























Táboa de ligazóns
Dominio e tarefa
Traballo relacionado
3.1. Visión xeral da investigación de minería de textos e PNL
3.2. Minería de textos e PNL no uso da industria
4.4. Detección de elementos de lote
4.6. Análise XML, unión de datos e desenvolvemento de índices de risco
Experimento e demostración
Discusión
6.1. O foco "industria" do proxecto
6.2. Heterxeneidade de datos, natureza multilingüe e multitarefa
2. Dominio e Tarefa
Este traballo céntrase na contratación sanitaria, que raramente foi estudada na literatura. O obxectivo primordial do proxecto é desenvolver unha plataforma que permita a creación dinámica dun "perfil de risco do provedor" para cada provedor sanitario. Prevemos que un perfil deste tipo consista en diferentes "índices" que avalían diferentes perspectivas (por exemplo, capacidade de subministración de determinados produtos, cobertura xeográfica) de "riscos" para que os potenciais compradores asinen contratos co provedor. Isto permitiría responder con facilidade a preguntas como "quen son os provedores capaces de subministrar este tipo de medicamentos", "en que medida son capaces de subministrar a este país" ou "son capaces de proporcionar esa cantidade"? Tales preguntas adoitan ser cruciais para a toma de decisións do comprador. Non obstante, o proceso de contratación actual depende de examinar manualmente varios documentos longos para buscar respostas. Este é un proceso que consume moito recursos. Comprensiblemente, un facilitador do noso obxectivo principal sería unha base de datos estruturada de datos históricos de contratos dos provedores sanitarios. Así, o obxectivo secundario do proxecto é desenvolver unha base de datos deste tipo e enchela con datos históricos de contratación sanitaria. Aínda que os datos de contratación pública están moi dispoñibles, como explicaremos a continuación, hai unha mestura de datos multilingües estruturados, semiestruturados e non estruturados que deben ser extraídos e vinculados. Polo tanto, unha parte importante do traballo do proxecto está a desenvolver solucións de minería de texto e NLP que procesan automaticamente grandes cantidades de datos de adquisición non estruturados para extraer información que se pode usar para encher a base de datos. O obxectivo deste artigo é, polo tanto, informar sobre o desenvolvemento destes métodos de minería de textos e PNL.
2.1. Fontes de datos e complexidade
O proxecto ten como obxectivo os datos de contratación da plataforma "Tenders Electronic Daily" (TED), que os gobernos da UE usan para publicar os seus proxectos relacionados coa contratación pública. TED publica ao ano máis de 460.000 licitacións e adxudicacións de contratos en 26 linguas oficiais europeas, por uns 420.000 millóns de euros. Cada licitación pode dividirse en varios 'lotes', sendo un lote a unidade contractual máis pequena. Cada lote pode conter varios elementos necesarios. Como exemplo, o anuncio de licitación "2019/S 180-437985"[1] enumera 47 lotes dunha licitación do NHS (Reino Unido), con tamaños que van de 2 a máis de 30 elementos. Se unha licitación obtén ofertas, farase unha "adjudicación do contrato" (ou adxudicacións múltiples) e rexistrarase no TED para a licitación. A continuación, por motivos de explicación, supoñemos que hai unha adxudicación para cada licitación (non obstante, na práctica, os nosos métodos aplícanse a todas as adxudicacións dispoñibles para unha licitación). Observe os lotes ofrecidos nun concurso e as adxudicacións do contrato forman unha relación de "moitos a moitos". É dicir, pódense adxudicar varios lotes a unha única entidade e documentarse nunha única adxudicación do contrato; tamén se pode adxudicar un só lote a varias entidades, formando múltiples adxudicacións de contratos; ademais, unha única adxudicación do contrato pode incluír un ou varios lotes.
En TED, cada licitación e as súas correspondentes adxudicacións teñen un ficheiro XML estruturado que documenta os elementos clave de información. Referímonos a estes como "XML de licitación" e "XML de adxudicación". Na Figura 1 móstrase un exemplo de XML de licitación. Os XML de adxudicación xeralmente seguen a mesma estrutura. Os XML de licitación documentan información como o comprador, os lotes, os elementos dos lotes, os criterios do contrato, etc. Os XML de adxudicación documentan o comprador, os lotes, os provedores adxudicatarios de cada lote, o valor do contrato, a cantidade, etc. Cada licitación tamén pode ter un recollida de «documentos anexos» que proporcionan máis detalles da licitación, especialmente sobre lotes e elementos («anexos do concurso»)


