






















AI 서비스와 이들이 소비하고 생성하는 데이터가 다양한 애플리케이션과 프로세스에서 더욱 중요해지고 보편화됨에 따라 이를 구축하는 플랫폼과 아키텍처도 마찬가지입니다. 평소와 같이 "모든 것에 맞는 단일 크기"는 없습니다. 그러나 여기서 간략하게 제시하는 것은 이러한 데이터 기반 AI 애플리케이션 아키텍처에 대한 최적화된 접근 방식입니다.
언급된 모든 소스 코드와 그 이상은 여기에서 찾을 수 있으며, 무료 "Develop with Oracle AI and Database Services: Gen, Vision, Speech, Language, and OML" 워크숍(모든 사용 사례는 UN의 17개 조항을 기반으로 함) 지속 가능한 개발 목표) 더 많은 예를 보려면 여기에서 찾을 수 있습니다.
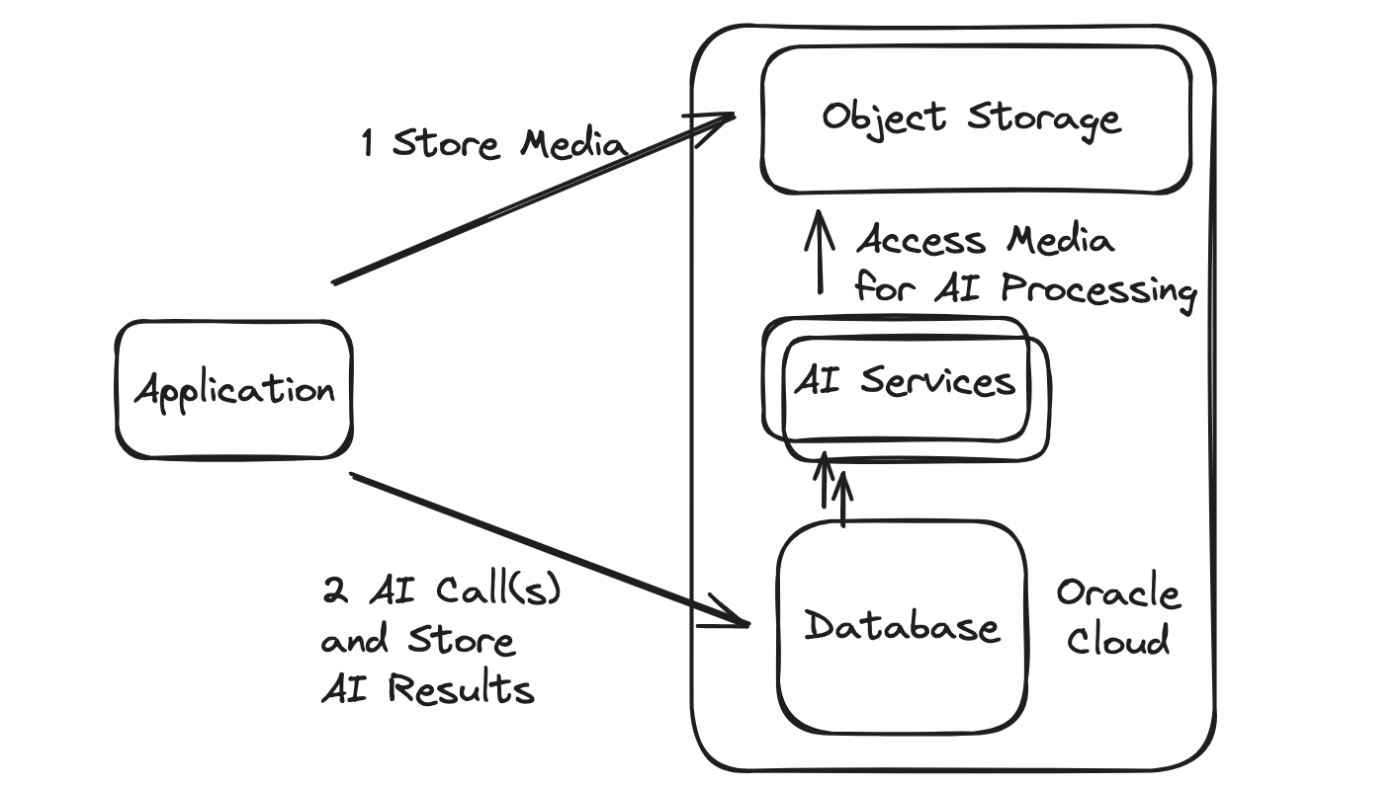
종종 특정 AI 앱에서 여러 네트워크 호출을 수행해야 하며, AI 서비스에 대한 호출은 물론 입력 또는 콘텐츠인 콘텐츠(텍스트, 오디오, 이미지, 비디오 등)를 검색하고 유지하기 위한 호출도 수반됩니다. 산출. 그런 다음 지속적인 정보는 종종 추가로 처리 및 분석되며 이에 대한 반응으로 AI 또는 기타 추가 호출이 이루어집니다.
