



























I’ve tested the 7 most popular AI models to see how well they process invoices out-of-the-box, without any fine-tuning.
Read on to learn:
- Which model outperforms all others by at least 20%
- Why Google AI fails to work with structured data
- See which models handle low-resolution scans the best
Tested Models
To meet the goal of this test, I set out on a search for AI models using these criteria:
-
Popularity: Popular models have better support and documentation.
-
Invoice Processing Capability: The model needs to be able to process invoices from the get-go, without fine-tuning or training the API.
-
Integration: As the results of this test are meant to be used in practice, it’s important for each model to have API integration capabilities for easy integration.
I’ve landed on 7 AI models outlined below. I’ve given each one a nickname for convenience:
- Amazon Analyze Expense API, or “AWS”
- Azure AI Document Intelligence - Invoice Prebuilt Model, or “Azure”
- Google Document AI - Invoice Parser, or “Google”
- GPT-4o API - text input with 3rd party OCR, or “GPTt”
- GPT-4o API - image input, or “GPTi”
- Gemini 2.0 Pro Experimental, or “Gemini”
- Deepseek v3 - text input, or “Deepseek-t”
Invoice Dataset
The models were tested on a dataset of 20 invoices of various layouts and years of issue (from 2006 to 2020).
|
Invoice Year |
Number of Invoices |
|---|---|
|
2006 — 2010 |
6 |
|
2011 — 2015 |
4 |
|
2016 — 2020 |
10 |
Methodology
Analyzing each invoice, I’ve determined a list of 16 key fields that are common among all invoices and contain the most important data:
Invoice Id, Invoice Date, Net Amount, Tax Amount, Total Amount, Due Date, Purchase Order, Payment Terms, Customer Address, Customer Name, Vendor Address, Vendor Name, Item: Description, Item: Quantity, Item: Unit Price, Item: Amount.
Fields extracted by the models were mapped to a common naming convention to ensure consistency. LLM models (GPT, DeepSeek, and Gemini) were specifically asked to return the results using these common field names.
Invoice Items Detection
For each invoice, I’ve evaluated how well the models extracted key items’ fields:
Description, Quantity, Unit Price, Total Price
Efficiency Metrics
I’ve used a weighted efficiency metric (Eff, %) to assess the accuracy of extraction. This metric combines:
Strict Essential Fields: Exact matches, like invoice ID, dates, etc.
Non-Strict Essential Fields: Partial matches allowed if similarity (RLD, %) exceeds a threshold.
Invoice Items: Evaluated as correct only if all item attributes are extracted accurately.
Formulas
Overall Efficiency (Eff, %): Eff, % = (COUNTIF(strict ess. fields, positive) + COUNTIF(non-strict ess. fields, positive if RLD > RLD threshold) + COUNTIF(items, positive)) / ((COUNT(all fields) + COUNT(all items)) * 100
Item-Level Efficiency (Eff-I, %): Eff-I, % = Positive IF (ALL(Quantity, Unit Price, Amount - positive) AND RLD(Description) > RLD threshold) * 100
Invoice Recognition Results
Data Extraction Efficiency (Excluding Items)


Data Extraction Efficiency (Including Items)


Note: Google’s results are omitted from this as Google failed to extract items properly.
Top Insights
Azure isn’t the best with item descriptions.
One of the invoices in the dataset contains employee names as items. In this invoice, Azure failed to detect the full item names, recognizing only the first names, whereas other models successfully identified the complete names in all 12 items.
This issue significantly impacted Azure’s efficiency on this invoice, which was notably lower (33.3%) compared to the other models.
💡 Azure’s inability to parse multi-word descriptions in structured fields highlights a critical limitation compared to competitors.
Low resolution of invoices practically does not affect the quality of detection.
Low resolution (as perceived by the human eye) of invoices generally did not degrade detection quality. The low resolution mainly results in minor recognition mistakes, for example, in one of the invoices, Deepseek mistook a comma for a dot, leading to an incorrect numerical value.
💡 Modern OCR and AI models are robust to resolution issues, though rare formatting errors may occur.
Google fails at detecting items.
Google combines all item fields into a single string, which makes it impossible to compare the results to other models. Google recognition results:


Actual invoice:


