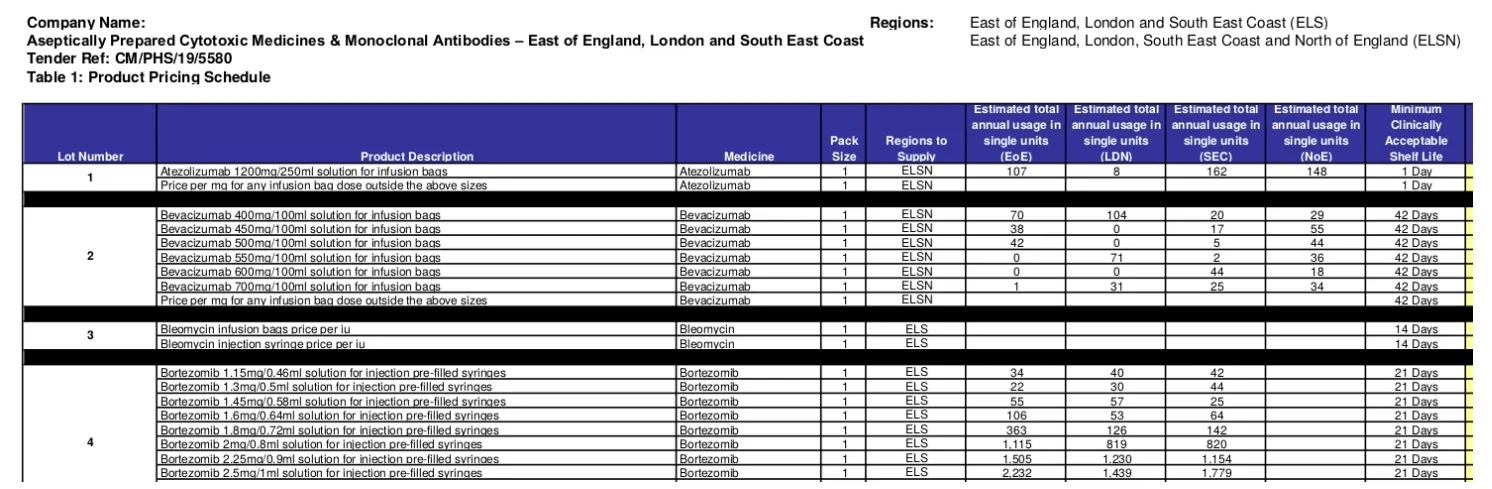
ເນື່ອງຈາກຄວາມພ້ອມຂອງ XMLs ທີ່ອ່ອນໂຍນແລະໄດ້ຮັບລາງວັນ, ຄົນເຮົາອາດຈະພິຈາລະນາວຽກງານຂອງການພັດທະນາແລະການສ້າງຖານຂໍ້ມູນທີ່ງ່າຍດາຍ. ຢ່າງໃດກໍຕາມ, ຂໍ້ມູນໃນຄວາມເປັນຈິງແມ່ນສັບສົນຫຼາຍ. ທໍາອິດແລະສໍາຄັນ, XMLs ອ່ອນໂຍນແລະລາງວັນມັກຈະບໍ່ຄົບຖ້ວນ. ຂໍ້ມູນທີ່ຂາດຫາຍໄປທີ່ເດັ່ນແມ່ນຂໍ້ມູນຫຼາຍແລະລາຍການ. ຕົວຢ່າງ, XML ອ່ອນໂຍນສໍາລັບ '2019/S 180-437985', ກ່າວເຖິງ 47 lots ໃນການປະມູນ, ໂດຍບໍ່ມີການລາຍລະອຽດຂອງລາຍການສະເພາະແຕ່ມີຈໍານວນອ້າງອີງຫຼາຍ. ຂໍ້ມູນທີ່ສໍາຄັນນີ້ແມ່ນມີຢູ່ໃນການດາວໂຫຼດເປັນຈໍານວນຫຼາຍຂອງ 7 ເອກະສານຄັດເລືອກທີ່ອ່ອນໂຍນ (PDFs). ທັງ XMLs ທີ່ອ່ອນໂຍນແລະລາງວັນຫຼັງຈາກນັ້ນການອ້າງອິງແຫຼ່ງຂໍ້ມູນເຫຼົ່ານີ້ຂ້າມຜ່ານການນໍາໃຊ້ການອ້າງອິງຈໍານວນຫລາຍ. ການຟື້ນຕົວຂໍ້ມູນດັ່ງກ່າວແມ່ນສໍາຄັນຕໍ່ການສ້າງໂປຣໄຟລ໌ຄວາມສ່ຽງຂອງຜູ້ສະຫນອງ, ເຊິ່ງຈໍາເປັນຕ້ອງຄິດໄລ່ຂອບເຂດແລະປະລິມານຂອງຜະລິດຕະພັນທີ່ຜູ້ສະຫນອງໄດ້ສະຫນອງໃນໄລຍະຜ່ານມາ. ອັນທີສອງ, ບໍ່ແມ່ນທຸກໆເອກະສານຕິດຂັດແມ່ນກ່ຽວຂ້ອງກັບຈຸດປະສົງຂອງພວກເຮົາ. ໃນບັນດາເອກະສານເຫຼົ່ານີ້ສໍາລັບ '2019/S 180-437985', ສອງ PDFs ບອກຈໍານວນແລະລາຍການຕົວຈິງ (ເຊັ່ນ: ຮູບ 2), ໃນຂະນະທີ່ອື່ນໆເອກະສານສະເພາະ, ຄວາມຕ້ອງການ, ກົດລະບຽບແລະໂປໂຕຄອນແລະອື່ນໆ. ອັນທີສາມ, ບໍ່ແມ່ນທຸກໆຫນ້າຂອງເອກະສານຄັດຕິດທີ່ກ່ຽວຂ້ອງ. ຂໍ້ມູນ. ຕົວຢ່າງ, ຮູບທີ 3 ສະແດງໃຫ້ເຫັນວ່າຢູ່ໃນການປະມູນອື່ນ, lots and items are described in one page but different sections of a long