Oracle 데이터베이스는 Oracle Cloud 내부에 있든 외부에 있든 상관없이 다른 서비스(AI 등)를 호출할 수 있는 기능을 제공합니다.
대신 데이터베이스 자체에서 호출이 이루어지면 다음과 같은 다양한 이점을 갖춘 최적화된 아키텍처를 제공합니다.
네트워크 호출이 줄어들어 대기 시간이 줄어듭니다.
네트워크 호출이 줄어들어 안정성이 향상됩니다.
멱등성/중복 처리 논리 등의 필요성을 방지하는 AI 및 기타 데이터(및 TxEventQ를 사용하는 경우 메시징까지)에 대한 트랜잭션(ACID) 작업과 관련 리소스 낭비가 발생합니다.
처리 최적화는 데이터가 데이터베이스, 개체 저장소 또는 기타 소스에 직접 저장되는지 여부에 따라 데이터의 지역성에 따라 달라집니다. 이는 Oracle 데이터베이스가 멍청한 객체 스토리지 버킷에 강력한 기능적 프런트엔드를 제공하고 데이터베이스가 객체 저장소 및 기타 데이터 소스에 있는 데이터를 동기화하거나 최적으로 작동할 수 있는 많은 옵션을 제공하기 때문입니다.
공통 인증 메커니즘과 유명한 강력한 데이터베이스 및 클라우드 보안 인프라의 재사용으로 보안이 강화되었습니다.
중앙 위치에서 호출이 이루어지므로 전체 구성이 줄어듭니다. 데이터베이스 자체에 대한 진입점은 한 번의 클릭으로 Rest 엔드포인트(ORDS 사용)로 노출될 수 있으며, 물론 다양한 언어의 드라이버를 사용하여 데이터베이스에 액세스할 수도 있습니다.
벡터 데이터베이스의 장점. 이 주제는 그 자체로 블로그이며 특히 Oracle이 이 영역에 몇 가지 강력한 기능을 추가하고 있는 것처럼 후속 주제로 발표할 것입니다.
오라클 데이터베이스 머신 러닝. 다양한 AI 서비스 외에도 오라클 데이터베이스 자체에는 수년간 머신러닝 엔진이 탑재되어 있습니다. OML은 확장 가능한 SQL, R, Python, REST, AutoML 및 30개 이상의 데이터베이스 내 알고리즘이 포함된 코드 없는 도구를 제공하여 ML 수명 주기를 간소화하고 데이터베이스에서 직접 데이터를 처리하여 데이터 동기화 및 보안을 강화합니다.
오라클 자율 데이터베이스. 자연어를 사용하여 데이터를 쿼리하고 데이터베이스에 특정한 SQL을 생성할 수 있는 AI를 선택하세요.
오라클 자율 데이터베이스. 새로운 벡터 데이터 유형, 벡터 인덱스 및 벡터 검색 SQL 연산자를 포함하는 AI 벡터 검색을 통해 Oracle 데이터베이스는 문서, 이미지 및 기타 비정형 데이터의 의미론적 콘텐츠를 벡터로 저장하고 이를 사용하여 빠른 유사성 쿼리를 실행할 수 있습니다. .
이러한 새로운 기능은 더 높은 정확도를 제공하고 개인 데이터를 LLM 교육 데이터에 포함시켜 노출할 필요가 없는 RAG(Retrieval Augmented Generation)도 지원합니다.
