























Probei os 7 modelos de IA máis populares para ver o ben que procesan as facturas fóra da caixa, sen ningún axuste.
Ler para aprender:
- que
- Que modelo supera a todos os outros polo menos un 20% que
- Por que a AI de Google non traballa con datos estruturados que
- Ver que modelos manexan os escáneres de baixa resolución mellor que
Modelos probados
Para cumprir o obxectivo desta proba, comecei a buscar modelos de IA usando estes criterios:
- Popularidade: Os modelos populares teñen mellor soporte e documentación. que
- Capacidade de procesamento de facturas: O modelo debe ser capaz de procesar facturas desde o comezo, sen axustar ou adestrar a API. que
- Integración: Como os resultados desta proba están destinados a ser usados na práctica, é importante que cada modelo teña capacidades de integración de API para a súa fácil integración. que
Cheguei a 7 modelos de IA descritos a continuación. dei a cada un un un alcume para a súa conveniencia:
- que
- Amazon Analyze Expense API, ou “AWS” que
- Azure AI Document Intelligence - Modelo preconstruído de facturación, ou "Azure" que
- Google Document AI - Factura Parser, ou "Google" que
- GPT-4o API - entrada de texto con OCR de terceiros, ou "GPTt" que
- GPT-4o API - entrada de imaxe, ou "GPTi" que
- Gemini 2.0 Pro Experimental, ou “Gemini”
- Deepseek v3 - entrada de texto, ou "Deepseek-t" que
Xestión de datos
Os modelos foron probados nun conxunto de datos de 20 facturas de diferentes deseños e anos de emisión (de 2006 a 2020).
Ano da factura
Número de facturas
2006 - 2010
2006 - 2010
6 Páxina
2011 - 2015
4o
4o
2016 - 2020
10
10o
Metodoloxía
Analizando cada factura, determinei unha lista de 16 campos clave que son comúns entre todas as facturas e conteñen os datos máis importantes:
Invoice Id, Invoice Date, Net Amount, Tax Amount, Total Amount, Due Date, Purchase Order, Payment Terms, Customer Address, Customer Name, Vendor Address, Vendor Name, Item: Description, Item: Quantity, Item: Unit Price, Item: Amount.
Fields extracted by the models were mapped to a common naming convention to ensure consistency. LLM models (GPT, DeepSeek, and Gemini) were specifically asked to return the results using these common field names.
Detección de obxectos
Para cada factura, avaliou o ben que os modelos extraeron os campos de elementos clave:
Description, Quantity, Unit Price, Total Price
Metroloxía de eficiencia
Utilicei unha métrica de eficiencia ponderada (Eff, %) para avaliar a precisión da extracción.
Campos esenciais estritos: correspondencias exactas, como ID de factura, datas, etc.
Campos esenciais non estritos: Os encontros parciais son permitidos se a similitude (RLD, %) supera un limiar.
Elementos de factura: Avaliación como correcta só se todos os atributos do elemento son extraídos con precisión.
fórmulas
Eficiencia total (Eff, %): Eff, % = (COUNTIF(campos esenciais, positivos) + COUNTIF(campos esenciais, positivos se RLD > limiar RLD) + COUNTIF(elementos, positivos)) / ((COUNT(todos os campos) + COUNT(todos os elementos)) * 100
Eficiencia de nivel de elemento (Eff-I, %): Eff-I, % = positivo se (ALL(Cantidade, Prezo por unidade, Cantidade - positivo) E RLD (Descrición) > limiar RLD) * 100
Resultados do recoñecemento da factura
Eficiencia de extracción de datos (excluíndo elementos)


Eficiencia de extracción de datos (incluíndo elementos)


NoteOs resultados de Google son omitidos porque Google non puido extraer elementos correctamente.
Top Insights
Azure non é o mellor con descricións de elementos.
Nesta factura, Azure non detectou os nomes de elementos completos, recoñecendo só os primeiros nomes, mentres que outros modelos identificaron con éxito os nomes completos en todos os 12 elementos.
Este problema afectou significativamente á eficiencia de Azure nesta factura, que foi notablemente menor (33,3%) en comparación cos outros modelos.
💡 Azure’s inability to parse multi-word descriptions in structured fields highlights a critical limitation compared to competitors.
A baixa resolución das facturas practicamente non afecta á calidade da detección.
A baixa resolución (como se percibe polo ollo humano) das facturas xeralmente non degradou a calidade de detección. A baixa resolución resulta principalmente en erros de recoñecemento menores, por exemplo, nunha das facturas, Deepseek confundiu un comma por un punto, levando a un valor numérico incorrecto.
💡 Modern OCR and AI models are robust to resolution issues, though rare formatting errors may occur.
Google non é capaz de detectar elementos.
Google combina todos os campos de elementos nunha soa cadea, o que fai imposible comparar os resultados con outros modelos.


