






















Khi các dịch vụ AI và dữ liệu mà chúng tiêu thụ và tạo ra trở nên quan trọng và phổ biến hơn trong các ứng dụng và quy trình khác nhau, thì nền tảng và kiến trúc mà chúng được xây dựng dựa trên đó cũng vậy. Như thường lệ, không có “một kích thước phù hợp cho tất cả”, tuy nhiên, điều được trình bày ngắn gọn ở đây là một cách tiếp cận được tối ưu hóa cho các kiến trúc ứng dụng AI dựa trên dữ liệu như vậy.
Tất cả các mã nguồn được đề cập và nhiều mã nguồn khác có thể được tìm thấy tại đây và hội thảo “Phát triển với Oracle AI và các dịch vụ cơ sở dữ liệu: Gen, Vision, Speech, Language và OML” miễn phí (trong đó tất cả các trường hợp sử dụng đều dựa trên 17 của Liên hợp quốc). Mục tiêu Phát triển Bền vững) đưa ra nhiều ví dụ khác có thể được tìm thấy ở đây .
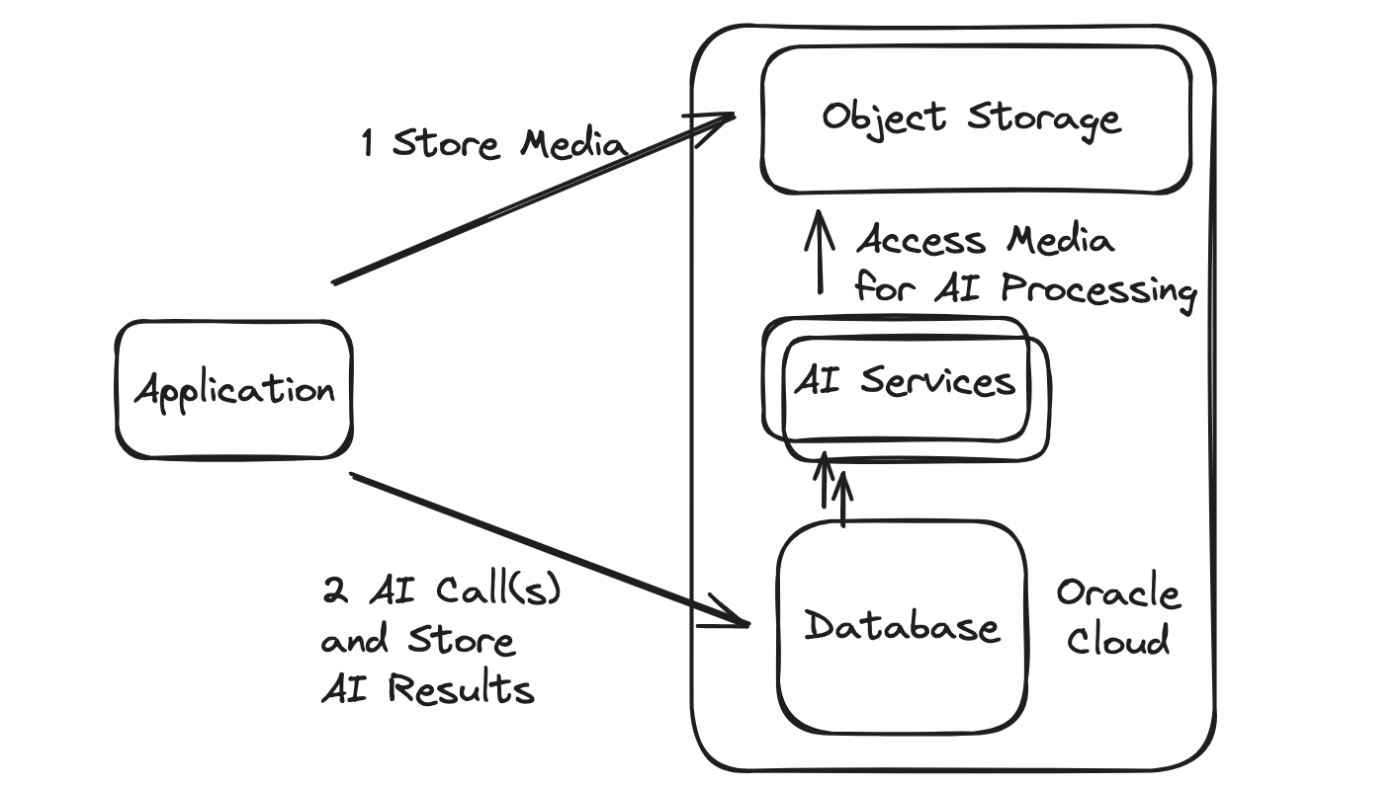
Thông thường, nhiều cuộc gọi mạng phải được thực hiện trong một ứng dụng AI nhất định, bao gồm các cuộc gọi đến dịch vụ AI cũng như các cuộc gọi để truy xuất và lưu giữ nội dung (cho dù đó là văn bản, âm thanh, hình ảnh, video, v.v.) là đầu vào hoặc đầu ra. Sau đó, thông tin liên tục thường được xử lý và phân tích sâu hơn và các lệnh gọi bổ sung, AI hoặc cách khác, được thực hiện theo phản ứng.
