



































Jan 01, 1970
1,806 測定値
データ駆動型 AI アプリを開発する方法: データベースから AI サービスを直接作成するためのガイド
長すぎる; 読むには
このブログでは、AI 呼び出しが Oracle ベクトル データベースから直接行われる、データ駆動型 AI アプリケーション アーキテクチャの最適化されたアプローチについて説明します。AI サービスと、AI サービスが消費および作成するデータの重要性が高まり、さまざまなアプリケーションやプロセスで普及するにつれて、それらが構築されるプラットフォームやアーキテクチャも同様に重要になります。いつものことですが、「万能」というものはありませんが、ここで簡単に説明するのは、そのようなデータ駆動型 AI アプリケーション アーキテクチャへの最適化されたアプローチです。
言及されているすべてのソースコードなどは、ここで見つけることができます。また、無料の「Oracle AI およびデータベースサービスを使用した開発: Gen、Vision、Speech、Language、および OML」ワークショップ (すべてのユースケースは国連の 17持続可能な開発目標) では、さらに多くの例をここでご覧いただけます。
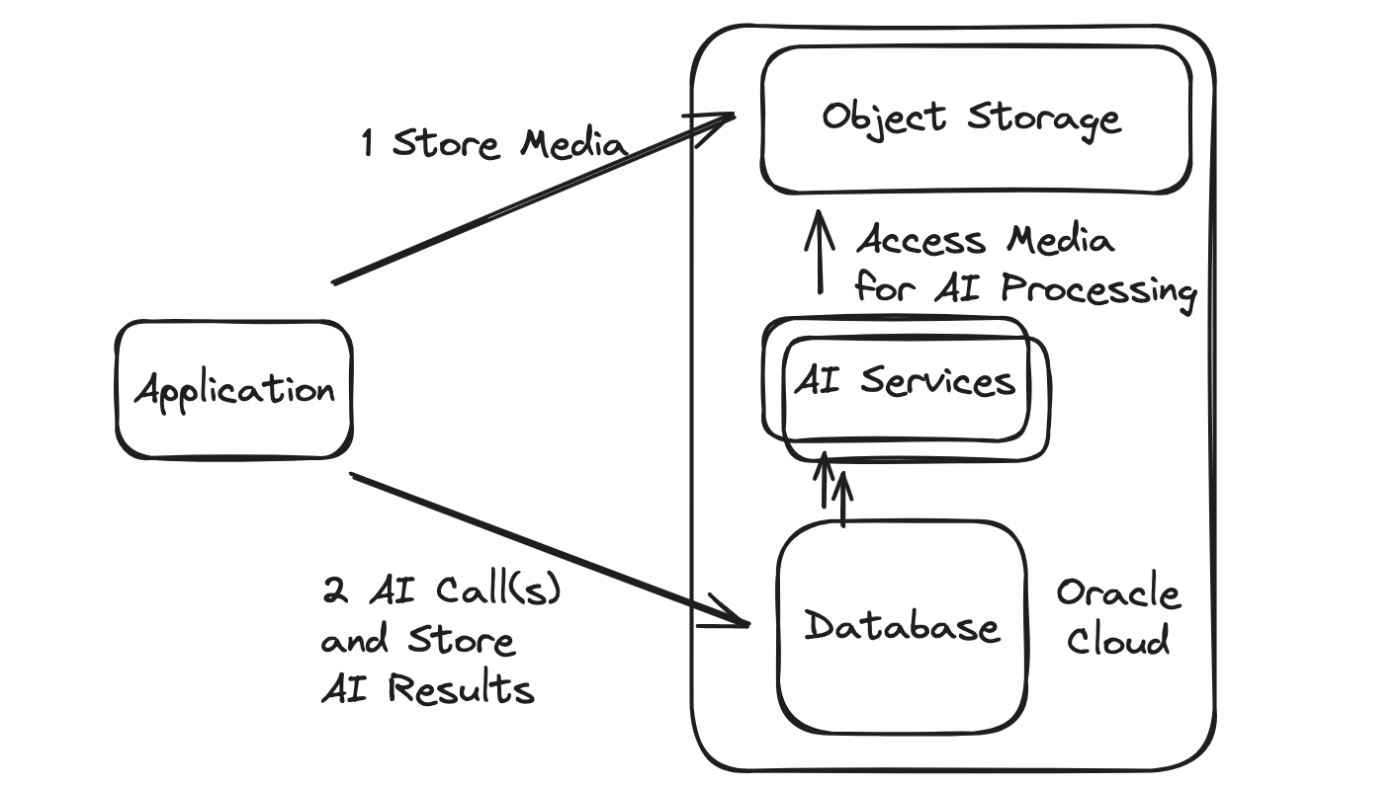
多くの場合、特定の AI アプリで複数のネットワーク呼び出しを行う必要があり、これには AI サービスへの呼び出しだけでなく、入力または入力であるコンテンツ (テキスト、オーディオ、画像、ビデオなど) を取得して保持するための呼び出しも伴います。出力。その後、永続的な情報がさらに処理および分析されることが多く、それに応じて追加の呼び出し (AI など) が行われます。
Oracleデータベースは、 Oracle Cloud内か外部かに関係なく、AIなどの他のサービスを呼び出す機能を提供します。
代わりにデータベース自体から呼び出しが行われると、最適化されたアーキテクチャが提供され、次のようなさまざまな利点が得られます。
ネットワーク呼び出しが減少し、遅延が減少します。
ネットワーク呼び出しが減少し、信頼性が向上します。
AI やその他のデータ (TxEventQ を使用する場合はメッセージングも) に対するトランザクション (ACID) 操作により、冪等/重複処理ロジックなどの必要性や、それに関連する無駄なリソースが回避されます。
処理の最適化は、データがデータベースに直接保存されるか、オブジェクト ストアやその他のソースに保存されるかにかかわらず、データの局所性に起因します。これは、Oracle データベースが、ダムなオブジェクト ストレージ バケットに対して堅牢な機能フロントエンドを提供し、オブジェクト ストアやその他のデータ ソース内のデータを同期したり、データを最適に操作したりするための多くのオプションを提供するためです。
共通の認証メカニズムと、堅牢なデータベースとクラウド セキュリティ インフラストラクチャの再利用により、セキュリティが強化されています。
中央の場所から通話が行われるため、全体的な構成が削減されます。データベース自体へのエントリ ポイントは、ワンクリックで REST エンドポイント (ORDS を使用) として公開できます。もちろん、さまざまな言語のドライバーを使用してデータベースにアクセスすることもできます。
ベクターデータベースの利点。このトピックはそれ自体がブログであり、特に Oracle がこの分野にいくつかの強力な機能を追加しているため、私はその続編としてリリースします。
Oracle データベース機械学習。さまざまな AI サービスに加えて、Oracle データベース自体にも長年にわたって機械学習エンジンが搭載されています。 OML は、ML ライフサイクルを合理化し、30 を超えるデータベース内アルゴリズムを備えたスケーラブルな SQL、R、Python、REST、AutoML、ノーコード ツールを提供し、データベース内でデータを直接処理することでデータの同期とセキュリティを強化します。
オラクル自律型データベース。自然言語を使用してデータをクエリし、データベースに固有の SQL を生成できる AI を選択します。
オラクル自律型データベース。 AI Vector Searchには、新しいベクトル・データ型、ベクトル索引およびベクトル検索SQL演算子が含まれており、Oracle Databaseでドキュメント、画像およびその他の非構造化データのセマンティック・コンテンツをベクトルとして格納し、これらを使用して類似性問合せを高速に実行できるようになります。 。
これらの新機能は、RAG (Retrieval Augmented Generation) もサポートしており、より高い精度を提供し、プライベート データを LLM トレーニング データに含めることで公開する必要を回避します。
繰り返しになりますが、AI アプリケーションのフローと要件は数多くありますが、2 つのアプローチの基本的な比較は次の方法で視覚化できます。
コード
