


























As AI services and the data they consume and create become more important and prevalent in various applications and processes, so do the platforms and architectures they are built upon. As usual, there is no “one size fits all”, however, what is briefly presented here is an optimized approach to such data-driven AI application architectures.
All of the source code mentioned and more can be found here, and a free “Develop with Oracle AI and Database Services: Gen, Vision, Speech, Language, and OML” workshop (where all of the use cases are based on the U.N.’s 17 Sustainable Development Goals) giving many more examples can be found here.
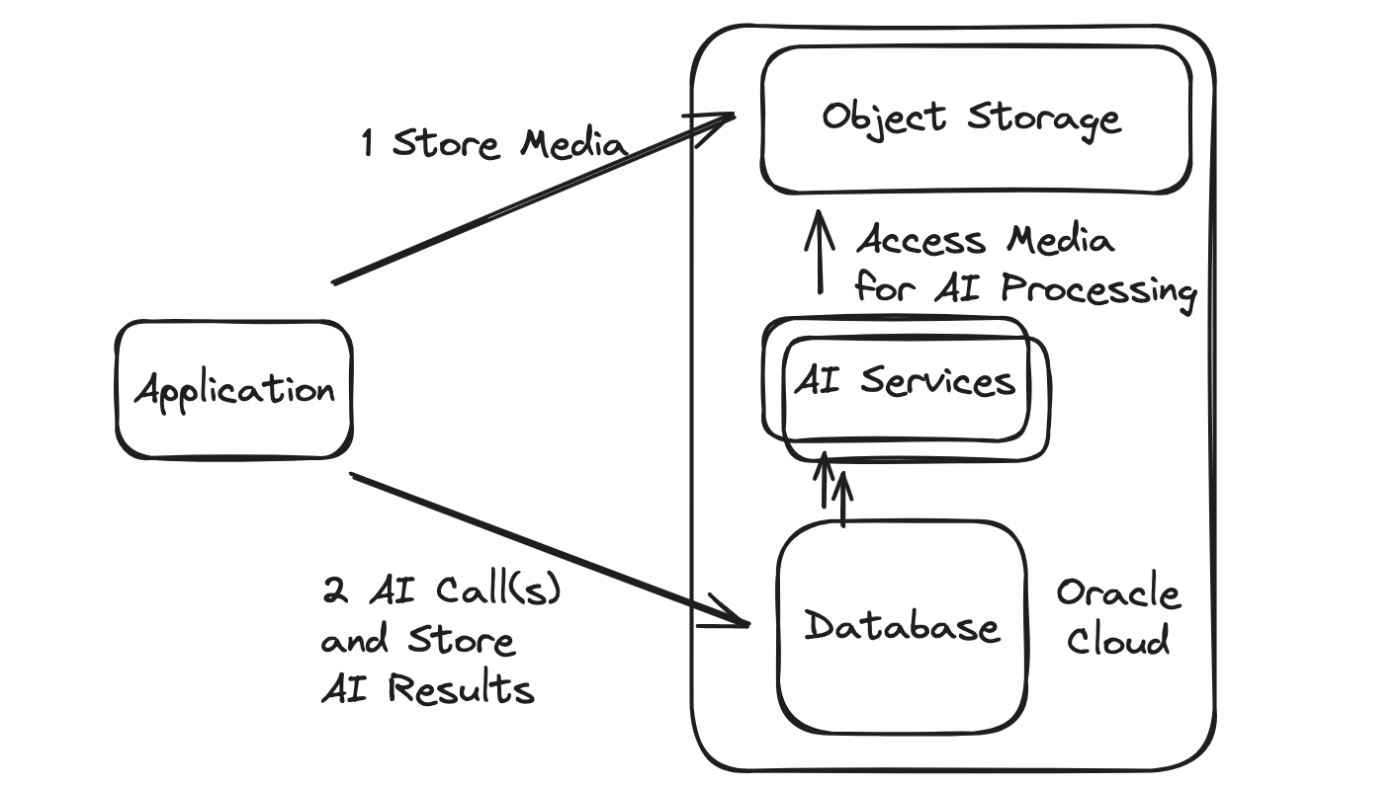
Often, multiple network calls must be made in a given AI app, entailing calls to the AI services as well as calls to retrieve and persist the content (whether it be text, audio, images, video, etc.) that is the input or output. The persistent information is then often processed and analyzed further and additional calls, AI or otherwise, are made in reaction.
The Oracle database provides the ability to make calls out to other services, again AI and otherwise, whether they be within the Oracle Cloud or external.