Cơ sở dữ liệu Oracle cung cấp khả năng thực hiện lệnh gọi đến các dịch vụ khác, lại là AI và mặt khác, cho dù chúng ở trong Đám mây Oracle hay bên ngoài.
Thay vào đó, khi các lệnh gọi được thực hiện từ chính cơ sở dữ liệu, nó sẽ cung cấp một kiến trúc được tối ưu hóa với nhiều lợi ích khác nhau, bao gồm:
Giảm cuộc gọi mạng, do đó giảm độ trễ.
Giảm các cuộc gọi mạng, do đó, tăng độ tin cậy.
Các hoạt động giao dịch (ACID) trên AI và dữ liệu khác (và thậm chí cả nhắn tin khi sử dụng TxEventQ) giúp tránh nhu cầu logic xử lý bình thường/trùng lặp, v.v. và các tài nguyên lãng phí liên quan ở đó.
Tối ưu hóa xử lý là do vị trí của dữ liệu cho dù dữ liệu đó được lưu trữ trực tiếp trong cơ sở dữ liệu hay kho lưu trữ đối tượng hoặc nguồn khác. Điều này là do cơ sở dữ liệu Oracle cung cấp giao diện người dùng chức năng mạnh mẽ cho các nhóm lưu trữ đối tượng đơn giản và cơ sở dữ liệu cung cấp nhiều tùy chọn để đồng bộ hóa hoặc vận hành tối ưu trên dữ liệu tại chỗ trong kho đối tượng và các nguồn dữ liệu khác.
Bảo mật nâng cao nhờ cơ chế xác thực chung và tái sử dụng cơ sở dữ liệu mạnh mẽ nổi tiếng cũng như cơ sở hạ tầng bảo mật đám mây.
Giảm cấu hình tổng thể khi các cuộc gọi được thực hiện từ một vị trí trung tâm. Điểm truy cập vào cơ sở dữ liệu có thể được hiển thị dưới dạng điểm cuối Rest (sử dụng ORDS) chỉ bằng một cú nhấp chuột và tất nhiên, trình điều khiển bằng nhiều ngôn ngữ khác nhau cũng có thể được sử dụng để truy cập cơ sở dữ liệu.
Ưu điểm của cơ sở dữ liệu vector. Chủ đề này tự nó là một blog và tôi sẽ phát hành một chủ đề tiếp theo, đặc biệt là khi Oracle có và đang bổ sung một số tính năng mạnh mẽ trong lĩnh vực này.
Học máy cơ sở dữ liệu Oracle. Ngoài các dịch vụ AI khác nhau, bản thân cơ sở dữ liệu Oracle cũng đã có công cụ học máy trong nhiều năm. OML hợp lý hóa vòng đời ML, cung cấp các công cụ SQL, R, Python, REST, AutoML và không có mã có thể mở rộng với hơn 30 thuật toán trong cơ sở dữ liệu, tăng cường đồng bộ hóa và bảo mật dữ liệu bằng cách xử lý dữ liệu trực tiếp trong cơ sở dữ liệu.
Cơ sở dữ liệu tự động của Oracle. Chọn AI cho phép truy vấn dữ liệu bằng ngôn ngữ tự nhiên và tạo SQL dành riêng cho cơ sở dữ liệu của bạn.
Cơ sở dữ liệu tự động của Oracle. Tìm kiếm Vector AI, bao gồm kiểu dữ liệu vectơ mới, chỉ mục vectơ và toán tử SQL tìm kiếm vectơ, cho phép Cơ sở dữ liệu Oracle lưu trữ nội dung ngữ nghĩa của tài liệu, hình ảnh và dữ liệu phi cấu trúc khác dưới dạng vectơ và sử dụng chúng để chạy các truy vấn tương tự nhanh chóng .
Những khả năng mới này cũng hỗ trợ RAG (Thế hệ tăng cường truy xuất) mang lại độ chính xác cao hơn và tránh phải tiết lộ dữ liệu riêng tư bằng cách đưa dữ liệu đó vào dữ liệu đào tạo LLM.
