






















随着人工智能服务及其消耗和创建的数据在各种应用程序和流程中变得越来越重要和普遍,它们所构建的平台和架构也变得越来越重要和普遍。与往常一样,没有“一刀切”的方法,但是,这里简要介绍的是这种数据驱动的人工智能应用架构的优化方法。
所有提到的源代码和更多内容都可以在这里找到,还有一个免费的“使用 Oracle AI 和数据库服务进行开发:Gen、Vision、Speech、Language 和 OML”研讨会(其中所有用例均基于联合国 17可持续发展目标)提供了更多示例,请参见此处。
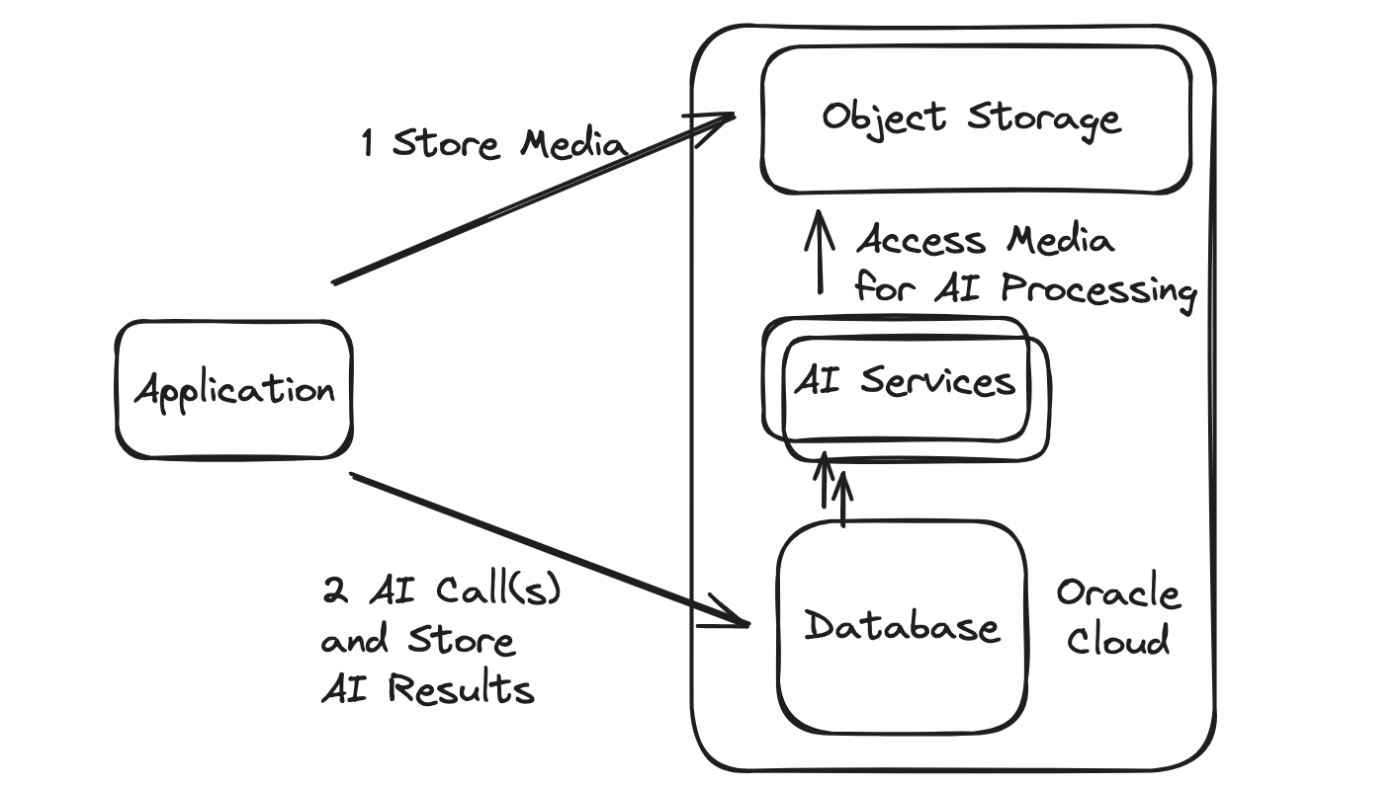
通常,必须在给定的 AI 应用程序中进行多个网络调用,需要调用 AI 服务以及调用以检索和保留作为输入或内容的内容(无论是文本、音频、图像、视频等)。输出。然后,持久信息通常会被进一步处理和分析,并做出额外的调用(人工智能或其他方式)作为反应。
Oracle 数据库提供了调用其他服务(同样是 AI 等)的能力,无论它们是在 Oracle 云内部还是外部。
当调用是从数据库本身进行时,它提供了一个优化的架构,具有多种优点,包括:
减少网络调用,从而减少延迟。
减少网络调用,从而提高可靠性。
对 AI 和其他数据(甚至使用 TxEventQ 时的消息传递)进行事务性 (ACID) 操作,避免了对幂等/重复处理逻辑等的需要,以及相关的资源浪费。
处理优化取决于数据的局部性,无论该数据是直接存储在数据库、对象存储还是其他源中。这是因为 Oracle 数据库为原本愚蠢的对象存储桶提供了强大的功能前端,并且数据库提供了许多选项来同步或优化操作对象存储和其他数据源中的数据。
由于通用身份验证机制以及对著名的强大数据库和云安全基础设施的重用,增强了安全性。
由于从中央位置进行呼叫,因此减少了总体配置。只需单击一下即可将数据库本身的入口点公开为 Rest 端点(使用 ORDS),当然也可以使用各种语言的驱动程序来访问数据库。
矢量数据库的优点。本主题本身就是一个博客,我将作为后续内容发布该主题,特别是因为 Oracle 已经并且正在该领域添加一些强大的功能。
Oracle 数据库机器学习。除了各种人工智能服务之外,Oracle数据库本身多年来也拥有机器学习引擎。 OML 简化了 ML 生命周期,提供可扩展的 SQL、R、Python、REST、AutoML 和具有 30 多种数据库内算法的无代码工具,通过直接在数据库中处理数据来增强数据同步和安全性。
Oracle 自治数据库。选择 AI,它可以使用自然语言查询数据并生成特定于您的数据库的 SQL。
Oracle 自治数据库。 AI Vector Search 包括新的矢量数据类型、矢量索引和矢量搜索 SQL 运算符,使 Oracle 数据库能够将文档、图像和其他非结构化数据的语义内容存储为矢量,并使用它们来运行快速相似性查询。
这些新功能还支持 RAG(检索增强生成),它提供更高的准确性,并通过将私人数据包含在 LLM 训练数据中来避免暴露私人数据。
同样,人工智能应用程序流程和要求有很多不同,但两种方法的基本比较可以通过以下方式进行可视化:


代码
可以在数据库中运行多种不同的语言,从而可以在那里执行各种应用程序逻辑。其中包括 Java、JavaScript 和 PL/SQL。这里给出了 PL/SQL 示例,它们可以从 OCI 控制台中的数据库操作 -> SQL页面、SQLcl 命令行工具(预装在 OCI Cloud Shell 中或可以下载)、从SQLDeveloper、VS Code(Oracle 有一个方便的插件)等。
还有几种方法可以调用人工智能和其他服务。使用数据库的 UTL_HTTP 包或从 JavaScript 获取等的标准 Rest 调用是一种方法。如果AI服务在OCI(Oracle Cloud)内运行,那么也可以使用为所有主要语言编写的OCI SDK。
我发现对所有 OCI 服务调用(而不是更具体的 OCI SDK 调用,如 DBMS_CLOUD_OCI_AIV_AI_SERVICE_VISION)使用 DBMS_CLOUD.send_request 包是最简单、最动态的方法。