Facturación actual:


Todos os outros servizos teñen detección 100% correcta con descomposición por atributos.
💡 Google’s AI is not capable of extracting structured data without fine-tuning.
As descricións de elementos en varias liñas non afectaron á calidade da detección.
💡 Except for Google AI’s case above, multi-line item descriptions did not negatively impact detection quality across all models.
Gemini ten a mellor "atención ao detalle".
LLMs como GPT, Gemini e DeepSeek poden ser solicitados para extraer máis datos que modelos de recoñecemento de factura pre-construídos. Entre todos os LLMs, Gemini ten a mellor precisión cando se trata de extraer datos adicionais dos elementos de factura. GPT moitas veces extraeu campos correctos pero valores de campo incorrectos, e DeepSeek realizou o peor dos 3 modelos coa precisión de extracción de valor de campo máis pobre.
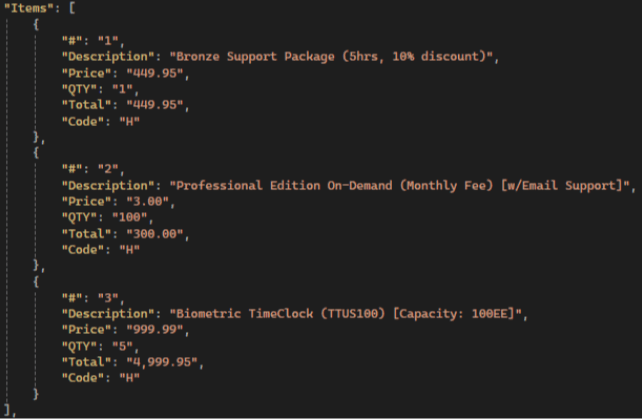
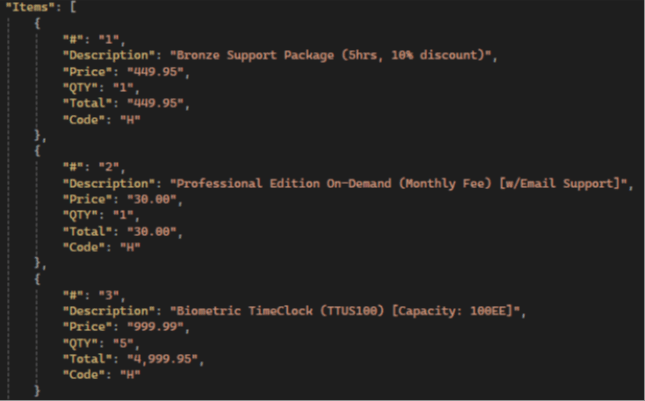
Exemplo da factura:


Resultados de Gemini:

Resultados do GPT:

Resultados de DeepSeek:


💡 Gemini has the highest items extraction accuracy compared to other LLMs: it extracts all fields, not just the standard ones, and has the highest accuracy in preserving text and numerical values.
Comparación de custos
I’ve calculated the cost of processing 1000 invoices by each model, as well as the average cost of processing one invoice:
Servizos
Custo
Custo
Custo por páxina (media)
$10 / 1000 páxinas (1)
0.01 millóns
Azure AI Document Intelligence
Intelixencia de documentos de Azure$10 / 1000 páxinas
0.01 millóns
0.01 millóns
$10 / 1000 páxinas
0.01 millóns
“GPTT”: GPT-4o API, text input with 3rd party OCR
“ gpts ” :$2.50 / tokens de entrada de 1M, $10.00 / tokens de saída de 1M (2)
0 021
$2.50 / tokens de entrada de 1M, $10.00 / tokens de saída de 1M
0,0087 millóns
Páxina 2.0 Pro
$1.25, prompts de entrada ≤ 128k tokens$2.50, prompts de entrada > 128k tokens$5.00, prompts de saída ≤ 128k tokens$10.00, prompts de saída > 128k tokens
$1.25, prompts de entrada ≤ 128k tokens$2.50, prompts de entrada > 128k tokens$5.00, prompts de saída ≤ 128k tokens$10.00, prompts de saída > 128k tokens
0,0045 millóns
$10 / 1000 páxinas + $0.27 / 1M tokens de entrada, $1.10 / 1M tokens de saída
$10 / 1000 páxinas + $0.27 / 1M tokens de entrada, $1.10 / 1M tokens de saída
$10 / 1000 páxinas + $0.27 / 1M tokens de entrada, $1.10 / 1M tokens de saída
0 011
0 011
Notes:
(1) — $ 8 / 1000 páxinas despois dun millón por mes
(2) — Additional $10 per 1000 pages for using a text recognition model
Principais descubrimentos
Most Efficient: Gemini e GPT-4o son líderes en eficiencia e consistencia da extracción en todas as facturas.
️Worst performer: Google AI é o peor de todos os modelos probados cando se trata de extracción de elementos, o que fai que a puntuación global de eficiencia sexa baixa.
Least ReliableDeepSeek mostrou erros frecuentes en valores de texto e numéricos.
Cal é o mellor modelo para que?
✅ Gemini, AWS ou Azure para a extracción de datos de alta precisión.
✅ GPT-4o (entrada de texto con OCR de terceiros) para un recoñecemento de factura económico e un gran equilibrio custo-eficiencia.
❌ Avoid Google AI if you need to extract items with high accuracy.