All other services have 100% correct detection with breakdown by attributes.
💡 Google’s AI is not capable of extracting structured data without fine-tuning.
Multi-line item descriptions did not affect the quality of detection.
💡 Except for Google AI’s case above, multi-line item descriptions did not negatively impact detection quality across all models.
Gemini has the best “attention to detail.”
LLMs like GPT, Gemini, and DeepSeek can be asked to extract more data than pre-built invoice recognition models. Among all LLMs, Gemini has the best accuracy when it comes to extracting additional data from invoice items. GPT often extracted correct fields but incorrect field values, and DeepSeek performed the worst out of the 3 models with the poorest field value extraction accuracy.
Example invoice:


Gemini results:

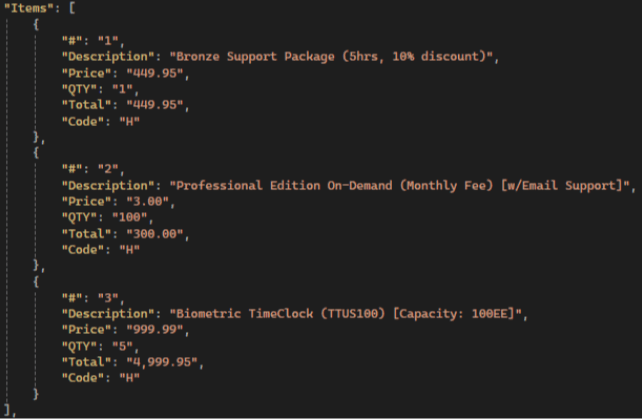
GPT results:

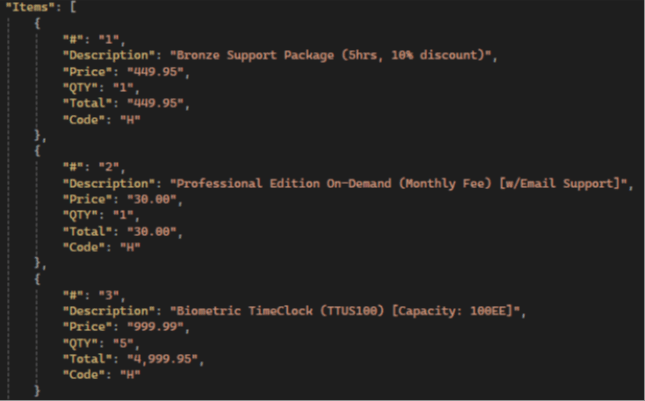
DeepSeek results:


💡 Gemini has the highest items extraction accuracy compared to other LLMs: it extracts all fields, not just the standard ones, and has the highest accuracy in preserving text and numerical values.
Comparing Costs
I’ve calculated the cost of processing 1000 invoices by each model, as well as the average cost of processing one invoice:
|
Service |
Cost |
Cost per page (average) |
|---|---|---|
|
$10 / 1000 pages (1) |
$0.01 | |
|
$10 / 1000 pages |
$0.01 | |
|
$10 / 1000 pages |
$0.01 | |
|
“GPTT”: GPT-4o API, text input with 3rd party OCR |
$2.50 / 1M input tokens, $10.00 / 1M output tokens (2) |
$0.021 |
|
$2.50 / 1M input tokens, $10.00 / 1M output tokens |
$0.0087 | |
|
$1.25, input prompts ≤ 128k tokens |
$0.0045 | |
|
$10 / 1000 pages + $0.27 / 1M input tokens, $1.10 / 1M output tokens |
$0.011 |
Notes:
(1) — $8 / 1000 pages after one million per month
(2) — Additional $10 per 1000 pages for using a text recognition model
Key Findings
🚀 Most Efficient: Gemini and GPT-4o are leading in efficiency and consistency of extraction across all invoices.
⚠️ Worst performer: Google AI is the worst out of all of the tested models when it comes to item extraction, making the overall efficiency score low. Google combines all item fields into one line, making it the worst choice for using it out of the box.
🎲 Least Reliable: DeepSeek showed frequent mistakes in text and numerical values.
Which Model Is Best For What?
✅ Gemini, AWS, or Azure for high-accuracy data extraction.
✅ GPT-4o (text input with third-party OCR) for cost-effective invoice recognition and a great “cost—efficiency” balance.
❌ Avoid Google AI if you need to extract items with high accuracy.