我们首先创建一个可被所有云服务调用引用和重用的凭证,并且仅包含您的 OCI 帐户/配置中的信息。
BEGIN dbms_cloud.create_credential ( credential_name => 'OCI_KEY_CRED', user_ocid => 'ocid1.user.oc1..[youruserocid]', tenancy_ocid => 'ocid1.tenancy.oc1..[yourtenancyocid]', private_key => '[yourprivatekey - you can read this from file or put the contents of your pem without header, footer, and line wraps]' fingerprint => '[7f:yourfingerprint]' ); END;
接下来,在查看主程序/函数之前,让我们快速查看一下将保存 AI 结果的表。请注意,在本例中,该表包含来自 AI 调用返回的 JSON 和文本的列从 JSON 中的关键字段创建的字段,用于快速参考、搜索等。
同样,表结构、SQL/关系型数据库与 JSON 的使用等都可能有所不同,而且,这是 Oracle 多用途数据库的一个很好的示例,您可以在其中使用各种数据模型和数据类型。
例如,Oracle 数据库中的 JSON Duality 功能值得一试,因为它允许使用 SQL/关系以及 JSON 甚至 MongoDB API 访问相同的数据。
CREATE TABLE aivision_results (id RAW (16) NOT NULL, date_loaded TIMESTAMP WITH TIME ZONE, label varchar2(20), textfromai varchar2(32767), jsondata CLOB CONSTRAINT ensure_aivision_results_json CHECK (jsondata IS JSON)); /
现在,这个简单的函数代表了架构的核心......在这里,我们看到使用我们创建的凭证和 (AI) 服务操作端点的 URL(Oracle Vision AI 服务的analyzeImage操作)调用 DBMS_CLOUD.send_request在这种情况下)。
正文的 JSON 有效负载由我们想要使用的服务的功能和任何其他配置以及操作的参数组成,在本例中,包括图像的对象存储位置(另一个选项是直接提供图像字节数组/内联作为有效负载的一部分)。
然后从响应中检索 JSON 结果,为了方便起见,将其某些元素解析为文本字段,并且如前所述保留 JSON、文本等。
CREATE OR REPLACE FUNCTION VISIONAI_TEXTDETECTION ( p_endpoint VARCHAR2, p_compartment_ocid VARCHAR2, p_namespaceName VARCHAR2, p_bucketName VARCHAR2, p_objectName VARCHAR2, p_featureType VARCHAR2, p_label VARCHAR2 ) RETURN VARCHAR2 IS resp DBMS_CLOUD_TYPES.resp; json_response CLOB; v_textfromai VARCHAR2(32767); BEGIN resp := DBMS_CLOUD.send_request( credential_name => 'OCI_KEY_CRED', uri => p_endpoint || '/20220125/actions/analyzeImage', method => 'POST', body => UTL_RAW.cast_to_raw( JSON_OBJECT( 'features' VALUE JSON_ARRAY( JSON_OBJECT('featureType' VALUE p_featureType) ), 'image' VALUE JSON_OBJECT( 'source' VALUE 