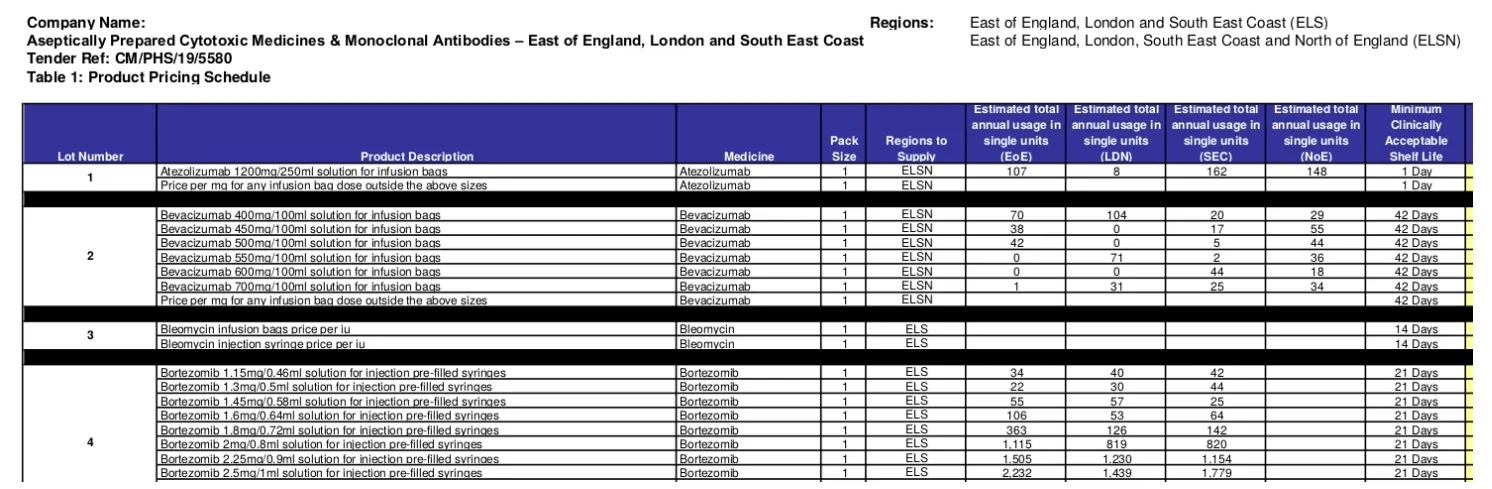
Dada a dispoñibilidade de XML de licitación e adxudicación, pódese considerar que a tarefa de desenvolver e encher a base de datos é sinxela. Non obstante, os datos en realidade son moito máis complicados. En primeiro lugar, os XML de licitación e adxudicación adoitan estar incompletos. A información que falta predominante é a información de lotes e elementos. A modo de exemplo, o XML de licitación para '2019/S 180-437985', menciona 47 lotes no prego, sen detallar os elementos específicos senón un número de referencia do lote. Esta información crítica está dispoñible a partir dunha descarga masiva de 7 anexos do concurso (PDF). A continuación, tanto os XML de licitación como de adxudicación cruzan estas fontes de datos mediante o uso das referencias do lote. A recuperación desta información é fundamental para construír o perfil de risco do provedor, que debe ter en conta a gama e a cantidade de produtos que un provedor forneceu no pasado. En segundo lugar, non todos os anexos do concurso son relevantes para o noso obxectivo. Entre os de "2019/S 180-437985", dous PDF enumeran os lotes e elementos reais (por exemplo, a Figura 2), mentres que outros documentan especificacións, requisitos, regulamentos e protocolos, etc. información. Por exemplo, a Figura 3 mostra que noutro concurso, os lotes e elementos descríbense nunha páxina pero en diferentes seccións dun documento longo. En cuarto lugar, como xa se mostra nas figuras 2 e 3, existe unha discrepancia significativa na forma en que se describe a información sobre lote e artigo dentro do mesmo país, ou incluso na mesma organización. Esta discrepancia observouse a diferentes niveis como: o uso de formato estruturado (p. ex., texto libre fronte a táboas/listas); a cantidade de información codificada (por exemplo, a táboa da Figura 2 enumera 16 columnas (atributos) para cada elemento) mesmo para os mesmos tipos de produtos/servizos; e a semántica da estrutura onde se adoptan as estruturas (por exemplo, a orde e os nomes das columnas). Un nivel tan alto de complexidade e inconsistencia podería ser unha das principais razóns polas que houbo unha falta de estudos ou aplicacións de minería de textos e PNL para a adquisición de asistencia sanitaria.


Autores:
(1) Ziqi Zhang*, Information School, University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(2) Tomas Jasaitis, Vamstar Ltd., Londres ([email protected]);
(3) Richard Freeman, Vamstar Ltd., Londres ([email protected]);
(4) Rowida Alfrjani, Information School, University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(5) Adam Funk, Information School, University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]).
Este papel é
[1] https://ted.europa.eu/udl?uri=TED:NOTICE:437985-2019:TEXT:EN:HTML, último acceso: novembro de 2022








