






















Da KI-Dienste und die von ihnen genutzten und erstellten Daten in verschiedenen Anwendungen und Prozessen immer wichtiger und verbreiteter werden, nehmen auch die Plattformen und Architekturen zu, auf denen sie aufbauen. Wie üblich gibt es kein „One-Size-Fits-All“, hier wird jedoch kurz ein optimierter Ansatz für solche datengesteuerten KI-Anwendungsarchitekturen vorgestellt.
Den gesamten erwähnten Quellcode und mehr finden Sie hier sowie einen kostenlosen Workshop „Entwickeln mit Oracle AI und Database Services: Gen, Vision, Speech, Language und OML“ (wobei alle Anwendungsfälle auf den 17 der UN basieren). Nachhaltige Entwicklungsziele) mit vielen weiteren Beispielen finden Sie hier .
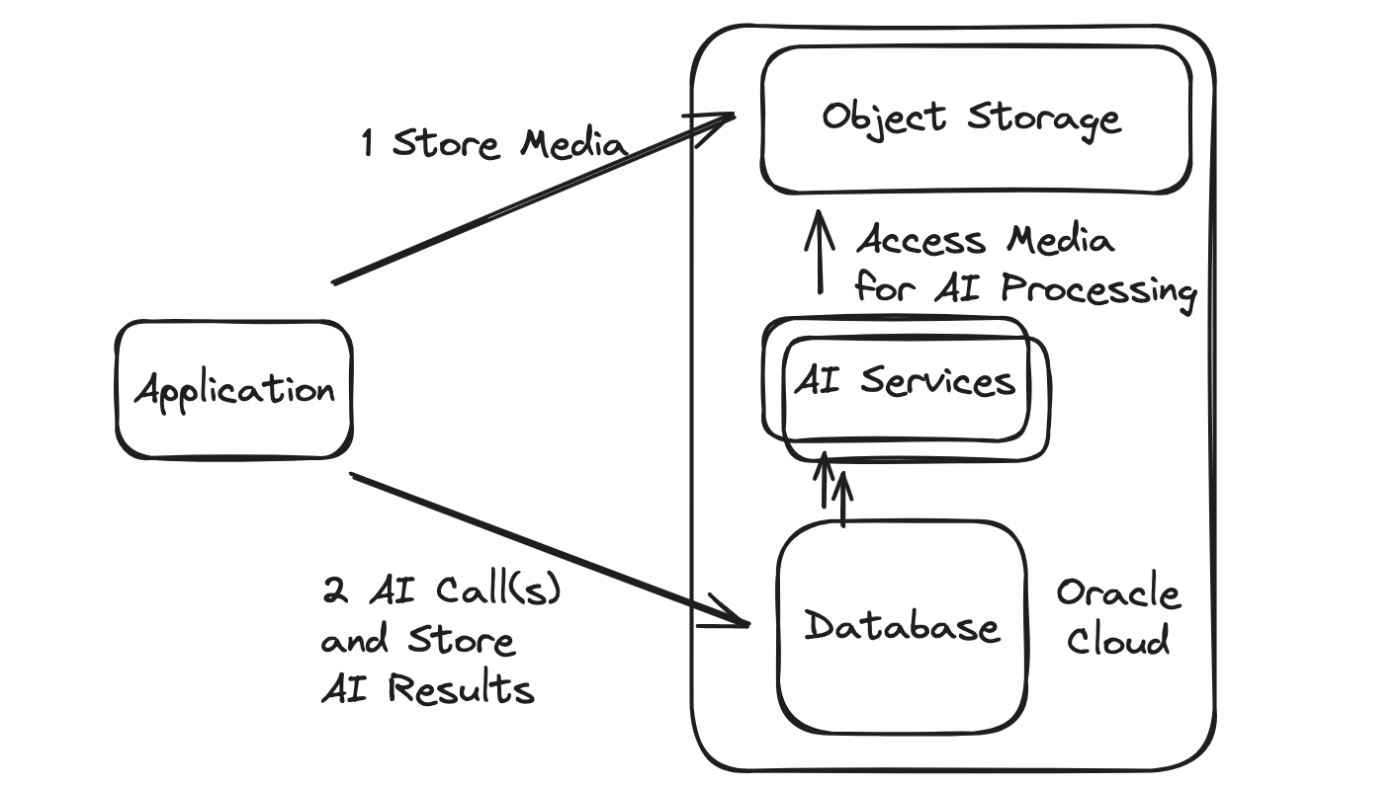
Oftmals müssen in einer bestimmten KI-App mehrere Netzwerkaufrufe getätigt werden, was Aufrufe an die KI-Dienste sowie Aufrufe zum Abrufen und Beibehalten des Inhalts (sei es Text, Audio, Bilder, Video usw.) mit sich bringt, der die Eingabe bzw Ausgabe. Die persistenten Informationen werden dann oft weiter verarbeitet und analysiert und als Reaktion werden zusätzliche Anrufe, KI oder auf andere Weise, getätigt.