データベース内で複数の異なる言語を実行できるため、そこでさまざまなアプリケーション ロジックを実行できます。これらには、Java、JavaScript、PL/SQL が含まれます。 PL/SQL の例はここに示されており、OCI コンソールの「データベース・アクション」→「SQL」ページ、SQLcl コマンドライン・ツール (OCI Cloud Shell にプリインストールされているかダウンロード可能)、から実行できます。 SQLDeveloper、VS Code (Oracle には便利なプラグインがあります) など。
AI やその他のサービスを呼び出す方法もいくつかあります。データベースの UTL_HTTP パッケージを使用した標準 Rest 呼び出しや JavaScript からのフェッチなどが 1 つのアプローチです。 AI サービスが OCI (Oracle Cloud) 内で実行される場合は、すべての主要言語用に作成された OCI SDK も使用できます。
すべてのOCIサービス・コール(たとえば、DBMS_CLOUD_OCI_AIV_AI_SERVICE_VISIONなどのより具体的なOCI SDKコールではなく)に DBMS_CLOUD.send_request パッケージを使用するのが、最もシンプルで動的なアプローチであることがわかりました。
まず、すべてのクラウド サービス呼び出しで参照および再利用できる資格情報を作成します。資格情報には、OCI アカウント/構成からの情報が含まれます。
BEGIN dbms_cloud.create_credential ( credential_name => 'OCI_KEY_CRED', user_ocid => 'ocid1.user.oc1..[youruserocid]', tenancy_ocid => 'ocid1.tenancy.oc1..[yourtenancyocid]', private_key => '[yourprivatekey - you can read this from file or put the contents of your pem without header, footer, and line wraps]' fingerprint => '[7f:yourfingerprint]' ); END;
次に、メインのプログラム/関数を確認する前に、AI の結果を保存するテーブルを簡単に見てみましょう。この場合、テーブルには AI 呼び出しの戻り値からの JSON とテキストの両方の列があることに注意してください。クイックリファレンスや検索などのために JSON のキーフィールドから作成されるフィールド。
繰り返しますが、テーブル構造、SQL/リレーショナルと JSON の使用などはすべて異なる場合があります。また、これは、さまざまなデータ モデルとデータ型を使用できる Oracle 多目的データベースの優れた例です。
たとえば、Oracle データベースの JSON Duality 機能は、SQL/リレーショナル、JSON、さらには MongoDB API を使用して同じデータにアクセスできるため、チェックしてみる価値があります。
CREATE TABLE aivision_results (id RAW (16) NOT NULL, date_loaded TIMESTAMP WITH TIME ZONE, label varchar2(20), textfromai varchar2(32767), jsondata CLOB CONSTRAINT ensure_aivision_results_json CHECK (jsondata IS JSON)); /
次に、アーキテクチャの中心を表す単純な関数です。ここでは、作成した資格証明と(AI)サービス操作エンドポイント(Oracle Vision AIサービスのanalyzeImage操作)のURLを使用したDBMS_CLOUD.send_requestへの呼び出しが表示されます。この場合)。
本文の JSON ペイロードは、使用したいサービスの機能とその他の設定、および操作の引数で構成されます。この場合、画像 (別の) のオブジェクトの保存場所が含まれます。オプションは、画像バイト配列をペイロードの一部として直接またはインラインで提供することです)。
次に、JSON 結果が応答から取得され、その特定の要素が便宜上テキスト フィールドに解析され、前述したように JSON、テキストなどが永続化されます。
CREATE OR REPLACE FUNCTION VISIONAI_TEXTDETECTION ( p_endpoint VARCHAR2, p_compartment_ocid VARCHAR2, p_namespaceName VARCHAR2, p_bucketName VARCHAR2, p_objectName VARCHAR2, p_featureType VARCHAR2, p_label VARCHAR2 ) RETURN VARCHAR2 IS resp DBMS_CLOUD_TYPES.resp; json_response CLOB; v_textfromai VARCHAR2(32767); BEGIN resp := DBMS_CLOUD.send_request( credential_name => 'OCI_KEY_CRED', uri => p_endpoint || '/20220125/actions/analyzeImage', method => 'POST', body => UTL_RAW.cast_to_raw( JSON_OBJECT( 'features' VALUE JSON_ARRAY( JSON_OBJECT('featureType' VALUE p_featureType) ), 'image' VALUE JSON_OBJECT( 'source' VALUE 'OBJECT_STORAGE', 'namespaceName' VALUE p_namespaceName, 'bucketName' VALUE p_bucketName, 'objectName' VALUE p_objectName ), 'compartmentId' VALUE p_compartment_ocid ) ) ); json_response := DBMS_CLOUD.get_response_text(resp); SELECT LISTAGG(text, ', ') WITHIN GROUP (ORDER BY ROWNUM) INTO v_textfromai FROM JSON_TABLE(json_response, '$.imageText.words[*]' COLUMNS ( text VARCHAR2(100) PATH '$.text' ) ); INSERT INTO aivision_results (id, date_loaded, label, textfromai, jsondata) VALUES (SYS_GUID(), SYSTIMESTAMP, p_label, v_textfromai, json_response); RETURN v_textfromai; EXCEPTION WHEN OTHERS THEN RAISE; END VISIONAI_TEXTDETECTION; /
以下を使用して、プログラムで関数を REST エンドポイントとして公開することもできます。
BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_OBJECTDETECTION', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_OBJECTDETECTION', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /AI結果の分析とテキスト検索
このアーキテクチャにより、すべての AI 結果の分析とテキスト検索も便利かつ効率的になります。ここから、さらに多くの処理と分析を行うことができます。 AI 結果の使いやすいテキスト検索を提供する 3 つのステートメントを見てみましょう。
- まず、 aivision_resultsテーブルにテキスト検索用のインデックスを作成します。
- 次に、強力なcontains機能を使用して特定の文字列を検索する関数を作成します。または、追加またはオプションでDBMS_SEARCHパッケージを使用して複数のテーブルを検索し、結果の参照子を返すこともできます。
- 最後に、関数を Rest エンドポイントとして公開します。
それはとても簡単です。
create index aivisionresultsindex on aivision_results(textfromai) indextype is ctxsys.context; / CREATE OR REPLACE FUNCTION VISIONAI_RESULTS_TEXT_SEARCH(p_sql IN VARCHAR2) RETURN SYS_REFCURSOR AS refcursor SYS_REFCURSOR; BEGIN OPEN refcursor FOR select textfromai from AIVISION_RESULTS where contains ( textfromai, p_sql ) > 0; RETURN refcursor; END VISIONAI_RESULTS_TEXT_SEARCH; / BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_RESULTS_TEXT_SEARCH', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_RESULTS_TEXT_SEARCH', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /結論は…
これは、データベースから直接 AI サービスを呼び出すことによってデータ駆動型 AI アプリを開発するためのアーキテクチャ パターンを示す簡単なブログでした。
読んでいただきありがとうございます。ご質問やフィードバックがございましたらお知らせください。
ここでも公開されています
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ラベル
関連ストーリー

私の3年間のフリーランスの旅: 1200のプロジェクトを完了して大金を稼いだ方法 #freelancing
Jan 01, 1970

目に見えない層: ユーザーインタビューがかけがえのない資産である理由 #startup
Jan 01, 1970

