






















tác giả:
(1) Yikuan Li, MS, Trường Y khoa Feinberg thuộc Đại học Tây Bắc & Giải pháp Y tế của Siemens;
(2) Hanyin Wang, BMed, Trường Y Feinberg thuộc Đại học Tây Bắc;
(3) Halid Z. Yerebakan, Tiến sĩ, Giải pháp Y tế của Siemens;
(4) Yoshihisa Shinagawa, Tiến sĩ, Giải pháp Y tế của Siemens;
(5) Yuan Luo, Tiến sĩ, FAMIA, Trường Y Feinberg thuộc Đại học Tây Bắc.
Bảng liên kết
Giới thiệu
Việc tích hợp và trao đổi dữ liệu sức khỏe trên các nền tảng và hệ thống khác nhau vẫn còn nhiều thách thức do thiếu các định dạng chuẩn hóa và hiểu biết ngữ nghĩa chung. Thách thức này trở nên quan trọng hơn khi thông tin sức khỏe quan trọng được nhúng vào dữ liệu phi cấu trúc thay vì các định dạng có cấu trúc được tổ chức tốt. Việc chuẩn hóa dữ liệu sức khỏe phi cấu trúc, chẳng hạn như ghi chú lâm sàng, thành tài nguyên FHIR có thể làm giảm bớt sự mơ hồ giữa các nhà cung cấp dịch vụ y tế khác nhau và do đó, cải thiện khả năng tương tác. Tuy nhiên, đó không phải là một nhiệm vụ dễ dàng. Các nghiên cứu trước đây 1.2 đã cố gắng chuyển đổi các ghi chú lâm sàng thành tài nguyên FHIR bằng cách sử dụng kết hợp các công cụ xử lý ngôn ngữ tự nhiên và máy học thông qua các quy trình gồm nhiều bước liên quan đến nhận dạng thực thể có tên lâm sàng, mã hóa thuật ngữ, tính toán toán học, định dạng cấu trúc và hiệu chuẩn của con người. Tuy nhiên, những cách tiếp cận này đòi hỏi nỗ lực bổ sung của con người để tổng hợp kết quả từ nhiều công cụ và chỉ đạt được hiệu suất vừa phải, với điểm F1 dao động từ 0,7 đến 0,9 ở các yếu tố khác nhau. Để đạt được mục tiêu này, chúng tôi dự định khai thác Mô hình ngôn ngữ lớn (LLM) để trực tiếp tạo ra các tài nguyên có định dạng FHIR từ kiểu nhập văn bản tự do. Việc sử dụng LLM dự kiến sẽ đơn giản hóa các quy trình gồm nhiều bước trước đây, nâng cao hiệu quả và độ chính xác của việc tạo tài nguyên FHIR tự động và cuối cùng là cải thiện khả năng tương tác dữ liệu sức khỏe.
phương pháp
Chú thích dữ liệu Theo hiểu biết tốt nhất của chúng tôi, không có tập dữ liệu nào có sẵn công khai rộng rãi trong tiêu chuẩn FHIR được tạo từ dữ liệu theo ngữ cảnh. Do đó, chúng tôi đã chọn chú thích một tập dữ liệu chứa cả đầu vào văn bản tự do và đầu ra có cấu trúc ở định dạng FHIR. Đầu vào văn bản tự do được lấy từ bản tóm tắt lưu lượng của cơ sở dữ liệu MIMICIII. 3 Nhờ thử thách trích xuất thuốc n2c2 năm 2018 4, về cơ bản bao gồm các nhiệm vụ nhận dạng thực thể được đặt tên, các thành phần trong báo cáo thuốc đã được xác định. Các chú thích của chúng tôi được xây dựng dựa trên các chú thích n2c2 này và chuẩn hóa văn bản tự do thành nhiều hệ thống mã hóa thuật ngữ lâm sàng, chẳng hạn như NDC, RxNorm và SNOMED. Chúng tôi đã sắp xếp các bối cảnh và mã thành các tài nguyên Tuyên bố về thuốc của FHIR. Các tài nguyên FHIR đã chuyển đổi đã được trình xác thực FHIR chính thức (https://validator.fhir.org/) xác thực để đảm bảo tuân thủ các tiêu chuẩn FHIR, bao gồm cấu trúc, kiểu dữ liệu, bộ mã, tên hiển thị, v.v. Những kết quả được xác thực này được coi là kết quả chuyển đổi tiêu chuẩn vàng và có thể được sử dụng để kiểm tra LLM. Không có mối lo ngại nào về mặt đạo đức liên quan đến việc sử dụng dữ liệu vì cả bộ dữ liệu MIMIC và n2c2 đều được cung cấp công khai cho người dùng được ủy quyền.
