























リンク一覧
ドメインとタスク
関連研究
実験とデモンストレーション
議論
2. ドメインとタスク
この研究は、文献ではほとんど研究されていない医療調達に焦点を当てています。プロジェクトの主な目標は、各医療サプライヤーの「サプライヤーリスクプロファイル」を動的に作成できるプラットフォームを開発することです。私たちは、そのようなプロファイルが、潜在的なバイヤーがサプライヤーと契約を結ぶ際の「リスク」のさまざまな観点(特定の製品の供給能力、地理的範囲など)を評価するさまざまな「指標」で構成されることを想定しています。これにより、「この種の医薬品を供給できるサプライヤーは誰か」、「この国にどの程度供給できるか」、「そのような量を供給できるか」などの質問に簡単に答えることができます。このような質問は、バイヤーの意思決定にとってしばしば重要です。ただし、現在の調達プロセスでは、答えを見つけるために複数の長い文書を手動でふるいにかけることに依存しています。これは非常にリソースを消費するプロセスです。当然のことながら、私たちの主な目標を実現するには、医療サプライヤーの過去の契約データの構造化データベースが必要です。したがって、プロジェクトの第 2 の目標は、そのようなデータベースを開発し、過去の医療調達データを入力することです。公共調達データは、以下で説明するように、幅広く入手可能ですが、マイニングしてリンクする必要がある構造化、半構造化、非構造化の多言語データが混在しています。したがって、プロジェクトの作業の大部分は、大量の非構造化調達データを自動的に処理して、データベースの入力に使用できる情報をマイニングするテキスト マイニングおよび NLP ソリューションの開発です。したがって、この記事の目標は、これらのテキスト マイニングおよび NLP 手法の開発を報告することです。
2.1. データソースと複雑さ
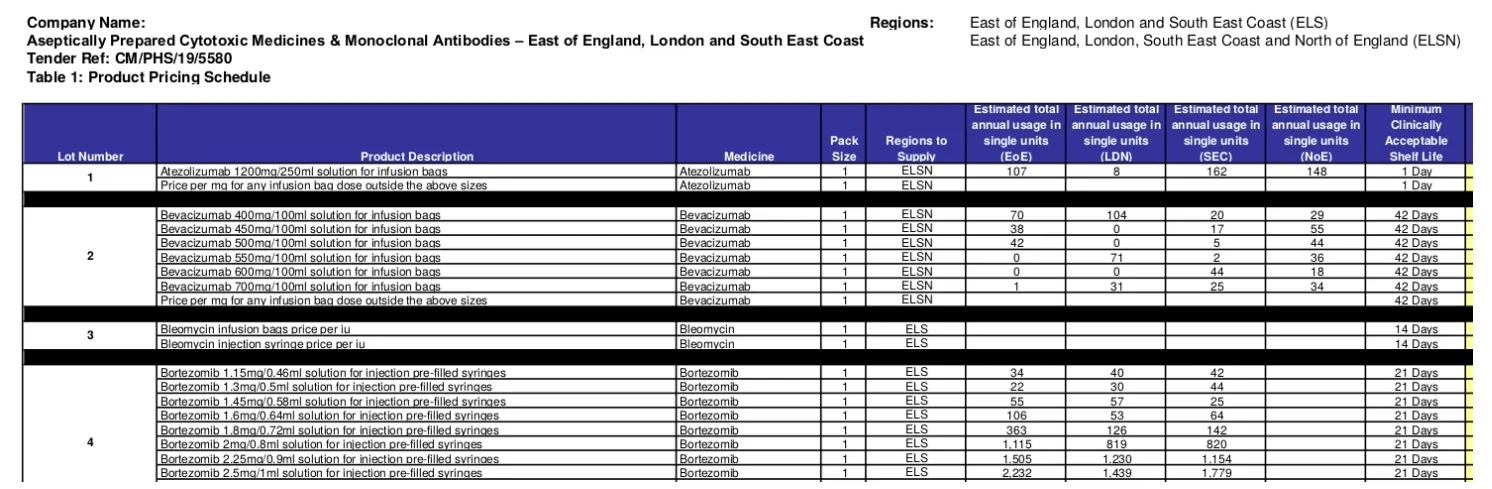
このプロジェクトは、EU諸国政府が公共調達関連プロジェクトを公開するために使用している「Tenders Electronic Daily」(TED)プラットフォームの調達データを対象としています。TEDは、年間46万件以上の入札公告と契約締結を26の欧州公用語で公開しており、その価値は約4,200億ユーロに上ります。各入札は複数の「ロット」に分割されることがあります。ロットは契約の最小単位です。各ロットには、必要な品目が複数含まれている場合があります。例えば、入札公告「2019/S 180-437985」[1]には、NHS(英国)の入札から47のロットがリストされており、そのサイズは2個から30個以上に及びます。入札が成功すると、「契約締結」(または複数の締結)が行われ、入札のTEDに記録されます。以下では、説明を容易にするために、入札ごとに 1 つの受賞があると仮定します (ただし、実際には、入札で利用可能なすべての受賞にこの方法が適用されます)。入札で提供されるロットと契約の受賞は「多対多」の関係を形成することに注意してください。つまり、複数のロットを単一のエンティティに授与し、1 つの契約の受賞として文書化できます。また、1 つのロットを複数のエンティティに授与して、複数の契約の受賞を形成することもできます。さらに、1 つの契約の受賞には、1 つまたは複数のロットを含めることができます。
TED では、入札とそれに対応する契約の授与には、情報の主要要素を文書化した構造化 XML ファイルがあります。これらを「入札 XML」と「授与 XML」と呼びます。入札 XML の例を図 1 に示します。授与 XML は一般に同じ構造に従います。入札 XML には、購入者、ロット、ロットの項目、契約基準などの情報が文書化されます。授与 XML には、購入者、ロット、各ロットの授与サプライヤー、契約額、数量などが文書化されます。入札にはそれぞれ、ロットと項目に関する入札の詳細 (「入札添付ファイル」) を提供する「添付文書」のコレクションが含まれる場合もあります。