When the calls are instead made from the database itself, it provides an optimized architecture with various benefits including:
-
Reduced network calls, thus reducing latency.
-
Reduced network calls, thus, increasing reliability.
-
Transactional (ACID) operations on AI and other data (and even messaging when using TxEventQ) which avoid the need for idempotent/duplicate processing logic, etc., and the related wasted resources there.
-
Processing optimization is due to the locality of data whether that data is stored directly in the database or an object store or other source. This is because the Oracle database provides a robust functional frontend to otherwise dumb object storage buckets, and the database provides many options to either sync or optimally operate on data in place in the object store and other data sources.
-
Enhanced security due to a common authentication mechanism and reuse of a famously robust database and cloud security infrastructure.
-
Reduced overall configuration as calls are made from a central location. The entry point to the database itself can be exposed as a Rest endpoint (using ORDS) with a single click, and of course, drivers in various languages can be used to access the database as well.
-
Vector database advantages. This topic is a blog unto itself, and one I’ll release as a follow-on especially as Oracle has and is adding several powerful features in this area.
-
Oracle Database Machine Learning. In addition to various AI services, the Oracle database itself has had a machine-learning engine for many years. OML streamlines the ML lifecycle, offering scalable SQL, R, Python, REST, AutoML, and no-code tools with over 30 in-database algorithms, enhancing data synchronization and security by processing data directly in the database.
-
Oracle Autonomous Database. Select AI which enables querying data using natural language and generating SQL that is specific to your database.
-
Oracle Autonomous Database. AI Vector Search, which includes a new vector data type, vector indexes, and vector search SQL operators, enables the Oracle Database to store the semantic content of documents, images, and other unstructured data as vectors, and use these to run fast similarity queries.
These new capabilities also support RAG (Retrieval Augmented Generation) which provides higher accuracy and avoids having to expose private data by including it in the LLM training data.
Again, there are many different AI application flows and requirements, but a basic comparison of the two approaches can be visualized in the following way.:


The Code
It is possible to run several different languages in the database, making it possible to conduct various application logic there. These include Java, JavaScript, and PL/SQL. PL/SQL examples are given here, and they can be executed from the Database Actions -> SQL page in the OCI console, from the SQLcl command line tool (which is pre-installed in the OCI Cloud Shell or can be downloaded), from SQLDeveloper, VS Code (where Oracle has a convenient plugin), etc.
There are also a few ways to go about making the calls out to AI and other services. Standard Rest calls using the database’s UTL_HTTP package or fetch from JavaScript, etc., is one approach. If the AI services run within OCI (the Oracle Cloud), then OCI SDKs, which are written for all major languages, can also be used.
I find the use of the DBMS_CLOUD.send_request package for all OCI services calls (rather than, for example, more specific OCI SDK calls such as DBMS_CLOUD_OCI_AIV_AI_SERVICE_VISION) to be the simplest and most dynamic approach.
We start by creating a credential that can be referenced and reused for all of our cloud service calls and simply includes the information from your OCI account/config.
BEGIN
dbms_cloud.create_credential (
credential_name => 'OCI_KEY_CRED',
user_ocid => 'ocid1.user.oc1..[youruserocid]',
tenancy_ocid => 'ocid1.tenancy.oc1..[yourtenancyocid]',
private_key => '[yourprivatekey - you can read this from file or put the contents of your pem without header, footer, and line wraps]'
fingerprint => '[7f:yourfingerprint]'
);
END;
Next, before we look at the main program/function, let’s just quickly look at the table we’ll save the AI results in. Notice, in this case, the table has columns for both the JSON from an AI call return and a text field that is created from key fields in the JSON for quick reference, searches, etc.
Again, the table structures, use of SQL/relational vs JSON, etc., may all vary, and again, this is a great example of the Oracle multi-purpose database where you can use various data models and data types.
For example, the JSON Duality feature in the Oracle database is worth checking out as it allows the same data to be accessed using SQL/relational as well as JSON and even MongoDB APIs.
CREATE TABLE aivision_results
(id RAW (16) NOT NULL,
date_loaded TIMESTAMP WITH TIME ZONE,
label varchar2(20),
textfromai varchar2(32767),
jsondata CLOB
CONSTRAINT ensure_aivision_results_json CHECK (jsondata IS JSON));
/
And now, the simple function that typifies the heart of the architecture… Here, we see a call to DBMS_CLOUD.send_request with the credential we created and the URL of the (AI) service operation endpoint (the analyzeImage operation of the Oracle Vision AI service in this case).