Mô hình ngôn ngữ lớn Chúng tôi đã sử dụng mô hình GPT-4 của OpenAI làm LLM để chuyển đổi định dạng FHIR. Chúng tôi đã sử dụng năm lời nhắc riêng biệt để hướng dẫn LLM chuyển đổi văn bản miễn phí đầu vào thành thuốc (bao gồm Mã thuốc, hàm lượng và dạng), đường dùng, lịch trình, liều lượng và lý do tương ứng. Tất cả lời nhắc đều tuân theo một mẫu có cấu trúc sau: hướng dẫn tác vụ, mẫu FHIR đầu ra dự kiến ở định dạng .JSON, 4-5 ví dụ chuyển đổi, danh sách toàn diện các mã mà mô hình có thể thực hiện lựa chọn và sau đó là văn bản đầu vào. Vì không có sự tinh chỉnh hoặc điều chỉnh theo miền cụ thể trong các thử nghiệm của chúng tôi nên ban đầu chúng tôi yêu cầu LLM tạo một tập hợp con nhỏ (N=100). Sau đó, chúng tôi đã xem xét thủ công những khác biệt giữa đầu ra FHIR do LLM tạo và các chú thích do con người thực hiện. Những lỗi phổ biến đã được xác định và sử dụng để tinh chỉnh các lời nhắc. Điều quan trọng cần lưu ý là chúng tôi không có quyền truy cập vào toàn bộ danh sách mã Thuốc NDC, RxNorm và SNOMED cho tên thuốc cũng như mã Tìm kiếm SNOMED vì lý do. Ngoài ra, ngay cả khi chúng tôi có danh sách toàn diện như vậy, chúng vẫn sẽ vượt quá giới hạn mã thông báo cho LLM. Vì vậy, chúng tôi không giao nhiệm vụ LLM mã hóa các thực thể này; thay vào đó, chúng tôi hướng dẫn họ xác định các ngữ cảnh được đề cập trong văn bản đầu vào. Đối với các yếu tố khác, ví dụ như các tuyến và dạng ma túy, được đánh số hàng trăm, chúng tôi cho phép LLM trực tiếp mã hóa chúng. Khi đánh giá đầu ra do LLM tạo, tiêu chí chính của chúng tôi là tỷ lệ khớp chính xác, đòi hỏi phải căn chỉnh chính xác với chú thích của con người ở mọi khía cạnh, bao gồm mã, cấu trúc, v.v. Ngoài ra, chúng tôi đã báo cáo điểm chính xác, thu hồi và F1 cho các lần xuất hiện phần tử cụ thể. Chúng tôi đã truy cập API GPT-4 thông qua dịch vụ Azure OpenAI, tuân thủ các nguyên tắc sử dụng có trách nhiệm đối với dữ liệu MIMIC. Mẫu cụ thể mà chúng tôi sử dụng là 'gpt-4-32k' trong phiên bản '2023-05-15'. Mỗi đầu vào văn bản được chuyển đổi riêng lẻ thành tài nguyên DrugStatement. Để tối ưu hóa hiệu quả, chúng tôi đã thực hiện nhiều lệnh gọi API không đồng bộ.

Kết quả và thảo luận
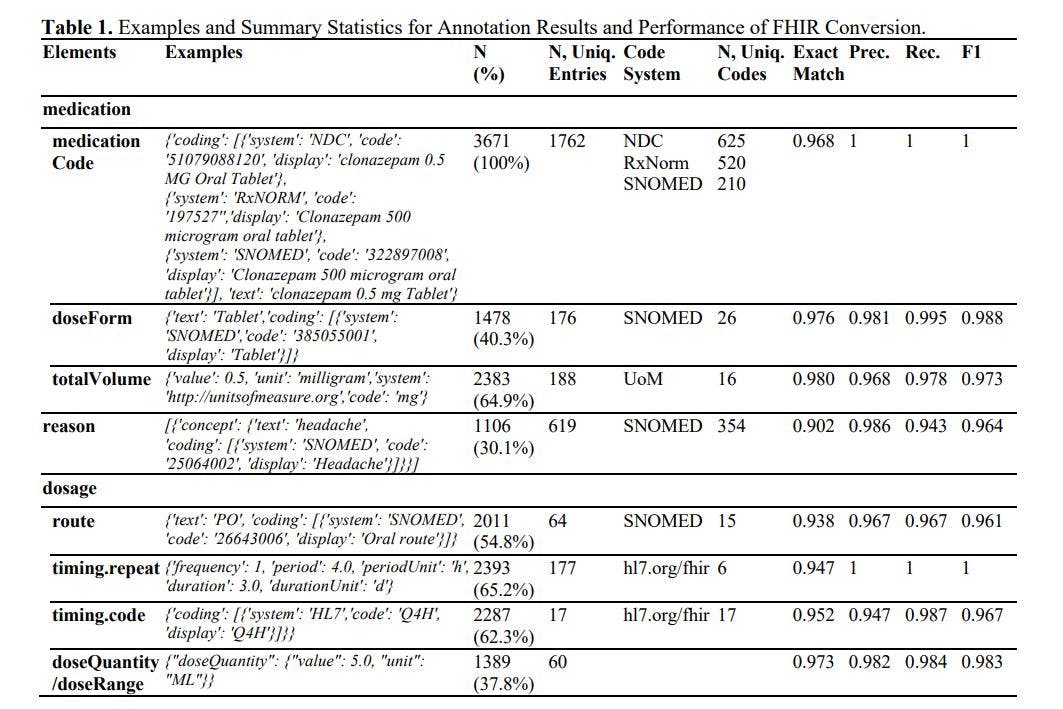
Kết quả chú thích và tạo FHIR được trình bày trong Bảng 1. Tóm lại, chúng tôi đã chú thích 3.671 nguồn thuốc, bao gồm hơn 625 loại thuốc riêng biệt và liên quan đến 354 lý do. Mô hình Ngôn ngữ Lớn (LLM) đạt được tỷ lệ chính xác ấn tượng trên 90% và điểm F1 vượt quá 0,96 trên tất cả các yếu tố. Trong các nghiên cứu trước đây, điểm F1 đạt 0,750 ở thời gian.repeat, 0,878 ở thời gian.route và 0,899 ở liều lượng thời gian. 1 LLM đã cải thiện các điểm F1 này ít nhất 8%. Điều đáng chú ý là các nghiên cứu trước đây đã sử dụng tập dữ liệu