入札および落札 XML が利用できることを考えると、データベースの開発とデータ入力のタスクは簡単だと思われるかもしれません。しかし、実際のデータははるかに複雑です。何よりもまず、入札および落札 XML は不完全な場合が多いです。主に欠落している情報は、ロットと品目の情報です。たとえば、「2019/S 180-437985」の入札 XML では、入札で 47 のロットについて言及されていますが、具体的な品目の詳細は記載されておらず、ロット参照番号のみが記載されています。この重要な情報は、7 つの入札添付ファイル (PDF) の一括ダウンロードから入手できます。入札 XML と落札 XML はどちらも、ロット参照を使用してこれらのデータ ソースを相互参照します。このような情報を回復することは、サプライヤーが過去に供給した製品の範囲と数量を考慮する必要があるサプライヤー リスク プロファイルを作成するために重要です。第 2 に、すべての入札添付ファイルが私たちの目的に関連しているわけではありません。 「2019/S 180-437985」の PDF のうち、2 つには実際のロットと品目がリストされており (例: 図 2)、その他の PDF には仕様、要件、規制、プロトコルなどが文書化されています。 3 番目に、関連する添付ファイルのすべてのページに関連情報が含まれているわけではありません。 たとえば、図 3 は、別の入札で、ロットと品目が 1 ページで説明されているが、長い文書の異なるセクションに記載されていることを示しています。 4 番目に、図 2 と図 3 ですでに示されているように、同じ国、または同じ組織内でさえ、ロットと品目情報の記述方法に大きな矛盾があります。 この矛盾は、構造化フォーマットの使用 (例: フリー テキスト vs. 表/リスト)、同じ種類の製品/サービスであってもエンコードされた情報の量 (例: 図 2 の表には、各品目に 16 の列 (属性) がリストされています)、構造が採用されている場合の構造の意味 (例: 列の順序と名前) など、さまざまなレベルで確認されています。このような高度の複雑さと不一致は、医療調達におけるテキストマイニングや NLP の研究や応用が不足している主な理由の 1 つである可能性があります。


著者:
(1)Ziqi Zhang*、シェフィールド大学情報学部、リージェントコート、シェフィールド、UKS1 4DP([email protected])
(2) Tomas Jasaitis、Vamstar Ltd.、ロンドン ([email protected])。
(3)リチャード・フリーマン、Vamstar Ltd.、ロンドン([email protected])
(4)ロウィダ・アルフリャニ、シェフィールド大学情報学部、リージェントコート、シェフィールド、UKS1 4DP([email protected])
(5)アダム・ファンク、シェフィールド大学情報学部、リージェントコート、シェフィールド、UKS1 4DP([email protected])。
この論文は
[1] https://ted.europa.eu/udl?uri=TED:NOTICE:437985-2019:TEXT:EN:HTML、最終アクセス:2022年11月








