























Taula d'enllaços
Domini i tasca
Treball relacionat
3.1. Visió general de la recerca de la mineria de text i la PNL
3.2. Mineria de textos i PNL en ús industrial
4.4. Detecció d'elements de lot
4.6. Anàlisi XML, unió de dades i desenvolupament d'índexs de risc
Experimentació i demostració
Discussió
6.1. El focus "indústria" del projecte
6.2. Heterogeneïtat de dades, caràcter multilingüe i multitasques
2. Domini i Tasca
Aquest treball se centra en l'adquisició d'assistència sanitària, que poques vegades s'ha estudiat a la literatura. L'objectiu principal del projecte és desenvolupar una plataforma que permeti la creació dinàmica d'un "perfil de risc del proveïdor" per a cada proveïdor sanitari. Preveiem que aquest perfil constarà de diferents 'índexs' que avaluïn diferents perspectives (p. ex., capacitat de subministrament de determinats productes, cobertura geogràfica) de 'riscos' per als possibles compradors per signar contractes amb el proveïdor. Això permetria respondre fàcilment preguntes com "qui són els proveïdors capaços de subministrar aquest tipus de medicaments", "fins a quin punt són capaços de subministrar per a aquest país" o "són capaços de subministrar aquesta quantitat"? Aquestes preguntes sovint són crucials per a la presa de decisions del comprador. No obstant això, el procés de contractació actual es basa en examinar manualment diversos documents llargs per buscar respostes. Aquest és un procés que consumeix molt recursos. És comprensible que un facilitador del nostre objectiu principal seria una base de dades estructurada de dades històriques dels contractes dels proveïdors de salut. Per tant, l'objectiu secundari del projecte és desenvolupar aquesta base de dades i omplir-la amb dades històriques de contractació sanitària. Tot i que les dades de contractació pública estan àmpliament disponibles, com explicarem a continuació, hi ha una barreja de dades multilingües estructurades, semiestructurades i no estructurades que cal extreure i enllaçar. Per tant, una part important del treball del projecte està desenvolupant solucions de mineria de text i NLP que processen automàticament grans quantitats de dades de contractació no estructurades per extreure informació que es pot utilitzar per omplir la base de dades. Per tant, l'objectiu d'aquest article és informar del desenvolupament d'aquests mètodes de mineria de text i PNL.
2.1. Fonts de dades i complexitat
El projecte té com a objectiu les dades de contractació de la plataforma "Tenders Electronic Daily" (TED), que els governs de la UE utilitzen per publicar els seus projectes relacionats amb la contractació pública. TED publica anualment més de 460.000 convocatòries de licitacions i adjudicacions de contractes en 26 idiomes europees oficials, per un valor d'uns 420.000 milions d'euros. Cada licitació es pot dividir en múltiples 'lots', on un lot és la unitat contractual més petita. Cada lot pot contenir diversos elements necessaris. Com a exemple, l'avís de licitació "2019/S 180-437985"[1] enumera 47 lots d'una licitació del NHS (Regne Unit), amb les seves mides que van des de 2 fins a més de 30 articles. Si una licitació aconsegueix ofertes adjudicatàries, s'efectuarà una "adjudicació de contracte" (o adjudicacions múltiples) i es registrarà en TED per a la licitació. A continuació, per tal d'explicar-ho, suposem que hi ha una adjudicació per a cada licitació (no obstant això, a la pràctica, els nostres mètodes s'apliquen a totes les adjudicacions disponibles per a una licitació). Tingueu en compte els lots que s'ofereixen en una licitació i les adjudicacions del contracte formen una relació "molts a molts". És a dir, es poden adjudicar diversos lots a una sola entitat i documentar-se en una adjudicació de contracte; També es pot adjudicar un sol lot a múltiples entitats, formant múltiples adjudicacions de contractes; a més, una única adjudicació de contracte pot incloure un o diversos lots.
A TED, cada licitació i les adjudicacions corresponents tenen un fitxer XML estructurat que documenta els elements clau d'informació. Ens referim a aquests com "XML de licitació" i "XML d'adjudicació". A la figura 1 es mostra un exemple d'un XML d'adjudicació. Els XML d'adjudicació generalment segueixen la mateixa estructura. Els XML de licitació documenten informació com ara el comprador, els lots, els elements de lots, els criteris del contracte, etc. Els XML d'adjudicació documenten el comprador, els lots, els proveïdors adjudicats per a cada lot, el valor del contracte, la quantitat, etc. Cada licitació també pot tenir un Recollida de "documents adjunts" que proporcionen més detalls de la licitació, especialment sobre lots i elements ("arxius adjunts")


