























මම වඩාත්ම ජනප්රිය AI ආකෘති 7 ක් පරීක්ෂා කර ඇති අතර, ඔවුන් කොපමණ හොඳින් පෙට්ටියෙන් පිටත ගිණුම් ක්රියාත්මක කරන්නේදැයි බලන්න.
ඉගෙන ගන්න කියවන්න:
- නුඹ
- මොන මොහොතේද අනිත් හැමෝටම වඩා අවම වශයෙන් 20% කින් වැඩ කරනවා. නුඹ
- Google AI ව්යුහගත දත්ත සමඟ වැඩ නොකරන්නේ ඇයි නුඹ
- Low resolution scans වඩාත් හොඳින් කළ හැකි මොනවාද යන්න බලන්න නුඹ
පරීක්ෂා කළ ආකෘති
මෙම පරීක්ෂණයේ අරමුණු ඉටු කිරීම සඳහා, මම මෙම ප්රවේශයන් භාවිතා කරමින් AI ආකෘති සොයන්න පටන් ගත්තා:
- නුඹ
- ජනප්රියත්වය: ජනප්රිය ආකෘති වඩා හොඳ සහාය සහ ලේඛන ඇත. නුඹ
- Facture Processing Capacity: ආකෘතිය ආරම්භයේ සිට ගිණුම් ක්රියාත්මක කිරීමට හැකි විය යුතුය, API පුහුණු කිරීම හෝ පුහුණු කිරීමකින් තොරව. නුඹ
- මෙම පරීක්ෂණයේ ප්රතිඵල ප්රායෝගිකව භාවිතා කිරීමට සැලසුම් කර ඇති බැවින්, සෑම ආකෘතියකටම පහසු ඇතුළත් කිරීම සඳහා API ඇතුළත් කිරීමේ හැකියාවන් ඇති කිරීම වැදගත් වේ. නුඹ
මම පහත දැක්වෙන 7 AI ආකෘති මත ලඟා වී ඇත.මම සෑම ආකෘතියකටම පහසුකම් සඳහා නමක් දුන්නා:
- නුඹ
- Amazon Analyze Expense API, හෝ “AWS” නුඹ
- Azure AI Document Intelligence - Facture Prebuilt Model, හෝ “Azure” නුඹ
- ගූගල් ලේඛන AI - Invoice Parser, හෝ "Google" නුඹ
- GPT-4o API - තුන්වන පාර්ශව OCR, හෝ "GPTt" සමඟ teks ඇතුළත් කිරීම නුඹ
- GPT-4o API - රූප ඇතුලත් කිරීම, හෝ “GPTi” නුඹ
- Gemini 2.0 Pro Experimental, හෝ “Gemini” නුඹ
- Deepseek v3 - පෙළ ඇතුලත් කිරීම, හෝ "Deepseek-t" නුඹ
දත්ත සංකේතය
මෙම ආකෘති පරීක්ෂා කර ඇති අතර, විවිධ ප්රදර්ශන සහ ප්රදර්ශන වසර ( 2006 සිට 2020 දක්වා) ඇතුළත් 20 ගිණුම් මත පරීක්ෂා කරන ලදී.
2006 - 2010
වසර ගණන
අංක ගණන
2006 - 2010
2006 - 2010
6
6
2011 - 2015
හතර
හතර
2016 - 2020
2016 — 2020
10
10
ක් රමවේදය
සෑම ගිණුමකටම විශ්ලේෂණය කිරීමෙන්, මම සියලු ගිණුම් අතර පොදු වන 16 ප්රධාන ක්ෂේත්ර ලැයිස්තුවක් තීරණය කර ඇති අතර, වඩාත්ම වැදගත් දත්ත ඇතුළත් කර ඇත:
Invoice Id, Invoice Date, Net Amount, Tax Amount, Total Amount, Due Date, Purchase Order, Payment Terms, Customer Address, Customer Name, Vendor Address, Vendor Name, Item: Description, Item: Quantity, Item: Unit Price, Item: Amount.
LLM ආකෘති (GPT, DeepSeek, සහ Gemini) විශේෂයෙන් මෙම පොදු ක්ෂේත්ර නාම භාවිතා ප්රතිඵල ආපසු ලබා ගැනීමට ඉල්ලා ඇත.
අකුරු අකුරු හඳුනාගැනීම
සෑම ගිණුමක් සඳහාම, මම ආකෘති ප්රධාන අමුද්රව්ය ක්ෂේත්ර ආකෘති කොපමණ හොඳින් විශ්ලේෂණය කර ඇත:
Description, Quantity, Unit Price, Total Price
ඵලදායී මිනී
මම පර්යේෂණයේ නිවැරදිත්වය අගය කිරීම සඳහා බරපතල කාර්යක්ෂමතාව ප්රමාණය (Eff, %) භාවිතා කර ඇත.
දැඩි අත්යවශ්ය ක්ෂේත්ර: ගිණුම් ID, දිනය, ආදිය වැනි නිවැරදි ගැලපීම්
Non-Strict Essential Fields: අනුකූලතාවය (RLD, %) දීමනාවකට වඩා වැඩි නම් කොටසක් ගැලපෙනු ඇත.
ඇණවුම් අංග: සියලුම ඇණවුම් අංග නිවැරදිව ආකෘති කරන විට පමණක් නිවැරදිව අගය කරනු ලැබේ.
ප්රමුඛතා
සම්පූර්ණ ඵලදායීත්වය (Eff, %): Eff, % = (COUNTIF(strict ess. fields, positive) + COUNTIF(non-strict ess. fields, positive if RLD > RLD threshold) + COUNTIF(items, positive)) / ((COUNT(all fields) + COUNT(all items)) * 100
අංග මට්ටමේ ඵලදායීත්වය (Eff-I, %): Eff-I, % = ඵලදායී IF (ALL(අධිකරණය, තනි මිල, ප්රමාණය - ඵලදායී) සහ RLD (විශ්චය) > RLD අගය) * 100
පිළිගැනීමේ ප් රතිඵල
Data Extraction Efficiency (විශේෂ තොරතුරු හැර)


