Tabel over links
Domæne og opgave
Relateret arbejde
3.1. Tekstmining og NLP-forskningsoversigt
3.2. Tekstmining og NLP i industribrug
4.4. Detektering af partiemner
4.6. XML-parsing, datasammenføjning og udvikling af risikoindekser
Eksperiment og demonstration
Diskussion
6.1. Projektets 'industri' fokus
6.2. Data heterogenitet, flersproget og multi-task karakter
2. Domæne og opgave
Dette arbejde fokuserer på indkøb af sundhedsydelser, som sjældent er blevet undersøgt i litteraturen. Det primære mål med projektet er at udvikle en platform, der tillader dynamisk skabelse af en 'leverandørrisikoprofil' for hver sundhedsleverandør. Vi forestiller os, at en sådan profil består af forskellige 'indekser', der vurderer forskellige perspektiver (f.eks. kapacitet til at levere bestemte produkter, geografisk dækning) af 'risici' for potentielle købere til at underskrive kontrakter med leverandøren. Dette ville gøre det muligt nemt at besvare spørgsmål som "hvem er leverandørerne i stand til at levere denne form for medicin", "i hvilket omfang er de i stand til at levere til dette land" eller "er de i stand til at levere en sådan mængde". Sådanne spørgsmål er ofte afgørende for købers beslutningstagning. Den nuværende indkøbsproces er dog afhængig af, at man manuelt gennemgår flere lange dokumenter for at finde svar. Dette er en meget ressourcekrævende proces. Forståeligt nok ville en muliggører for vores primære mål være en struktureret database med sundhedsleverandørers historiske kontraktdata. Det sekundære mål med projektet er således at udvikle en sådan database og udfylde den med historiske indkøbsdata for sundhedsvæsenet. Mens offentlige indkøbsdata er meget tilgængelige, som vi skal forklare i det følgende, er der en blanding af strukturerede, semistrukturerede og ustrukturerede flersprogede data, der skal udvindes og sammenkædes. Derfor er en stor del af projektets arbejde at udvikle tekstmining- og NLP-løsninger, der automatisk behandler store mængder ustrukturerede indkøbsdata til at mine information, der kan bruges til at udfylde databasen. Målet med denne artikel er derfor at rapportere udviklingen af disse tekstmining- og NLP-metoder.
2.1. Datakilder og kompleksitet
Projektet er rettet mod indkøbsdata fra platformen 'Tenders Electronic Daily' (TED), som bruges af EU's regeringer til at offentliggøre deres offentlige indkøbsrelaterede projekter. TED udgiver over 460.000 udbud og kontrakttildelinger på 26 officielle europæiske sprog om året til en værdi af omkring 420 milliarder euro. Hvert tilbud kan opdeles i flere 'partier', hvor et parti er den mindste kontraktenhed. Hvert parti kan indeholde flere genstande, som er nødvendige. Som et eksempel viser udbudsbekendtgørelsen '2019/S 180-437985'[1] 47 partier fra et NHS (UK)-udbud med størrelser fra 2 til over 30 varer. Hvis et tilbud sikrer succesfulde bud, vil der blive foretaget en 'kontrakttildeling' (eller flere tildelinger) og registreret i TED for tilbuddet. I det følgende antager vi for forklaringens skyld, at der er én tildeling for hvert tilbud (dog anvendes vores metoder i praksis på alle tildelinger, der er tilgængelige for et udbud). Bemærk de tilbudte emner i et udbud, og kontrakttildelingerne danner et 'mange-til-mange' forhold. Der kan nemlig tildeles flere partier til en enkelt enhed og dokumenteres i én kontrakttildeling; et enkelt parti kan også tildeles flere enheder, hvilket danner flere kontrakttildelinger; desuden kan en enkelt kontrakttildeling omfatte en eller flere entrepriser.