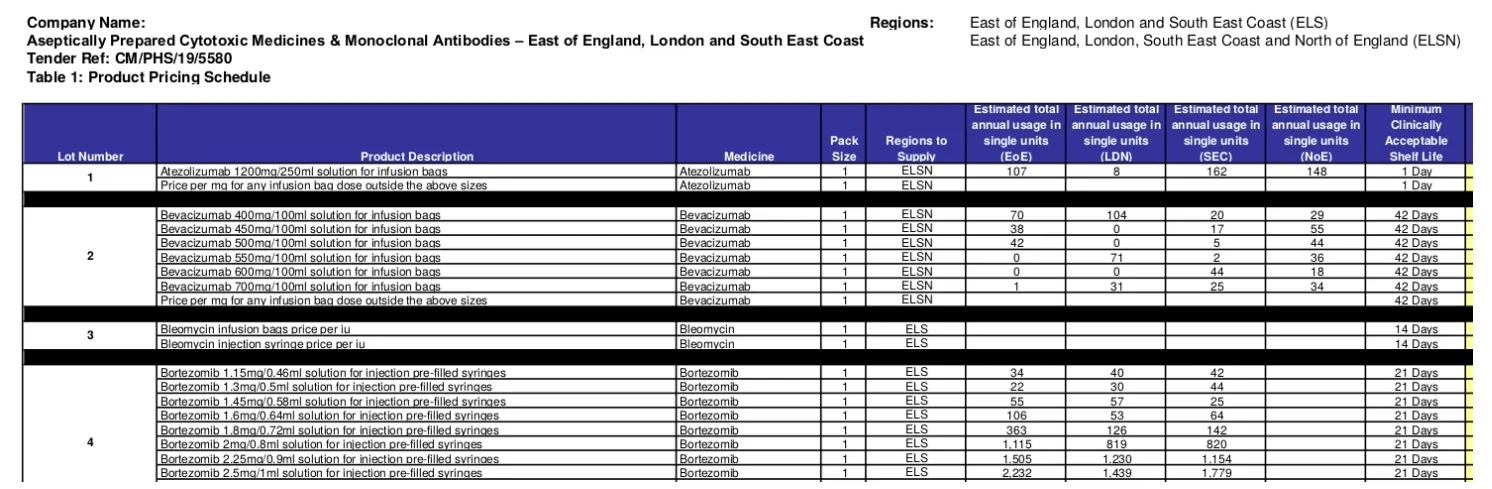
Donada la disponibilitat d'XML de licitació i adjudicació, es pot considerar fàcil la tasca de desenvolupar i emplenar la base de dades. Tanmateix, les dades en realitat són molt més complicades. En primer lloc, els XML de licitació i adjudicació sovint són incomplets. La informació que falta predominant és la informació de lots i articles. A tall d'exemple, el XML de la licitació per '2019/S 180-437985', esmenta 47 lots a la licitació, sense detallar els elements concrets però sí un número de referència de lot. Aquesta informació crítica està disponible a partir d'una descàrrega massiva de 7 fitxers adjunts (PDF). A continuació, tant els XML de la licitació com de l'adjudicació fan referència a aquestes fonts de dades mitjançant l'ús de les referències de lots. Recuperar aquesta informació és crucial per construir el perfil de risc del proveïdor, que ha de tenir en compte la gamma i la quantitat de productes que un proveïdor ha subministrat en el passat. En segon lloc, no tots els fitxers adjunts són rellevants per al nostre objectiu. Entre els de '2019/S 180-437985', dos PDF enumeren els lots i articles reals (per exemple, la figura 2), mentre que altres documenten especificacions, requisits, regulacions i protocols, etc. En tercer lloc, no totes les pàgines d'un fitxer adjunt rellevant inclouen informació. Per exemple, la figura 3 mostra que en una altra licitació, els lots i elements es descriuen en una pàgina però diferents seccions d'un document llarg. En quart lloc, com ja es mostra a les figures 2 i 3, hi ha una discrepància important en com es descriu la informació sobre lots i articles dins del mateix país, o fins i tot de la mateixa organització. Aquesta discrepància s'ha observat a diferents nivells com ara: l'ús de formats estructurats (per exemple, text lliure vs taules/llistes); la quantitat d'informació codificada (per exemple, la taula de la figura 2 enumera 16 columnes (atributs) per a cada article) fins i tot per als mateixos tipus de productes/serveis; i la semàntica de l'estructura on s'adopten les estructures (per exemple, l'ordre i els noms de les columnes). Un nivell tan alt de complexitat i inconsistència podria ser una de les principals raons per les quals hi ha hagut una manca d'estudis de mineria de text i PNL o aplicacions per a la contractació d'assistència sanitària.


Autors:
(1) Ziqi Zhang*, Escola d'Informació, Universitat de Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(2) Tomas Jasaitis, Vamstar Ltd., Londres ([email protected]);
(3) Richard Freeman, Vamstar Ltd., Londres ([email protected]);
(4) Rowida Alfrjani, Escola d'Informació, Universitat de Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(5) Adam Funk, Escola d'Informació, Universitat de Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]).
Aquest paper és
[1] https://ted.europa.eu/udl?uri=TED:NOTICE:437985-2019:TEXT:EN:HTML, últim accés: novembre de 2022