Die Oracle-Datenbank bietet die Möglichkeit, Aufrufe an andere Dienste, wiederum KI und andere, zu tätigen, unabhängig davon, ob diese sich innerhalb der Oracle Cloud oder extern befinden.
Wenn die Aufrufe stattdessen aus der Datenbank selbst erfolgen, bietet dies eine optimierte Architektur mit verschiedenen Vorteilen, darunter:
Reduzierte Netzwerkanrufe und somit geringere Latenz.
Reduzierte Netzwerkanrufe und somit höhere Zuverlässigkeit.
Transaktionale (ACID) Operationen für KI und andere Daten (und sogar Nachrichtenübermittlung bei Verwendung von TxEventQ), die die Notwendigkeit einer idempotenten/doppelten Verarbeitungslogik usw. und die damit verbundene Verschwendung von Ressourcen vermeiden.
Die Verarbeitungsoptimierung beruht auf der Lokalität der Daten, unabhängig davon, ob diese Daten direkt in der Datenbank oder einem Objektspeicher oder einer anderen Quelle gespeichert sind. Dies liegt daran, dass die Oracle-Datenbank ein robustes funktionales Frontend für ansonsten dumme Objektspeicher-Buckets bietet und die Datenbank viele Optionen bietet, um Daten, die sich im Objektspeicher und anderen Datenquellen befinden, entweder zu synchronisieren oder optimal mit ihnen zu arbeiten.
Erhöhte Sicherheit durch einen gemeinsamen Authentifizierungsmechanismus und die Wiederverwendung einer bekanntermaßen robusten Datenbank- und Cloud-Sicherheitsinfrastruktur.
Reduzierte Gesamtkonfiguration, da Anrufe von einem zentralen Standort aus getätigt werden. Der Einstiegspunkt zur Datenbank selbst kann mit einem einzigen Klick als Rest-Endpunkt (mittels ORDS) offengelegt werden, und natürlich können auch Treiber in verschiedenen Sprachen für den Zugriff auf die Datenbank verwendet werden.
Vorteile der Vektordatenbank. Dieses Thema ist ein Blog für sich und ich werde es als Folgethema veröffentlichen, insbesondere da Oracle in diesem Bereich mehrere leistungsstarke Funktionen hinzugefügt hat und hinzufügt.
Maschinelles Lernen in Oracle-Datenbanken. Neben verschiedenen KI-Diensten verfügt die Oracle-Datenbank selbst seit vielen Jahren über eine Machine-Learning-Engine. OML rationalisiert den ML-Lebenszyklus und bietet skalierbare SQL-, R-, Python-, REST-, AutoML- und No-Code-Tools mit über 30 datenbankinternen Algorithmen und verbessert die Datensynchronisierung und -sicherheit durch die direkte Verarbeitung von Daten in der Datenbank.
Oracle Autonomous Database. Wählen Sie KI, die das Abfragen von Daten in natürlicher Sprache und die Generierung von SQL ermöglicht, das für Ihre Datenbank spezifisch ist.
Oracle Autonomous Database. AI Vector Search, das einen neuen Vektordatentyp, Vektorindizes und SQL-Operatoren für die Vektorsuche umfasst, ermöglicht es der Oracle-Datenbank, den semantischen Inhalt von Dokumenten, Bildern und anderen unstrukturierten Daten als Vektoren zu speichern und diese zum Ausführen schneller Ähnlichkeitsabfragen zu verwenden .
Diese neuen Funktionen unterstützen auch RAG (Retrieval Augmented Generation), das eine höhere Genauigkeit bietet und die Offenlegung privater Daten vermeidet, indem es diese in die LLM-Trainingsdaten einbezieht.
