























He probado los 7 modelos de IA más populares para ver cuán bien procesan las facturas fuera de la caja, sin ningún ajuste.
Leer para aprender:
- y
- ¿Qué modelo supera a todos los demás en al menos un 20%? y
- Por qué Google no trabaja con datos estructurados y
- Ver cuáles modelos manejan mejor los escáneres de baja resolución y
Modelos probados
Para cumplir con el objetivo de esta prueba, comencé una búsqueda de modelos de IA utilizando estos criterios:
- y
- Popularidad: Los modelos populares tienen un mejor soporte y documentación. y
- Capacidad de procesamiento de facturas: El modelo debe ser capaz de procesar las facturas desde el comienzo, sin ajustar o entrenar la API. y
- Integración: Como los resultados de esta prueba están destinados a ser utilizados en la práctica, es importante que cada modelo tenga capacidades de integración de API para una fácil integración. y
He aterrizado en los 7 modelos de IA que se describen a continuación. he dado a cada uno un apodo por conveniencia:
- y
- Amazon Analytics Expense API, o “AWS” y
- Azure AI Document Intelligence – Modelo Preconstruido de Factura, o “Azure” y
- Google Documents AI – Parser de facturas, o “Google” y
- GPT-4o API - entrada de texto con OCR de terceros, o “GPTt” y
- GPT-4o API - entrada de imagen, o “GPTi” y
- Gemini 2.0 Pro Experimental, o “Gemini” y
- Deepseek v3 - entrada de texto, o “Deepseek-t” y
Contenido de datos
Los modelos fueron probados en un conjunto de datos de 20 facturas de diversos diseños y años de emisión (de 2006 a 2020).
Año de la factura
Número de facturas
2006 - 2010
6 de
6 de
2011 - 2015
4 de
4 de
2016 - 2020
2016 - 2020
10o
Metodología
Analizando cada factura, he determinado una lista de 16 campos clave que son comunes entre todas las facturas y contienen los datos más importantes:
Invoice Id, Invoice Date, Net Amount, Tax Amount, Total Amount, Due Date, Purchase Order, Payment Terms, Customer Address, Customer Name, Vendor Address, Vendor Name, Item: Description, Item: Quantity, Item: Unit Price, Item: Amount.
Los campos extraídos por los modelos fueron mapeados a una convención de nombramiento común para asegurar la coherencia. los modelos LLM (GPT, DeepSeek y Gemini) se pidieron específicamente para devolver los resultados usando estos nombres de campo comunes.
Detección de elementos
Para cada factura, he evaluado lo bien que los modelos extrajeron los campos de elementos clave:
Description, Quantity, Unit Price, Total Price
Metrología de la eficiencia
He utilizado una métrica de eficiencia ponderada (Eff, %) para evaluar la precisión de la extracción.
Campos esenciales estrictos: coincidencias exactas, como ID de factura, fechas, etc.
Campos esenciales no estrictos: Se permiten encuentros parciales si la similitud (RLD, %) excede un umbral.
Elementos de factura: Se evalúa como correcto solo si todos los atributos de los elementos se extraen con precisión.
fórmulas
Eficiencia general (Eff, %): Eff, % = (COUNTIF(campos de ess, positivos) + COUNTIF(campos de ess, positivos si RLD > umbral de RLD) + COUNTIF(elementos, positivos)) / ((COUNT(todos los campos) + COUNT(todos los elementos)) * 100
Eficiencia de nivel de elemento (Eff-I, %): Eff-I, % = positivo SI (ALL(Cantidad, Precio de unidad, Cantidad - positivo) Y RLD(Descripción) > umbral de RLD) * 100
Resultados del reconocimiento de facturas
Eficiencia de extracción de datos (excluyendo elementos)


Eficiencia de extracción de datos (incluyendo elementos)


NoteLos resultados de Google se omiten de esto ya que Google no pudo extraer los elementos correctamente.
Top Insights
Azure no es el mejor con las descripciones de elementos.
En esta factura, Azure no pudo detectar los nombres completos, reconociendo sólo los primeros nombres, mientras que otros modelos identificaron con éxito los nombres completos en todos los 12 elementos.
Este problema afectó significativamente la eficiencia de Azure en esta factura, que fue notablemente menor (33,3%) en comparación con los otros modelos.
💡 Azure’s inability to parse multi-word descriptions in structured fields highlights a critical limitation compared to competitors.
La baja resolución de las facturas prácticamente no afecta a la calidad de la detección.
La baja resolución (como lo percibe el ojo humano) de las facturas en general no degradó la calidad de detección. La baja resolución principalmente resulta en errores de reconocimiento menores, por ejemplo, en una de las facturas, Deepseek confundió una coma por un punto, lo que llevó a un valor numérico incorrecto.
💡 Modern OCR and AI models are robust to resolution issues, though rare formatting errors may occur.
Google no puede detectar objetos.
Google combina todos los campos de elementos en una sola cadena, lo que hace imposible comparar los resultados con otros modelos.


