























Я выпрабаваў 7 найбольш папулярных мадэляў AI, каб убачыць, як добра яны апрацоўваюць рахункі з-за кошыка, без любога тонкага намінавання.
Чытайце для таго, каб даведацца:
- І
- Якая мадэль перавышае ўсе іншыя па меншай меры на 20% І
- Чаму Google не працуе з структураванымі дадзенымі І
- Глядзіце, якія мадэлі спраўляюцца з сканамі з нізкім вырашэннем найлепш І
Выпрабаваныя мадэлі
Для таго, каб дасягнуць мэты гэтага тесту, я пачаў пошук мадэляў AI, выкарыстоўваючы гэтыя крэдыты:
- І
- Популярнасць: Популярныя мадэлі маюць лепшую падтрымку і дакументацыю. І
- Здаровая касметыка вы можаце зрабіць самі І
- Інтэграцыя: Паколькі вынікі гэтага тэсту павінны быць выкарыстаны на практыцы, важна, каб у кожнай мадэлі былі магчымасці інтэграцыі API для лёгкай інтэграцыі. І
Я прыбыў на 7 мадэляў AI, выкладзеных ніжэй. Я даў кожнаму з іх псеўданім для зручнасці:
- І
- Amazon Analyze Expense API, або «AWS» І
- Azure AI Document Intelligence — фактурная перабудаваная мадэль, або «Azure» І
- Google Docs AI — «Google» або «Invoice Parser» І
- GPT-4o API - тэкставы ўвод з 3rd party OCR, або "GPTt" І
- GPT-4o API - выява ўводу, або «GPTi» І
- Gemini 2.0 Pro Experimental, або «Gemini» І
- Deepseek v3 - тэкставы ўвод, або “Deepseek-t” І
Дадатковыя рахункі
Мадэлі былі выпрабаваныя на наборы дадзеных з 20 рахункаў розных размяшчэнняў і гадоў выдачы (з 2006 па 2020).
Год распрацоўкі
Колькасць рахункаў
Колькасць рахункаў
2006 — 2010 год
2006 — 2010 год
6
2011 — 2015 год
4
2016 — 2020
10
Методыка
Аналізуючы кожную рахунку, я вызначыў спіс 16 ключавых полей, якія з'яўляюцца агульнымі для ўсіх рахункаў і ўтрымліваюць найбольш важныя дадзеныя:
Invoice Id, Invoice Date, Net Amount, Tax Amount, Total Amount, Due Date, Purchase Order, Payment Terms, Customer Address, Customer Name, Vendor Address, Vendor Name, Item: Description, Item: Quantity, Item: Unit Price, Item: Amount.
Мадэлі LLM (GPT, DeepSeek, і Gemini) былі спецыяльна запрашаны, каб вярнуць вынікі, выкарыстоўваючы гэтыя агульныя назвы полей.
Вынікі пошуку - Detection Items
Для кожнага рахунку я ацэньваў, як добра мадэлі вылучалі полы ключавых элементаў:
Description, Quantity, Unit Price, Total Price
Эфектыўныя метрыкі
Я выкарыстоўваў ваганую метрыку эфектыўнасці (Eff, %) для ацэнкі дакладнасці экстракцыі.
Строгі асноўныя поля: Точныя адпачынкі, такія як ідэнтыфікатар рахунку, даты і г.д.
Нешматлікія асноўныя поля: Частка адпачынку дапускаецца, калі падобнасць (RLD, %) перавышае прагноз.
Усё, што вам трэба зрабіць, гэта проста адзначце файлы, і вы ўсё бяспечна.
Формулы
Агульная эфектыўнасць (Eff, %): Eff, % = (COUNTIF(строгі ess. поля, пазітыўныя) + COUNTIF(не-строгі ess. поля, пазітыўныя, калі RLD > RLD пагроза) + COUNTIF(элементы, пазітыўныя)) / ((COUNT(усе поля) + COUNT(усе элементы)) * 100
Эфектыўнасць на ўзроўні элементаў (Eff-I, %): Eff-I, % = Позитивная IF (ALL(Колькасць, адзінкавая цана, сума - пазітыўная) І RLD(Апісанне) > Прагроза RLD) * 100
Узнагароджанне рахункаў
Эфектыўнасць вывучэння дадзеных (за выключэннем элементаў)


Эфектыўнасць вывучэння дадзеных (уключаючы элементы)


Note: Вынікі Google выпушчаны з гэтага, таму што Google не атрымаў элементы правільна.
Топ Інтэрнэт
Azure не найлепшы з апісаннямі элементаў.
Дар’я адзначае, што новы фундамент мае фактуру “караед”, якой у ХІХ стагоддзі быць не магло.
Гэтая праблема значна ўплывала на эфектыўнасць Azure на гэтым рахунку, які быў значна ніжэй (33,3%) у параўнанні з іншымі мадэлямі.
💡 Azure’s inability to parse multi-word descriptions in structured fields highlights a critical limitation compared to competitors.
Нізкая выразнасць рахункаў практычна не ўплывае на якасць выяўлення.
У нашай багатай беларускай літаратуры няма другога такога твора, які па энцыклапедычнасці выяўлення ў ім нацыянальнага, так набліжаўся б да "Новай зямлі".
💡 Modern OCR and AI models are robust to resolution issues, though rare formatting errors may occur.
Google не выконвае задачы.
Google аб'ядноўвае усе полы элементаў у адзін сцяг, што робіць немагчымае параўноўванне вынікаў з іншымі мадэлямі.