Một lần nữa, có nhiều luồng và yêu cầu ứng dụng AI khác nhau, nhưng có thể hình dung sự so sánh cơ bản của hai phương pháp này theo cách sau.:


Mật mã
Có thể chạy một số ngôn ngữ khác nhau trong cơ sở dữ liệu, giúp có thể tiến hành nhiều logic ứng dụng khác nhau ở đó. Chúng bao gồm Java, JavaScript và PL/SQL. Các ví dụ PL/SQL được đưa ra ở đây và chúng có thể được thực thi từ trang Hành động cơ sở dữ liệu -> SQL trong bảng điều khiển OCI, từ công cụ dòng lệnh SQLcl (được cài đặt sẵn trong OCI Cloud Shell hoặc có thể tải xuống), từ SQLDeveloper, VS Code (nơi Oracle có plugin tiện lợi), v.v.
Ngoài ra còn có một số cách để thực hiện cuộc gọi tới AI và các dịch vụ khác. Cuộc gọi Rest tiêu chuẩn sử dụng gói UTL_HTTP của cơ sở dữ liệu hoặc tìm nạp từ JavaScript, v.v., là một cách tiếp cận. Nếu các dịch vụ AI chạy trong OCI (Đám mây Oracle), thì SDK OCI, được viết cho tất cả các ngôn ngữ chính, cũng có thể được sử dụng.
Tôi thấy việc sử dụng gói DBMS_CLOUD.send_request cho tất cả lệnh gọi dịch vụ OCI (ví dụ: thay vì các lệnh gọi SDK OCI cụ thể hơn như DBMS_CLOUD_OCI_AIV_AI_SERVICE_VISION) là cách tiếp cận đơn giản và năng động nhất.
Chúng tôi bắt đầu bằng cách tạo thông tin xác thực có thể được tham chiếu và sử dụng lại cho tất cả các cuộc gọi dịch vụ đám mây của chúng tôi và chỉ bao gồm thông tin từ tài khoản/cấu hình OCI của bạn.
BEGIN dbms_cloud.create_credential ( credential_name => 'OCI_KEY_CRED', user_ocid => 'ocid1.user.oc1..[youruserocid]', tenancy_ocid => 'ocid1.tenancy.oc1..[yourtenancyocid]', private_key => '[yourprivatekey - you can read this from file or put the contents of your pem without header, footer, and line wraps]' fingerprint => '[7f:yourfingerprint]' ); END;
Tiếp theo, trước khi xem chương trình/chức năng chính, chúng ta hãy xem nhanh bảng mà chúng ta sẽ lưu kết quả AI vào. Lưu ý, trong trường hợp này, bảng có các cột cho cả JSON từ lệnh gọi AI và văn bản trường được tạo từ các trường chính trong JSON để tham khảo nhanh, tìm kiếm, v.v.
Một lần nữa, các cấu trúc bảng, cách sử dụng SQL/quan hệ và JSON, v.v., đều có thể khác nhau và một lần nữa, đây là một ví dụ tuyệt vời về cơ sở dữ liệu đa năng của Oracle nơi bạn có thể sử dụng nhiều mô hình dữ liệu và kiểu dữ liệu khác nhau.
Ví dụ: tính năng JSON Duality trong cơ sở dữ liệu Oracle rất đáng để kiểm tra vì nó cho phép truy cập cùng một dữ liệu bằng cách sử dụng SQL/quan hệ cũng như API JSON và thậm chí cả MongoDB.
CREATE TABLE aivision_results (id RAW (16) NOT NULL, date_loaded TIMESTAMP WITH TIME ZONE, label varchar2(20), textfromai varchar2(32767), jsondata CLOB CONSTRAINT ensure_aivision_results_json CHECK (jsondata IS JSON)); /
Và bây giờ, hàm đơn giản tiêu biểu cho trọng tâm của kiến trúc… Ở đây, chúng ta thấy lệnh gọi tới DBMS_CLOUD.send_request với thông tin xác thực mà chúng ta đã tạo và URL của điểm cuối hoạt động dịch vụ (AI) (hoạt động analyzeImage của dịch vụ Oracle Vision AI trong trường hợp này).
Tải trọng JSON của nội dung bao gồm (các) tính năng của dịch vụ mà chúng tôi muốn sử dụng và bất kỳ cấu hình nào khác cũng như các đối số cho hoạt động, trong trường hợp này, bao gồm vị trí lưu trữ đối tượng của một hình ảnh (một cấu hình khác tùy chọn sẽ là cung cấp trực tiếp/nội tuyến mảng byte hình ảnh như một phần của tải trọng).