Auch hier gibt es viele unterschiedliche KI-Anwendungsabläufe und -Anforderungen, aber ein grundlegender Vergleich der beiden Ansätze lässt sich wie folgt veranschaulichen:


Der Code
Es ist möglich, mehrere verschiedene Sprachen in der Datenbank auszuführen, wodurch es möglich ist, dort verschiedene Anwendungslogiken durchzuführen. Dazu gehören Java, JavaScript und PL/SQL. Hier finden Sie PL/SQL-Beispiele, die über die Seite „Datenbankaktionen -> SQL“ in der OCI-Konsole, über das SQLcl-Befehlszeilentool (das in der OCI Cloud Shell vorinstalliert ist oder heruntergeladen werden kann) ausgeführt werden können SQLDeveloper, VS Code (wo Oracle ein praktisches Plugin hat) usw.
Es gibt auch einige Möglichkeiten, Anrufe an KI und andere Dienste zu richten. Standard-Rest-Aufrufe unter Verwendung des UTL_HTTP-Pakets der Datenbank oder Abruf aus JavaScript usw. sind ein Ansatz. Wenn die KI-Dienste innerhalb von OCI (der Oracle Cloud) laufen, können auch OCI SDKs verwendet werden, die für alle wichtigen Sprachen geschrieben sind.
Ich halte die Verwendung des Pakets DBMS_CLOUD.send_request für alle OCI-Dienstaufrufe (anstelle beispielsweise spezifischerer OCI-SDK-Aufrufe wie DBMS_CLOUD_OCI_AIV_AI_SERVICE_VISION) für den einfachsten und dynamischsten Ansatz.
Wir beginnen mit der Erstellung eines Berechtigungsnachweises, der für alle unsere Cloud-Service-Aufrufe referenziert und wiederverwendet werden kann und lediglich die Informationen aus Ihrem OCI-Konto/Ihrer OCI-Konfiguration enthält.
BEGIN dbms_cloud.create_credential ( credential_name => 'OCI_KEY_CRED', user_ocid => 'ocid1.user.oc1..[youruserocid]', tenancy_ocid => 'ocid1.tenancy.oc1..[yourtenancyocid]', private_key => '[yourprivatekey - you can read this from file or put the contents of your pem without header, footer, and line wraps]' fingerprint => '[7f:yourfingerprint]' ); END;
Bevor wir uns das Hauptprogramm/die Hauptfunktion ansehen, schauen wir uns als Nächstes kurz die Tabelle an, in der wir die KI-Ergebnisse speichern. Beachten Sie, dass die Tabelle in diesem Fall Spalten sowohl für den JSON aus einer KI-Aufrufrückgabe als auch für einen Text enthält Feld, das aus Schlüsselfeldern im JSON für Schnellreferenzen, Suchvorgänge usw. erstellt wird.
Auch hier können die Tabellenstrukturen, die Verwendung von SQL/relational vs. JSON usw. variieren, und auch dies ist ein großartiges Beispiel für die Oracle-Mehrzweckdatenbank, in der Sie verschiedene Datenmodelle und Datentypen verwenden können.
Es lohnt sich beispielsweise, die JSON Duality-Funktion in der Oracle-Datenbank auszuprobieren, da sie den Zugriff auf dieselben Daten sowohl über SQL/relationale als auch über JSON- und sogar MongoDB-APIs ermöglicht.
CREATE TABLE aivision_results (id RAW (16) NOT NULL, date_loaded TIMESTAMP WITH TIME ZONE, label varchar2(20), textfromai varchar2(32767), jsondata CLOB CONSTRAINT ensure_aivision_results_json CHECK (jsondata IS JSON)); /
Und nun die einfache Funktion, die das Herzstück der Architektur darstellt … Hier sehen wir einen Aufruf von DBMS_CLOUD.send_request mit den von uns erstellten Anmeldeinformationen und der URL des (KI-)Dienstoperationsendpunkts (der AnalyseImage- Operation des Oracle Vision AI-Dienstes). in diesem Fall).
Die JSON-Nutzlast des Körpers besteht aus den Funktionen des Dienstes, den wir verwenden möchten, und allen anderen Konfigurationen sowie den Argumenten für die Operation, die in diesem Fall den Objektspeicherort eines Bildes (eines anderen) umfassen Option wäre, das Bild-Byte-Array direkt/inlined als Teil der Nutzlast bereitzustellen.