다시 말하지만, AI 애플리케이션 흐름과 요구 사항은 다양하지만 두 접근 방식의 기본 비교는 다음과 같은 방식으로 시각화할 수 있습니다.


코드
데이터베이스에서 여러 가지 다른 언어를 실행할 수 있으므로 그곳에서 다양한 애플리케이션 논리를 수행할 수 있습니다. 여기에는 Java, JavaScript 및 PL/SQL이 포함됩니다. PL/SQL 예제는 여기에 제공되며 OCI 콘솔의 데이터베이스 작업 -> SQL 페이지, SQLcl 명령줄 도구(OCI Cloud Shell에 사전 설치되거나 다운로드 가능), SQLDeveloper, VS Code(Oracle에는 편리한 플러그인이 있음) 등
AI 및 기타 서비스를 호출하는 방법도 몇 가지 있습니다. 데이터베이스의 UTL_HTTP 패키지를 사용하거나 JavaScript에서 가져오는 등의 표준 Rest 호출이 하나의 접근 방식입니다. AI 서비스가 OCI(Oracle Cloud) 내에서 실행되는 경우 모든 주요 언어로 작성된 OCI SDK도 사용할 수 있습니다.
나는 모든 OCI 서비스 호출(예를 들어 DBMS_CLOUD_OCI_AIV_AI_SERVICE_VISION과 같은 보다 구체적인 OCI SDK 호출 대신)에 대해 DBMS_CLOUD.send_request 패키지를 사용하는 것이 가장 간단하고 동적인 접근 방식이라고 생각합니다.
모든 클라우드 서비스 호출에 대해 참조 및 재사용할 수 있고 OCI 계정/구성의 정보만 포함할 수 있는 자격 증명을 만드는 것부터 시작합니다.
BEGIN dbms_cloud.create_credential ( credential_name => 'OCI_KEY_CRED', user_ocid => 'ocid1.user.oc1..[youruserocid]', tenancy_ocid => 'ocid1.tenancy.oc1..[yourtenancyocid]', private_key => '[yourprivatekey - you can read this from file or put the contents of your pem without header, footer, and line wraps]' fingerprint => '[7f:yourfingerprint]' ); END;
다음으로 기본 프로그램/함수를 살펴보기 전에 AI 결과를 저장할 테이블을 빠르게 살펴보겠습니다. 이 경우 테이블에는 AI 호출 반환의 JSON과 텍스트에 대한 열이 모두 있습니다. 빠른 참조, 검색 등을 위해 JSON의 주요 필드에서 생성된 필드입니다.
다시 말하지만, 테이블 구조, SQL/관계형과 JSON의 사용 등은 모두 다를 수 있으며, 이는 다양한 데이터 모델과 데이터 유형을 사용할 수 있는 Oracle 다목적 데이터베이스의 훌륭한 예입니다.
예를 들어, Oracle 데이터베이스의 JSON 이중성 기능은 SQL/관계형은 물론 JSON, MongoDB API를 사용하여 동일한 데이터에 액세스할 수 있으므로 확인해 볼 가치가 있습니다.
CREATE TABLE aivision_results (id RAW (16) NOT NULL, date_loaded TIMESTAMP WITH TIME ZONE, label varchar2(20), textfromai varchar2(32767), jsondata CLOB CONSTRAINT ensure_aivision_results_json CHECK (jsondata IS JSON)); /
그리고 이제 아키텍처의 핵심을 대표하는 간단한 함수... 여기서는 우리가 생성한 자격 증명과 (AI) 서비스 작업 끝점(Oracle Vision AI 서비스의 analyzeImage 작업)의 URL을 사용하여 DBMS_CLOUD.send_request에 대한 호출을 볼 수 있습니다. 이 경우).
본문의 JSON 페이로드는 사용하려는 서비스의 기능과 기타 구성뿐만 아니라 이 경우 이미지의 개체 저장 위치(다른 구성)를 포함하는 작업에 대한 인수로 구성됩니다. 옵션은 페이로드의 일부로 이미지 바이트 배열을 직접/인라인으로 제공하는 것입니다.
