























J'ai testé les 7 modèles d'IA les plus populaires pour voir à quel point ils traitent bien les factures hors de la boîte, sans aucun ajustement.
Lire pour apprendre :
- à
- Quel modèle surpasse tous les autres d’au moins 20% à
- Pourquoi l’IA de Google ne fonctionne pas avec les données structurées à
- Découvrez quels modèles traitent le mieux les scanners à faible résolution à
Modèles testés
To meet the goal of this test, I set out on a search for AI models using these criteria:
- à
- Popularité : Les modèles populaires ont un meilleur support et une meilleure documentation. à
- Capacité de traitement des factures: Le modèle doit être en mesure de traiter les factures dès le départ, sans finition ni formation de l'API. à
- Intégration : Comme les résultats de ce test sont destinés à être utilisés dans la pratique, il est important pour chaque modèle d’avoir des capacités d’intégration API pour une intégration facile. à
J'ai atterri sur 7 modèles d'IA décrits ci-dessous. J'ai donné à chacun un surnom pour la commodité:
- à
- Amazon Analyze Expense API, ou « AWS » à
- Azure AI Document Intelligence - Modèle pré-construit de facture, ou « Azure » à
- Google Documents AI - Facture Parser, ou « Google » à
- API GPT-4o - entrée de texte avec OCR de 3ème partie, ou « GPTt » à
- GPT-4o API - entrée d'image, ou « GPTi » à
- Gemini 2.0 Pro Expérimental ou « Gemini » à
- Deepseek v3 - Entrée de texte, ou « Deepseek-t » à
Invoice Dataset
Les modèles ont été testés sur un ensemble de données de 20 factures de différents modèles et années d’émission (de 2006 à 2020).
Année de facturation
Nombre de factures
2006 à 2010
6 à
2011 - 2015
2011 — 2015
4 à
2016 - 2020
10
10 à
Méthodologie
En analysant chaque facture, j'ai déterminé une liste de 16 champs clés qui sont communs parmi toutes les factures et contiennent les données les plus importantes:
Invoice Id, Invoice Date, Net Amount, Tax Amount, Total Amount, Due Date, Purchase Order, Payment Terms, Customer Address, Customer Name, Vendor Address, Vendor Name, Item: Description, Item: Quantity, Item: Unit Price, Item: Amount.
Fields extracted by the models were mapped to a common naming convention to ensure consistency. LLM models (GPT, DeepSeek, and Gemini) were specifically asked to return the results using these common field names.
Détection d’objets
Pour chaque facture, j’ai évalué à quel point les modèles ont extrait les champs des éléments clés :
Description, Quantity, Unit Price, Total Price
Métriques d’efficacité
J'ai utilisé une métrique d'efficacité pondérée (Eff, %) pour évaluer la précision de l'extraction.
Champs essentiels stricts : correspondances exactes, telles que ID de facture, dates, etc.
Champs essentiels non stricts : les matchs partiels sont autorisés si la similitude (RLD, %) dépasse un seuil.
Éléments de facture : Évalué comme correct uniquement si tous les attributs de l'élément sont extraits avec précision.
Les formules
Efficacité globale (Eff, %): Eff, % = (COUNTIF(champs d'essence stricts, positifs) + COUNTIF(champs d'essence non stricts, positifs si RLD > seuil RLD) + COUNTIF(articles, positifs)) / ((COUNT(tous les champs) + COUNT(tous les éléments)) * 100
Efficacité au niveau des éléments (Eff-I, %): Eff-I, % = SI positif (ALL(Quantité, prix unitaire, montant - positif) ET RLD(Description) > seuil RLD) * 100
Résultats de la reconnaissance
Efficacité de l'extraction de données (à l'exclusion des éléments)


Data Extraction Efficiency (Including Items)


NoteLes résultats de Google sont omis car Google n'a pas réussi à extraire correctement les éléments.
Top insights
Azure n’est pas le meilleur avec les descriptions d’éléments.
Dans cette facture, Azure n'a pas pu détecter les noms complets des éléments, ne reconnaissant que les premiers noms, alors que d'autres modèles ont réussi à identifier les noms complets dans les 12 éléments.
Ce problème a eu un impact significatif sur l’efficacité d’Azure sur cette facture, qui était nettement inférieure (33,3%) par rapport aux autres modèles.
💡 Azure’s inability to parse multi-word descriptions in structured fields highlights a critical limitation compared to competitors.
La faible résolution des factures n'affecte pratiquement pas la qualité de la détection.
La faible résolution (comme perçue par l'œil humain) des factures n'a généralement pas dégradé la qualité de la détection.La faible résolution entraîne principalement des erreurs mineures de reconnaissance, par exemple, dans l'une des factures, Deepseek a confondu un comma pour un point, conduisant à une valeur numérique incorrecte.
💡 Modern OCR and AI models are robust to resolution issues, though rare formatting errors may occur.
Google ne détecte pas les objets.
Google combine tous les champs d'éléments en une seule chaîne, ce qui rend impossible de comparer les résultats avec d'autres modèles.