Das JSON-Ergebnis wird dann aus der Antwort abgerufen, bestimmte Elemente davon werden der Einfachheit halber in ein Textfeld geparst und JSON, Text usw. werden, wie bereits erwähnt, beibehalten.
CREATE OR REPLACE FUNCTION VISIONAI_TEXTDETECTION ( p_endpoint VARCHAR2, p_compartment_ocid VARCHAR2, p_namespaceName VARCHAR2, p_bucketName VARCHAR2, p_objectName VARCHAR2, p_featureType VARCHAR2, p_label VARCHAR2 ) RETURN VARCHAR2 IS resp DBMS_CLOUD_TYPES.resp; json_response CLOB; v_textfromai VARCHAR2(32767); BEGIN resp := DBMS_CLOUD.send_request( credential_name => 'OCI_KEY_CRED', uri => p_endpoint || '/20220125/actions/analyzeImage', method => 'POST', body => UTL_RAW.cast_to_raw( JSON_OBJECT( 'features' VALUE JSON_ARRAY( JSON_OBJECT('featureType' VALUE p_featureType) ), 'image' VALUE JSON_OBJECT( 'source' VALUE 'OBJECT_STORAGE', 'namespaceName' VALUE p_namespaceName, 'bucketName' VALUE p_bucketName, 'objectName' VALUE p_objectName ), 'compartmentId' VALUE p_compartment_ocid ) ) ); json_response := DBMS_CLOUD.get_response_text(resp); SELECT LISTAGG(text, ', ') WITHIN GROUP (ORDER BY ROWNUM) INTO v_textfromai FROM JSON_TABLE(json_response, '$.imageText.words[*]' COLUMNS ( text VARCHAR2(100) PATH '$.text' ) ); INSERT INTO aivision_results (id, date_loaded, label, textfromai, jsondata) VALUES (SYS_GUID(), SYSTIMESTAMP, p_label, v_textfromai, json_response); RETURN v_textfromai; EXCEPTION WHEN OTHERS THEN RAISE; END VISIONAI_TEXTDETECTION; /
Wir können die Funktion auch programmgesteuert als Rest-Endpunkt verfügbar machen, indem wir Folgendes verwenden:
BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_OBJECTDETECTION', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_OBJECTDETECTION', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /Analyse und Textsuche von KI-Ergebnissen
Diese Architektur macht auch die Analyse und Textsuche aller KI-Ergebnisse bequem und effizient. Von hier aus können weitere Verarbeitungs- und Analysevorgänge durchgeführt werden. Werfen wir einen Blick auf drei Anweisungen, die uns eine benutzerfreundliche Textsuche unserer KI-Ergebnisse ermöglichen.
- Zuerst erstellen wir einen Index für Textsuchen in unserer Tabelle aivision_results .
- Anschließend erstellen wir eine Funktion, die mit der leistungsstarken Funktion „Contains“ nach einer bestimmten Zeichenfolge sucht, oder wir können zusätzlich/optional das Paket DBMS_SEARCH verwenden, um mehrere Tabellen zu durchsuchen und den Refcursor der Ergebnisse zurückzugeben.
- Schließlich stellen wir die Funktion als Rest-Endpunkt bereit.
So einfach ist das.
create index aivisionresultsindex on aivision_results(textfromai) indextype is ctxsys.context; / CREATE OR REPLACE FUNCTION VISIONAI_RESULTS_TEXT_SEARCH(p_sql IN VARCHAR2) RETURN SYS_REFCURSOR AS refcursor SYS_REFCURSOR; BEGIN OPEN refcursor FOR select textfromai from AIVISION_RESULTS where contains ( textfromai, p_sql ) > 0; RETURN refcursor; END VISIONAI_RESULTS_TEXT_SEARCH; / BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_RESULTS_TEXT_SEARCH', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_RESULTS_TEXT_SEARCH', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /Abschließend…
Dies war ein kurzer Blog, der ein Architekturmuster für die Entwicklung datengesteuerter KI-Apps zeigte, indem KI-Dienste direkt aus der Datenbank aufgerufen wurden.
Vielen Dank fürs Lesen. Teilen Sie mir bitte Ihre Fragen oder Ihr Feedback mit.
Auch hier veröffentlicht