그런 다음 JSON 결과가 응답에서 검색되고, 해당 결과의 특정 요소가 편의를 위해 텍스트 필드로 구문 분석되며, 앞서 언급한 대로 JSON, 텍스트 등이 유지됩니다.
CREATE OR REPLACE FUNCTION VISIONAI_TEXTDETECTION ( p_endpoint VARCHAR2, p_compartment_ocid VARCHAR2, p_namespaceName VARCHAR2, p_bucketName VARCHAR2, p_objectName VARCHAR2, p_featureType VARCHAR2, p_label VARCHAR2 ) RETURN VARCHAR2 IS resp DBMS_CLOUD_TYPES.resp; json_response CLOB; v_textfromai VARCHAR2(32767); BEGIN resp := DBMS_CLOUD.send_request( credential_name => 'OCI_KEY_CRED', uri => p_endpoint || '/20220125/actions/analyzeImage', method => 'POST', body => UTL_RAW.cast_to_raw( JSON_OBJECT( 'features' VALUE JSON_ARRAY( JSON_OBJECT('featureType' VALUE p_featureType) ), 'image' VALUE JSON_OBJECT( 'source' VALUE 'OBJECT_STORAGE', 'namespaceName' VALUE p_namespaceName, 'bucketName' VALUE p_bucketName, 'objectName' VALUE p_objectName ), 'compartmentId' VALUE p_compartment_ocid ) ) ); json_response := DBMS_CLOUD.get_response_text(resp); SELECT LISTAGG(text, ', ') WITHIN GROUP (ORDER BY ROWNUM) INTO v_textfromai FROM JSON_TABLE(json_response, '$.imageText.words[*]' COLUMNS ( text VARCHAR2(100) PATH '$.text' ) ); INSERT INTO aivision_results (id, date_loaded, label, textfromai, jsondata) VALUES (SYS_GUID(), SYSTIMESTAMP, p_label, v_textfromai, json_response); RETURN v_textfromai; EXCEPTION WHEN OTHERS THEN RAISE; END VISIONAI_TEXTDETECTION; /
다음을 사용하여 프로그래밍 방식으로 함수를 Rest 끝점으로 노출할 수도 있습니다.
BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_OBJECTDETECTION', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_OBJECTDETECTION', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /AI 결과 분석 및 텍스트 검색
또한 이 아키텍처는 모든 AI 결과에 대한 분석 및 텍스트 검색을 편리하고 효율적으로 만듭니다. 여기에서 더 많은 처리와 분석이 이루어질 수 있습니다. AI 결과에 대한 사용하기 쉬운 텍스트 검색을 제공하는 세 가지 명령문을 살펴보겠습니다.
- 먼저 aivision_results 테이블에서 텍스트 검색을 위한 인덱스를 생성합니다.
- 그런 다음 강력한 포함 기능을 사용하여 특정 문자열을 검색하는 함수를 생성하거나 추가/선택적으로 DBMS_SEARCH 패키지를 사용하여 여러 테이블을 검색하고 결과의 참조 커서를 반환할 수 있습니다.
- 마지막으로 함수를 Rest 엔드포인트로 노출합니다.
그렇게 간단합니다.
create index aivisionresultsindex on aivision_results(textfromai) indextype is ctxsys.context; / CREATE OR REPLACE FUNCTION VISIONAI_RESULTS_TEXT_SEARCH(p_sql IN VARCHAR2) RETURN SYS_REFCURSOR AS refcursor SYS_REFCURSOR; BEGIN OPEN refcursor FOR select textfromai from AIVISION_RESULTS where contains ( textfromai, p_sql ) > 0; RETURN refcursor; END VISIONAI_RESULTS_TEXT_SEARCH; / BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_RESULTS_TEXT_SEARCH', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_RESULTS_TEXT_SEARCH', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /결론적으로…
이는 데이터베이스에서 직접 AI 서비스를 호출하여 데이터 기반 AI 앱을 개발하기 위한 아키텍처 패턴을 보여주는 빠른 블로그였습니다.
읽어주셔서 정말 감사드리며, 궁금한 점이나 피드백이 있으면 알려주시기 바랍니다.
여기에도 게시됨