riêng tư nhỏ hơn, không sử dụng các số liệu đánh giá nghiêm ngặt nhất như tỷ lệ khớp chính xác, bỏ qua mã hóa thuật ngữ và yêu cầu đào tạo chuyên sâu. Khi điều tra sâu hơn, chúng tôi cũng bị ấn tượng bởi độ chính xác cao trong mã hóa thuật ngữ (về cơ bản liên quan đến nhiệm vụ phân loại với hơn 100 lớp), chuyển đổi toán học (ví dụ: suy ra khoảng thời gian 10 ngày khi đầu vào đề cập đến 'TID, phân phối 30 viên '), sự tuân thủ về định dạng (với ít hơn 0,3% khả năng kết quả không thể diễn giải ở định dạng .JSON) và số lượng (LLM có thể xử lý cả hai mối quan hệ 1:N và 1:1).
Độ chính xác của đầu ra phụ thuộc nhiều vào lời nhắc hướng dẫn được sử dụng. Dựa trên các thử nghiệm và sai sót sâu rộng của chúng tôi, chúng tôi có các đề xuất sau: i) cung cấp các ví dụ chuyển đổi đa dạng bao gồm nhiều trường hợp biên không đồng nhất; ii) sử dụng ngôn ngữ mạnh mẽ, chẳng hạn như “PHẢI”, để đảm bảo rằng đầu ra tuân thủ các định dạng và nguyên tắc dự kiến; iii) liên tục cập nhật và tinh chỉnh các lời nhắc bằng cách xem xét kết quả từ một nhóm nhỏ, điều này có thể giúp xác định các lỗi phổ biến và nâng cao độ chính xác tổng thể; iv) hãy thận trọng với việc mã hóa ngoài từ vựng. LLM có thể cố gắng phục vụ người dùng bằng cách phát minh ra các mã không tồn tại khi họ không thể tìm thấy mã phù hợp.
Phần kết luận
Trong nghiên cứu này, chúng tôi đã cung cấp nền tảng tận dụng LLM để nâng cao khả năng tương tác dữ liệu sức khỏe bằng cách chuyển đổi kiểu nhập văn bản tự do thành tài nguyên FHIR. Các nghiên cứu trong tương lai sẽ nhằm mục đích phát huy những thành công này bằng cách mở rộng thế hệ sang các tài nguyên FHIR bổ sung và so sánh hiệu suất của các mô hình LLM khác nhau.
Thẩm quyền giải quyết
1. Hong N, Wen A, Shen F, Sohn S, Liu S, Liu H, Jiang G. Tích hợp dữ liệu EHR có cấu trúc và không cấu trúc bằng hệ thống loại dựa trên FHIR: nghiên cứu điển hình với dữ liệu thuốc. Hội nghị thượng đỉnh AMIA về Kỷ yếu Khoa học Dịch thuật. 2018;2018:74.
2. Hong N, Wen A, Shen F, Sohn S, Wang C, Liu H, Jiang G. Phát triển quy trình chuẩn hóa dữ liệu lâm sàng dựa trên FHIR có thể mở rộng để chuẩn hóa và tích hợp dữ liệu hồ sơ sức khỏe điện tử có cấu trúc và phi cấu trúc. JAMIA mở. Tháng 12 năm 2019;2(4):570-9.
3. Johnson AE, Pollard TJ, Shen L, Lehman LW, Feng M, Ghassemi M, Moody B, Szolovits P, Anthony Celi L, Mark RG. MIMIC-III, cơ sở dữ liệu chăm sóc quan trọng có thể truy cập miễn phí. Dữ liệu khoa học. 2016 24 tháng 5;3(1):1-9.
4. Henry S, Buchan K, Filannino M, Stubbs A, Uzuner O. 2018 n2c2 đã chia sẻ nhiệm vụ về các tác dụng phụ của thuốc và trích xuất thuốc trong hồ sơ sức khỏe điện tử. Tạp chí của Hiệp hội Tin học Y tế Hoa Kỳ. 2020 tháng 1;27(1):3-12.
Bài viết này có sẵn trên arxiv theo giấy phép CC 4.0.