La factura actual:


Todos los demás servicios tienen detección 100% correcta con descomposición por atributos.
💡 Google’s AI is not capable of extracting structured data without fine-tuning.
Las descripciones de elementos en varias líneas no afectaron a la calidad de la detección.
💡 Except for Google AI’s case above, multi-line item descriptions did not negatively impact detection quality across all models.
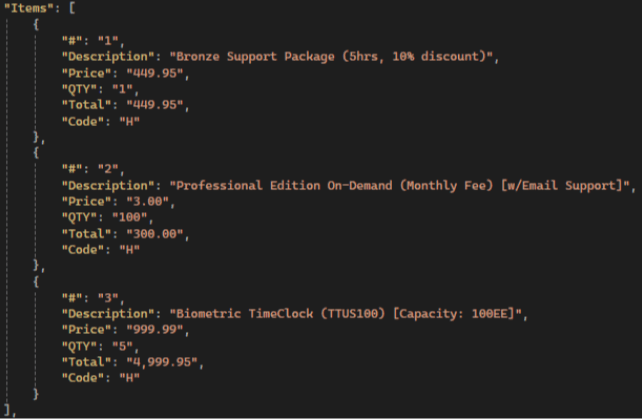
Gemini tiene la mejor “atención al detalle”.
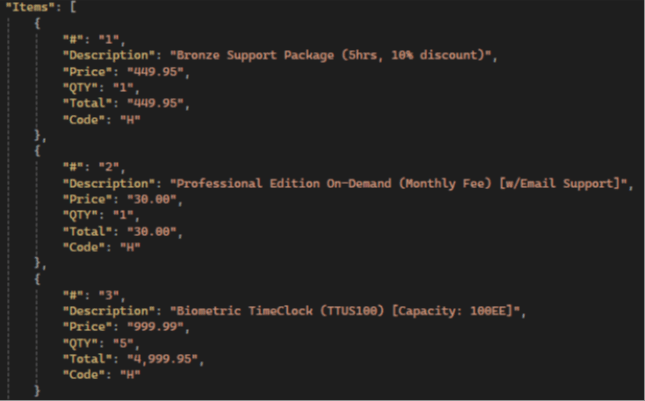
Los LLM como GPT, Gemini y DeepSeek se pueden pedir para extraer más datos que los modelos de reconocimiento de factura pre-construidos. Entre todos los LLM, Gemini tiene la mejor precisión cuando se trata de extraer datos adicionales de los artículos de factura. GPT a menudo extrajo campos correctos pero valores de campo incorrectos, y DeepSeek realizó el peor de los 3 modelos con la precisión de extracción de valor de campo más pobre.
Ejemplo de factura:


Resultados de Gemini:

Resultados del GPT:

Resultados de DeepSeek:


💡 Gemini has the highest items extraction accuracy compared to other LLMs: it extracts all fields, not just the standard ones, and has the highest accuracy in preserving text and numerical values.
Comparación de costos
He calculado el coste de procesar 1000 facturas por cada modelo, así como el coste medio de procesar una factura:
Servicio
Servicio
costos
Coste por página (medio)
Coste por página (medio)
AWS
$10 / 1000 páginas (1)
$10 / 1000 páginas (1)
Dólar 0.01
Dólar 0.01
Azure AI Document Intelligence
Introducción a la inteligencia de documentos de Azure$10 / 1000 páginas
Dólar 0.01
$10 / 1000 páginas
$10 / 1000 páginas
Dólar 0.01
“GPTT”: API GPT-4o, entrada de texto con OCR de terceros
“GPTT”: GPT-4o API, text input with 3rd party OCR
En el “GPTT”:Token de entrada de $2.50 / 1M, Token de salida de $10.00 / 1M (2)
0 021
0 021
Token de entrada de $2.50 / 1M, Token de salida de $10.00 / 1M
Token de entrada de $2.50 / 1M, Token de salida de $10.00 / 1M
0,0087 dólares
0,0087 dólares
$1.25, prompts de entrada ≤ 128k tokens$2.50, prompts de entrada > 128k tokens$5.00, prompts de salida ≤ 128k tokens$10.00, prompts de salida > 128k tokens
Dólar 0045
$10 / 1000 páginas + $0.27 / 1M tokens de entrada, $1.10 / 1M tokens de salida
$10 / 1000 páginas + $0.27 / 1M tokens de entrada, $1.10 / 1M tokens de salida
0 011
Notes:
(1) — $8 / 1000 páginas después de un millón por mes
(2) — 10 dólares adicionales por 1000 páginas por el uso de un modelo de reconocimiento de texto
Los principales hallazgos
Most EfficientGemini y GPT-4o son líderes en eficiencia y consistencia de la extracción en todas las facturas.
☀️Worst performerGoogle AI es el peor de todos los modelos probados cuando se trata de extracción de artículos, haciendo que la puntuación general de eficiencia sea baja.
Least ReliableDeepSeek mostró errores frecuentes en los valores de texto y numéricos.
¿Qué modelo es mejor para qué?
Gemini, AWS o Azure para la extracción de datos de alta precisión.
✅ GPT-4o (entrada de texto con OCR de terceros) para el reconocimiento de facturas rentable y un gran equilibrio "coste-eficiencia".
Evite Google AI si necesita extraer elementos con alta precisión.