Актуальныя факты:


Усе іншыя паслугі маюць 100% правільнае выяўленне з распаўсюджваннем па атрыбутах.
💡 Google’s AI is not capable of extracting structured data without fine-tuning.
Многія лініі апісання элементаў не ўплывалі на якасць выяўлення.
💡 Except for Google AI’s case above, multi-line item descriptions did not negatively impact detection quality across all models.
Дзеці маюць найлепшую «павагу да дэталяў».
LLMs, такія як GPT, Gemini, і DeepSeek могуць быць запрашаны, каб вытрымаць больш дадзеных, чым перабудаваныя мадэлі прызнання рахункаў. З усіх LLMs, Gemini мае лепшую дакладнасць, калі справа даходзіць да вытрымання дадатковых дадзеных з элементаў рахункаў. GPT часта вытрымалі правільныя полы, але няправільныя значэнні полей, і DeepSeek выконваў найгоршы з 3 мадэляў з найбольшай дакладнасцю вытрымання палявых значэнняў.
Прыкладныя факты:


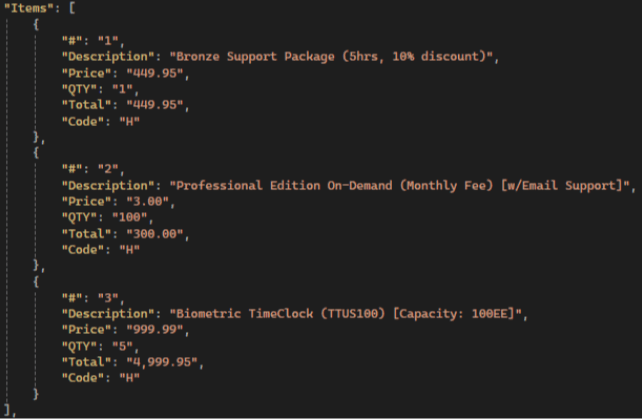
Gemini results:

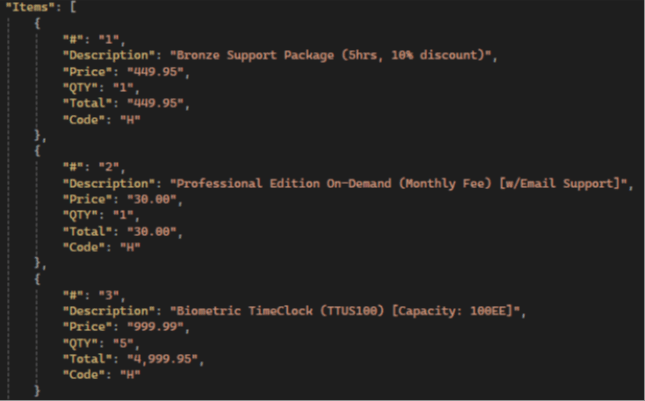
Вынікі GPT:

Вынікі DeepSeek:


💡 Gemini has the highest items extraction accuracy compared to other LLMs: it extracts all fields, not just the standard ones, and has the highest accuracy in preserving text and numerical values.
Параўнанне затрат
Я вылічыў кошт апрацоўкі 1000 рахункаў кожнай мадэлі, а таксама сярэдні кошт апрацоўкі аднаго рахунку:
Службы
Службы
Кошт
Кошт на старонку (асяроддзе)
$10 / 1000 старон (1)
$10 / 1000 старон (1)
Усяго 0.01
Усяго 0.01
Azure AI Document Intelligence
Загрузіць Azure Document Intelligence$10 / 1000 pages
Усяго 0.01
Усяго 0.01
$10 / 1000 фотаздымкаў
Усяго 0.01
Усяго 0.01
“GPTT”: GPT-4o API, text input with 3rd party OCR
«ГПТ»:$2.50 / 1M ўступныя токены, $10.00 / 1M выхадныя токены (2)
$2.50 / 1M input tokens, $10.00 / 1M output tokens (2)
$0.021
«GPTI»: толькі GPT-4o
$2.50 / 1M ўступныя токены, $10.00 / 1M выхадныя токены
З тых часоў прайшло гадоў. 0087
З тых часоў прайшло гадоў. 0087
$1,25, імпульсы ўводу ≤ 128k токены$2,50, імпульсы ўводу > 128k токены$5,00, імпульсы выхаду ≤ 128k токены$10,00, імпульсы выхаду > 128k токены
$1,25, імпульсы ўводу ≤ 128k токены$2,50, імпульсы ўводу > 128k токены$5,00, імпульсы выхаду ≤ 128k токены$10,00, імпульсы выхаду > 128k токены
0 0 45
0 0 45
0 0 0 11
$10 / 1000 старон + $0.27 / 1M ўступныя токены, $1.10 / 1M выхадныя токены
$10 / 1000 старон + $0.27 / 1M ўступныя токены, $1.10 / 1M выхадныя токены
0 0 0 11
0 0 0 11
Notes:
(1) — $8 / 1000 страниц после одного миллиона за месяц
(2) — Additional $10 per 1000 pages for using a text recognition model
Ключавыя вынікі
Most Efficient: Gemini and GPT-4o are leading in efficiency and consistency of extraction across all invoices.
️Worst performerСярод версій гульняў онлайн call of duty можна знайсці мноства займальных і дасціпных сюжэтаў, а апошняй навінкай, выпушчанай у канцы восені гэтага года, стала гульня Call of Duty: Ghost.
Least ReliableАгулам, для мяне гэта тэкст — аб’яднаны, аформлены візуальна і вербальна.
Якая мадэль лепшая для чаго?
✅ Gemini, AWS або Azure для вывучэння дадзеных высокай дакладнасці.
✅ GPT-4o (текст-інтэрв'ю з трэцяй сторонай OCR) для каштоўнага прызнання рахункаў і вялікага балансу "кошт-эфектыўнасць".
🔸 Выключайце Google AI, калі вам трэба вылучаць элементы з высокай дакладнасцю.