'OBJECT_STORAGE', 'namespaceName' VALUE p_namespaceName, 'bucketName' VALUE p_bucketName, 'objectName' VALUE p_objectName ), 'compartmentId' VALUE p_compartment_ocid ) ) ); json_response := DBMS_CLOUD.get_response_text(resp); SELECT LISTAGG(text, ', ') WITHIN GROUP (ORDER BY ROWNUM) INTO v_textfromai FROM JSON_TABLE(json_response, '$.imageText.words[*]' COLUMNS ( text VARCHAR2(100) PATH '$.text' ) ); INSERT INTO aivision_results (id, date_loaded, label, textfromai, jsondata) VALUES (SYS_GUID(), SYSTIMESTAMP, p_label, v_textfromai, json_response); RETURN v_textfromai; EXCEPTION WHEN OTHERS THEN RAISE; END VISIONAI_TEXTDETECTION; /
我们还可以使用以下代码以编程方式将该函数公开为 Rest 端点:
BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_OBJECTDETECTION', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_OBJECTDETECTION', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /AI结果分析与文本检索
这种架构还使得所有人工智能结果的分析和文本搜索变得方便高效。从这里开始,可以进行更多的处理和分析。让我们看一下三个语句,它们将为我们提供易于使用的人工智能结果文本搜索。
- 首先,我们在aivision_results表上创建一个用于文本搜索的索引。
- 然后,我们创建一个使用强大的contains功能搜索给定字符串的函数,或者我们可以另外/可选地使用DBMS_SEARCH包来搜索多个表并返回结果的引用游标。
- 最后,我们将该函数公开为 Rest 端点。
就是这么简单。
create index aivisionresultsindex on aivision_results(textfromai) indextype is ctxsys.context; / CREATE OR REPLACE FUNCTION VISIONAI_RESULTS_TEXT_SEARCH(p_sql IN VARCHAR2) RETURN SYS_REFCURSOR AS refcursor SYS_REFCURSOR; BEGIN OPEN refcursor FOR select textfromai from AIVISION_RESULTS where contains ( textfromai, p_sql ) > 0; RETURN refcursor; END VISIONAI_RESULTS_TEXT_SEARCH; / BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_RESULTS_TEXT_SEARCH', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_RESULTS_TEXT_SEARCH', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /综上所述…
这是一篇简短的博客,展示了通过直接从数据库调用人工智能服务来开发数据驱动的人工智能应用程序的架构模式。
非常感谢您的阅读,如果您有任何问题或反馈,请告诉我。
也发布在这里