Sau đó, kết quả JSON được truy xuất từ phản hồi, một số thành phần nhất định của kết quả đó được phân tích cú pháp thành trường văn bản để thuận tiện và JSON, văn bản, v.v., được duy trì như đã đề cập trước đó.
CREATE OR REPLACE FUNCTION VISIONAI_TEXTDETECTION ( p_endpoint VARCHAR2, p_compartment_ocid VARCHAR2, p_namespaceName VARCHAR2, p_bucketName VARCHAR2, p_objectName VARCHAR2, p_featureType VARCHAR2, p_label VARCHAR2 ) RETURN VARCHAR2 IS resp DBMS_CLOUD_TYPES.resp; json_response CLOB; v_textfromai VARCHAR2(32767); BEGIN resp := DBMS_CLOUD.send_request( credential_name => 'OCI_KEY_CRED', uri => p_endpoint || '/20220125/actions/analyzeImage', method => 'POST', body => UTL_RAW.cast_to_raw( JSON_OBJECT( 'features' VALUE JSON_ARRAY( JSON_OBJECT('featureType' VALUE p_featureType) ), 'image' VALUE JSON_OBJECT( 'source' VALUE 'OBJECT_STORAGE', 'namespaceName' VALUE p_namespaceName, 'bucketName' VALUE p_bucketName, 'objectName' VALUE p_objectName ), 'compartmentId' VALUE p_compartment_ocid ) ) ); json_response := DBMS_CLOUD.get_response_text(resp); SELECT LISTAGG(text, ', ') WITHIN GROUP (ORDER BY ROWNUM) INTO v_textfromai FROM JSON_TABLE(json_response, '$.imageText.words[*]' COLUMNS ( text VARCHAR2(100) PATH '$.text' ) ); INSERT INTO aivision_results (id, date_loaded, label, textfromai, jsondata) VALUES (SYS_GUID(), SYSTIMESTAMP, p_label, v_textfromai, json_response); RETURN v_textfromai; EXCEPTION WHEN OTHERS THEN RAISE; END VISIONAI_TEXTDETECTION; /
Chúng ta cũng có thể hiển thị hàm dưới dạng điểm cuối Rest theo chương trình bằng cách sử dụng như sau:
BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_OBJECTDETECTION', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_OBJECTDETECTION', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /Phân tích và tìm kiếm văn bản của kết quả AI
Kiến trúc này cũng giúp việc phân tích và tìm kiếm văn bản của tất cả các kết quả AI trở nên thuận tiện và hiệu quả. Từ đây, nhiều quá trình xử lý và phân tích hơn có thể diễn ra. Chúng ta hãy xem ba tuyên bố sẽ cung cấp cho chúng ta khả năng tìm kiếm văn bản dễ sử dụng cho các kết quả AI của chúng ta.
- Đầu tiên, chúng tôi tạo chỉ mục cho tìm kiếm văn bản trên bảng aivision_results .
- Sau đó, chúng ta tạo một hàm tìm kiếm một chuỗi nhất định bằng cách sử dụng chức năng chứa mạnh mẽ hoặc chúng ta có thể bổ sung/tùy chọn sử dụng gói DBMS_SEARCH để tìm kiếm nhiều bảng và trả về hàm giới thiệu kết quả.
- Cuối cùng, chúng tôi hiển thị hàm dưới dạng điểm cuối Rest.
Nó đơn giản mà.
create index aivisionresultsindex on aivision_results(textfromai) indextype is ctxsys.context; / CREATE OR REPLACE FUNCTION VISIONAI_RESULTS_TEXT_SEARCH(p_sql IN VARCHAR2) RETURN SYS_REFCURSOR AS refcursor SYS_REFCURSOR; BEGIN OPEN refcursor FOR select textfromai from AIVISION_RESULTS where contains ( textfromai, p_sql ) > 0; RETURN refcursor; END VISIONAI_RESULTS_TEXT_SEARCH; / BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_RESULTS_TEXT_SEARCH', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_RESULTS_TEXT_SEARCH', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /Tóm lại là…
Đây là một blog ngắn trình bày mẫu kiến trúc để phát triển Ứng dụng AI dựa trên dữ liệu bằng cách thực hiện lệnh gọi đến các dịch vụ AI trực tiếp từ cơ sở dữ liệu.
Cảm ơn bạn rất nhiều vì đã đọc và vui lòng cho tôi biết nếu bạn có bất kỳ câu hỏi hoặc phản hồi nào.
Cũng được xuất bản ở đây