På TED har hvert tilbud og dets tilsvarende kontrakttildeling(er) en struktureret XML-fil, der dokumenterer nøgleelementer af information. Vi omtaler disse som 'tender XML' og 'award XML'. Et eksempel på en udbuds-XML er vist i figur 1. Tildelings-XML'er følger generelt den samme struktur. Udbuds-XML'er dokumenterer oplysninger såsom køber, partierne, emner, kontraktkriterier osv. Tildelings-XML'er dokumenterer køberen, emnerne, de tildelte leverandører for hvert emne, kontraktværdi, mængde osv. Hvert tilbud kan også have en samling af "vedhæftede dokumenter", der giver yderligere detaljer om udbuddet, især om partier og genstande ("udbudsbilag")


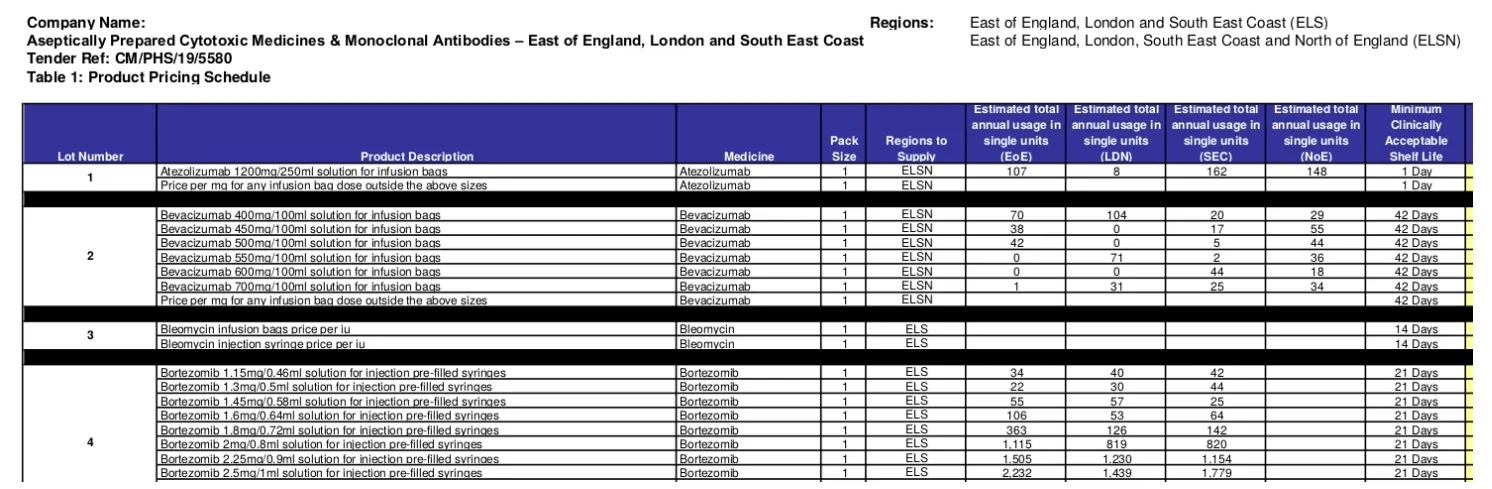
I betragtning af tilgængeligheden af udbuds- og tildelings-XML'er kan man betragte opgaven med at udvikle og udfylde databasen for at være let. Imidlertid er dataene i virkeligheden langt mere komplicerede. Først og fremmest er udbuds- og tildelings-XML'erne ofte ufuldstændige. Den overvejende manglende information er parti- og vareoplysninger. Som eksempel nævner udbuds-XML for '2019/S 180-437985' 47 partier i udbuddet, uden at specificere de konkrete punkter, men et partireferencenummer. Denne kritiske information er tilgængelig fra en massedownload af 7 udbudsvedhæftede filer (PDF'er). Både udbuds- og tildelings-XML'erne krydshenviser derefter disse datakilder ved brug af partireferencerne. Gendannelse af sådanne oplysninger er afgørende for at opbygge leverandørens risikoprofil, som skal tage højde for rækkevidden og mængden af produkter, som en leverandør tidligere har leveret. For det andet er ikke alle udbudsbilag relevante for vores mål. Blandt dem for '2019/S 180-437985' viser to PDF'er de faktiske partier og elementer (f.eks. figur 2), mens andre dokumenterer specifikationer, krav, forskrifter og protokoller osv. For det tredje er det ikke hver side i en relevant vedhæftet fil, der indeholder relevante information. For eksempel viser figur 3, at i et andet udbud er partier og emner beskrevet på én side, men forskellige afsnit af et langt dokument. For det fjerde, som det allerede er vist i figur 2 og 3, er der en betydelig uoverensstemmelse i, hvordan parti- og vareoplysninger beskrives inden for det samme land, eller endog den samme organisation. Denne uoverensstemmelse er blevet observeret på forskellige niveauer, såsom: brugen af struktureret formatering (f.eks. fri tekst vs. tabeller/lister); mængden af kodet information (f.eks. viser tabellen i figur 2 16 kolonner (attributter) for hver vare) selv for de samme slags produkter/tjenester; og strukturens semantik, hvor strukturer er vedtaget (f.eks. rækkefølgen og navnene på kolonner). Et så højt niveau af kompleksitet og inkonsekvens kan være en væsentlig årsag til, at der har været mangel på tekstmining og NLP-undersøgelser eller ansøgninger om indkøb af sundhedsydelser.


Forfattere:
(1) Ziqi Zhang*, Information School, University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(2) Tomas Jasaitis, Vamstar Ltd., London ([email protected]);
(3) Richard Freeman, Vamstar Ltd., London ([email protected]);
(4) Rowida Alfrjani, Information School, University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(5) Adam Funk, Information School, University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]).
Dette papir er
[1] https://ted.europa.eu/udl?uri=TED:NOTICE:437985-2019:TEXT:EN:HTML, sidst tilgået: nov 2022