The JSON payload of the body consists of the feature(s) of the service that we would like to use and any other config as well as the arguments to the operation which, in this case, include the object storage location of an image (another option would be to provide the image byte array directly/inlined as part of the payload).
The JSON result is then retrieved from the response, certain elements of it are parsed out into a text field for convenience, and the JSON, text, etc., are persisted as mentioned earlier.
CREATE OR REPLACE FUNCTION VISIONAI_TEXTDETECTION (
p_endpoint VARCHAR2,
p_compartment_ocid VARCHAR2,
p_namespaceName VARCHAR2,
p_bucketName VARCHAR2,
p_objectName VARCHAR2,
p_featureType VARCHAR2,
p_label VARCHAR2
) RETURN VARCHAR2 IS
resp DBMS_CLOUD_TYPES.resp;
json_response CLOB;
v_textfromai VARCHAR2(32767);
BEGIN
resp := DBMS_CLOUD.send_request(
credential_name => 'OCI_KEY_CRED',
uri => p_endpoint || '/20220125/actions/analyzeImage',
method => 'POST',
body => UTL_RAW.cast_to_raw(
JSON_OBJECT(
'features' VALUE JSON_ARRAY(
JSON_OBJECT('featureType' VALUE p_featureType)
),
'image' VALUE JSON_OBJECT(
'source' VALUE 'OBJECT_STORAGE',
'namespaceName' VALUE p_namespaceName,
'bucketName' VALUE p_bucketName,
'objectName' VALUE p_objectName
),
'compartmentId' VALUE p_compartment_ocid
)
)
);
json_response := DBMS_CLOUD.get_response_text(resp);
SELECT LISTAGG(text, ', ') WITHIN GROUP (ORDER BY ROWNUM)
INTO v_textfromai
FROM JSON_TABLE(json_response, '$.imageText.words[*]'
COLUMNS (
text VARCHAR2(100) PATH '$.text'
)
);
INSERT INTO aivision_results (id, date_loaded, label, textfromai, jsondata)
VALUES (SYS_GUID(), SYSTIMESTAMP, p_label, v_textfromai, json_response);
RETURN v_textfromai;
EXCEPTION
WHEN OTHERS THEN
RAISE;
END VISIONAI_TEXTDETECTION;
/
We can also expose the function as a Rest endpoint programmatically using the following:
BEGIN
ORDS.ENABLE_OBJECT(
P_ENABLED => TRUE,
P_SCHEMA => 'AIUSER',
P_OBJECT => 'VISIONAI_OBJECTDETECTION',
P_OBJECT_TYPE => 'FUNCTION',
P_OBJECT_ALIAS => 'VISIONAI_OBJECTDETECTION',
P_AUTO_REST_AUTH => FALSE
);
COMMIT;
END;
/
Analysis and Text Searching of AI Results
This architecture also makes analysis and text searching of all AI results convenient and efficient. From here, more processing and analytics can take place. Let’s take a look at three statements that will provide us with an easy-to-use text search of our AI results.
- First, we create an index for text searches on our aivision_results table.
- Then, we create a function that searches for a given string using the powerful contains functionality, or we could additionally/optionally use the DBMS_SEARCH package to search multiple tables and return the refcursor of results.
- Finally, we expose the function as a Rest endpoint.
It's that simple.
create index aivisionresultsindex on aivision_results(textfromai) indextype is ctxsys.context;
/
CREATE OR REPLACE FUNCTION VISIONAI_RESULTS_TEXT_SEARCH(p_sql IN VARCHAR2) RETURN SYS_REFCURSOR AS refcursor SYS_REFCURSOR;
BEGIN
OPEN refcursor FOR
select textfromai from AIVISION_RESULTS where contains ( textfromai, p_sql ) > 0;
RETURN refcursor;
END VISIONAI_RESULTS_TEXT_SEARCH;
/
BEGIN
ORDS.ENABLE_OBJECT(
P_ENABLED => TRUE,
P_SCHEMA => 'AIUSER',
P_OBJECT => 'VISIONAI_RESULTS_TEXT_SEARCH',
P_OBJECT_TYPE => 'FUNCTION',
P_OBJECT_ALIAS => 'VISIONAI_RESULTS_TEXT_SEARCH',
P_AUTO_REST_AUTH => FALSE
);
COMMIT;
END;
/
In Conclusion…
This was a quick blog showing an architectural pattern for developing data-driven AI Apps by making calls to AI services directly from the database.
Thanks so much for reading, and please let me know of any questions or feedback you may have.
Also published here