La facture actuelle :


Tous les autres services ont une détection 100% correcte avec décomposition par attributs.
💡 Google’s AI is not capable of extracting structured data without fine-tuning.
Les descriptions d'éléments en plusieurs lignes n'ont pas affecté la qualité de la détection.
💡 Except for Google AI’s case above, multi-line item descriptions did not negatively impact detection quality across all models.
Gemini a le meilleur « attention aux détails ».
Les LLM tels que GPT, Gemini et DeepSeek peuvent être invités à extraire plus de données que les modèles de reconnaissance de facture pré-construits. Parmi tous les LLM, Gemini a la meilleure précision lorsqu'il s'agit d'extraire des données supplémentaires des éléments de facture.
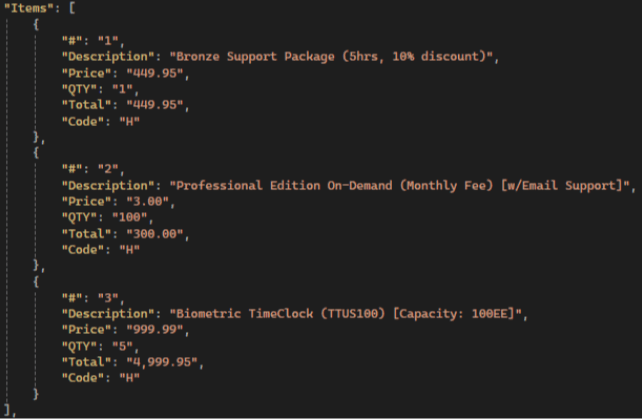
Exemple de facture :


Gemini results:

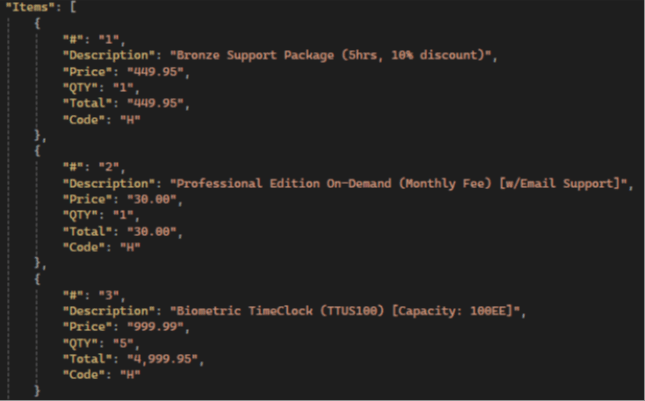
Résultats du GPT :

Résultats de DeepSeek :


💡 Gemini has the highest items extraction accuracy compared to other LLMs: it extracts all fields, not just the standard ones, and has the highest accuracy in preserving text and numerical values.
Comparer les coûts
J’ai calculé le coût du traitement de 1000 factures par modèle, ainsi que le coût moyen du traitement d’une facture :
service
service
coûts
Coût par page (moyenne)
10 € / 1000 pages (1)
10 € / 1000 pages (1)
à 0,01
Azure AI Document Intelligence
Azure intelligence des documents10 € / 1000 pages
à 0,01
à 0,01
$10 / 1000 pages
10 € / 1000 pages
à 0,01
« GPTT » : GPT-4o API, text input with 3rd party OCR
“GPTT”: GPT-4o API, text input with 3rd party OCR
“GPTT”: GPT-4o API, text input with 3rd party OCR
« GPTT » :$2.50 / 1M jetons d'entrée, $10.00 / 1M jetons de sortie (2)
$2.50 / 1M input tokens, $10.00 / 1M output tokens (2)
à partir de 021
à partir de 021
$2.50 / 1M jetons d'entrée, $10.00 / 1M jetons de sortie
$2.50 / 1M jetons d'entrée, $10.00 / 1M jetons de sortie
à 0,0087
Télécharger Gemini 2.0 Pro
1,25 $, prompts d'entrée ≤ 128k jetons
2,50 $, prompts d'entrée > 128k jetons
5,00 $, prompts de sortie ≤ 128k jetons
$10.00, prompts de sortie > 128k jetons
à 0,0045
à 0,0045
Télécharger Deepseek v3 API
$10 / 1000 pages + $0.27 / 1M jetons d'entrée, $1.10 / 1M jetons de sortie
$10 / 1000 pages + $0.27 / 1M input tokens, $1.10 / 1M output tokens
à 011
à 011
Notes:
(1) — $8 / 1000 pages after one million per month
(2) — 10 $ supplémentaires par 1000 pages pour l’utilisation d’un modèle de reconnaissance de texte
Key Findings
Most EfficientGemini et GPT-4o sont à la pointe de l'efficacité et de la cohérence de l'extraction sur toutes les factures.
️Worst performer: Google AI is the worst out of all of the tested models when it comes to item extraction, making the overall efficiency score low. Google combines all item fields into one line, making it the worst choice for using it out of the box.
🎲 Least ReliableDeepSeek a montré des erreurs fréquentes dans les valeurs textuelles et numériques.
Quel modèle est le meilleur pour quoi ?
✅ Gemini, AWS ou Azure pour une extraction de données de haute précision.
✅ GPT-4o (entrée de texte avec OCR tiers) pour une reconnaissance des factures rentable et un excellent équilibre « coût-efficacité ».
Évitez Google AI si vous avez besoin d’extraire des éléments avec une précision élevée.