document. ອັນທີສີ່, ດັ່ງທີ່ໄດ້ສະແດງຢູ່ໃນຮູບທີ 2 ແລະ 3, ມີຄວາມແຕກຕ່າງກັນຢ່າງຫຼວງຫຼາຍໃນຈຳນວນ ແລະ ຂໍ້ມູນລາຍການທີ່ໄດ້ຖືກອະທິບາຍພາຍໃນປະເທດດຽວກັນ, ຫຼື ແທ້ຈິງແລ້ວ, ແມ່ນແຕ່ອົງການດຽວກັນ. ຄວາມແຕກຕ່າງນີ້ໄດ້ຖືກສັງເກດເຫັນໃນລະດັບຕ່າງໆເຊັ່ນ: ການໃຊ້ຮູບແບບທີ່ມີໂຄງສ້າງ (ຕົວຢ່າງ, ຂໍ້ຄວາມຟຣີທຽບກັບຕາຕະລາງ / ລາຍການ); ຈໍານວນຂໍ້ມູນທີ່ເຂົ້າລະຫັດ (ຕົວຢ່າງ: ຕາຕະລາງໃນຮູບ 2 ລາຍຊື່ 16 ຖັນ (ຄຸນລັກສະນະ) ສໍາລັບແຕ່ລະລາຍການ) ເຖິງແມ່ນວ່າສໍາລັບປະເພດດຽວກັນຂອງຜະລິດຕະພັນ / ບໍລິການ; ແລະ semantics ຂອງໂຄງສ້າງທີ່ໂຄງສ້າງໄດ້ຖືກຮັບຮອງເອົາ (ຕົວຢ່າງ, ຄໍາສັ່ງແລະຊື່ຂອງຖັນ). ລະດັບສູງຂອງຄວາມສັບສົນແລະບໍ່ສອດຄ່ອງດັ່ງກ່າວອາດຈະເປັນເຫດຜົນສໍາຄັນຫນຶ່ງທີ່ເຮັດໃຫ້ການຂາດການຂຸດຄົ້ນຂໍ້ຄວາມແລະການສຶກສາ NLP ຫຼືຄໍາຮ້ອງສະຫມັກສໍາລັບການຈັດຊື້ການດູແລສຸຂະພາບ.


ຜູ້ຂຽນ:
(1) Ziqi Zhang*, ໂຮງຮຽນຂໍ້ມູນຂ່າວສານ, ມະຫາວິທະຍາໄລ Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(2) Tomas Jasaitis, Vamstar Ltd., ລອນດອນ ([email protected]);
(3) Richard Freeman, Vamstar Ltd., ລອນດອນ ([email protected]);
(4) Rowida Alfrjani, ໂຮງຮຽນຂໍ້ມູນຂ່າວສານ, ມະຫາວິທະຍາໄລ Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(5) Adam Funk, ໂຮງຮຽນຂໍ້ມູນຂ່າວສານ, ມະຫາວິທະຍາໄລ Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]).
ເອກະສານນີ້ແມ່ນ
[1] https://ted.europa.eu/udl?uri=TED:NOTICE:437985-2019:TEXT:EN:HTML, ເຂົ້າເຖິງຫຼ້າສຸດ: ພະຈິກ 2022