Data Extraction Efficiency (විශේෂය ඇතුළත්)


Note: Google ගේ ප්රතිඵල මෙහිදී ඉවත් කර ඇත, Google නිවැරදිව අමුද්රව්ය ලබා ගැනීමට නොහැකි නිසා.
Top දර්ශන
Azure ප්රතිපත්ති සමඟ හොඳම නොවේ.
One of the invoices in the dataset contains employee names as items. In this invoice, Azure failed to detect the full item names, recognizing only the first names, whereas other models successfully identified the complete names in all 12 items.
මෙම ගැටලුව එම ගිණුමේ Azure හි ඵලදායීතාවට වැදගත් බලපෑමක් ඇති අතර එය අනෙකුත් ආකෘති වලට සාපේක්ෂව අඩු විය (33.3%).
💡 Azure’s inability to parse multi-word descriptions in structured fields highlights a critical limitation compared to competitors.
සාපේක්ෂව සාපේක්ෂව අඩු විසඳුම නිරීක්ෂණය තත්ත්වයට බලපාන්නේ නැත.
අඩු resolutions (as perceived by the human eye) of invoices generally did not degrade detection quality.The low resolution mainly results in minor recognition errors, for example, in one of the invoices, Deepseek misstook a comma for a dot, leading to an incorrect numerical value.
💡 Modern OCR and AI models are robust to resolution issues, though rare formatting errors may occur.
Google අකුරු හොයාගන්නේ නැහැ.
Google ඔක්කොම ප්රතිපත්ති ක්ෂේත් රයක් එකට එකතු කරයි, ඒ නිසා අනෙකුත් ආකෘති වලට ප්රතිඵල අනුකූල කරන්න බැහැ.


සැබෑ අංකය :


අනෙකුත් සියලුම සේවාවන් 100% නිවැරදි හඳුනාගැනීම සහ ලක්ෂණ අනුව බෙදාහැරීම ඇත.
💡 Google’s AI is not capable of extracting structured data without fine-tuning.
බොහෝ රේඛා ප්රතිපත්ති නිරීක්ෂණය තත්ත්වයට බලපාන්නේ නැත.
💡 Except for Google AI’s case above, multi-line item descriptions did not negatively impact detection quality across all models.
Gemini හොඳම "සැලකිල්ලක් සඳහා අවධානය" ඇත.
GPT, Gemini, සහ DeepSeek වැනි LLMs පෙර ඉදිකිරීම් ගිණුම් හඳුනා ගැනීමේ ආකෘති වලට වඩා වැඩි දත්ත ලබා ගැනීමට ඉල්ලා සිටිය හැකිය. සියලුම LLMs අතර, Gemini ගිණුම් ලිපි වලින් අමතර දත්ත ලබා ගැනීමේදී හොඳම නිවැරදිභාවය ඇත. GPT නිතර නිවැරදි ක්ෂේත්රයක් නමුත් වැරදි ක්ෂේත්ර අගය ලබා, සහ DeepSeek 3 ආකෘති වලින් දුර්වලම ක්ෂේත්ර අගය විශ්ලේෂණය නිවැරදිභාවය සමග නරකම ක්ෂේත්රයක් ලබා දුන්නා.
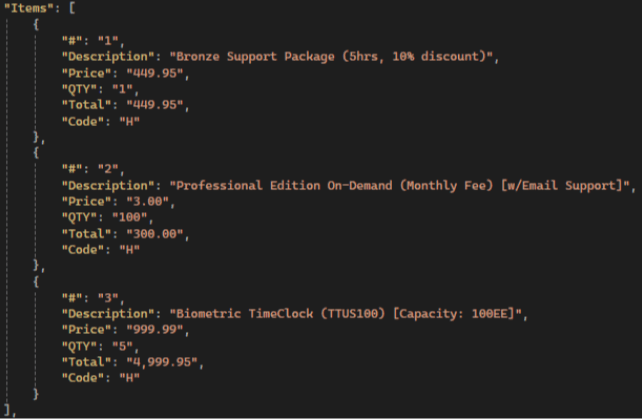
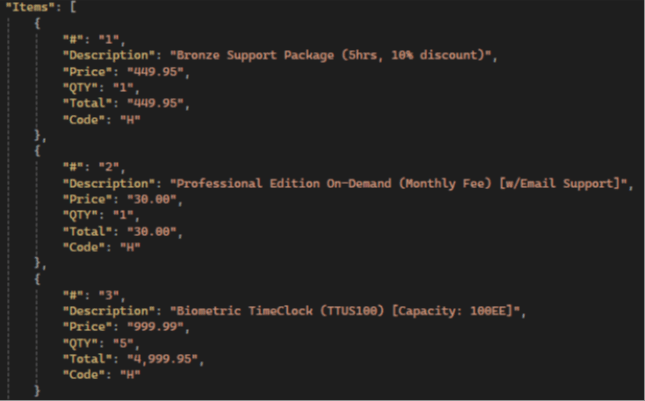
උදාහරණයක් කියවන්න:


Gemini ප්රතිඵල:

GPT ප්රතිඵල :

DeepSeek ප්රතිඵල:


💡 Gemini has the highest items extraction accuracy compared to other LLMs: it extracts all fields, not just the standard ones, and has the highest accuracy in preserving text and numerical values.
වියදම් සමාන කිරීම
මම සෑම ආකෘතියකටම 1000 ගිණුම් ක්රියාත්මක කිරීමේ වියදම, එක් ගිණුම් ක්රියාත්මක කිරීමේ සාමාන් ය වියදම ගණනය කර ඇත:
සේවා
වියදම
වියදම
පිටුපස වියදම (අධික වියදම)
පිටුපස වියදම (අධික වියදම)
$10 / 1000 පිටු (1)
ඩොලර් 0.01
Azure AI Document Intelligence
Azure AI ලේඛන බුද්ධිය$10 / 1000 පිටුව
$10 / 1000 පිටුව
ඩොලර් 0.01
Google ලේඛන AI
$10 / 1000 පිටුව
ඩොලර් 0.01
“GPTT”: GPT-4o API, තුන්වන පාර්ශවයේ OCR සහිත teks ඇතුළත් කිරීම
“GPTT”: GPT-4o API, text input with 3rd party OCR
“ගැප්ටෝ” :$2.50 / 1M ඇතුලත් ටෝකන්, $10.00 / 1M ප්රතිඵල ටෝකන් (2)
ඩොලර් 021
ඩොලර් 021
$2.50 / 1M ඇතුලත් ටෝකන්, $10.00 / 1M පිටත ටෝකන්
$2.50 / 1M ඇතුලත් ටෝකන්, $10.00 / 1M පිටත ටෝකන්
ඩොලර් 0.0087
$1.25, input prompts ≤ 128k tokens$2.50, input prompts > 128k tokens$5.00, output prompts ≤ 128k tokens$10.00, output prompts > 128k tokens
$1.25, input prompts ≤ 128k tokens$2.50, input prompts > 128k tokens$5.00, output prompts ≤ 128k tokens$10.00, output prompts > 128k tokens
ඩොලර් 0045
ඩොලර් 0045
Deepseek v3 API
$10 / 1000 පිටුව + $0.27 / 1M input tokens, $1.10 / 1M output tokens
ඩොලර් 011
Notes:
(1) — $8 / 1000 පිටුවකට මාසෙකට මිලියනයකට පසුව
(2) — භාෂා හඳුනාගැනීමේ ආකෘතිය භාවිතා කිරීම සඳහා 1000 පිටුවකට අමතර ඩොලර් 10
ප් රධාන සොයාගැනීම්
Most Efficient: Gemini සහ GPT-4o සියලු ගිණුම්වල ආකෘතිය හා අනුකූලතාවය පිළිබඳ ප්රධාන වේ.
⚠️ Worst performer: Google AI ඔක්කොම පරීක්ෂා කරන ලද ආකෘති වලින් වඩාත් නරකයි, ප්රතිලාභ ප්රතිලාභ ප්රතිලාභ අඩු කරයි.Google ඔක්කොම ප්රතිලාභ ක්ෂේත්රයක් එක් රේඛාවට එකතු කරයි, එය පෙට්ටියෙන් පිටත භාවිතා කිරීම සඳහා නරකම විකල්පය වේ.
Least Reliable: DeepSeek ප්රමාණවත් පෙළ සහ සංඛ්යාන අගය වැරදි පෙන්වා දුන්නා.
මොන මොන මොන මොන මොන මොන මොන මොන මොන මොන මොන
✅ Gemini, AWS, හෝ Azure උසස් නිවැරදි දත්ත ආකෘතිය සඳහා.
✅ GPT-4o (Third-party OCR සහිත පෙළ ඇතුළත් කිරීම) ලාභදායී ගිණුම් හඳුනාගැනීම සහ විශිෂ්ට "අධිකතා-අධිකතා" සංසන්දනය සඳහා.
🔸 Google AI වළක්වා ගැනීමට අවශ්ය නම් ඉහළ නිවැරදිතාවයකින් අමුද් රව් ය ලබා ගත යුතුය.








