






















Yazarlar:
(1) Yikuan Li, MS, Northwestern Üniversitesi Feinberg Tıp Fakültesi ve Siemens Tıbbi Çözümler;
(2) Hanyin Wang, BMed, Northwestern Üniversitesi Feinberg Tıp Fakültesi;
(3) Halid Z. Yerebakan, PhD, Siemens Medical Solutions;
(4) Yoshihisa Shinagawa, PhD, Siemens Medikal Çözümler;
(5) Yuan Luo, PhD, FAMIA, Northwestern Üniversitesi Feinberg Tıp Fakültesi.
Bağlantı Tablosu
giriiş
Sağlık verilerinin farklı platformlar ve sistemler arasında entegrasyonu ve değişimi, standartlaştırılmış formatların ve ortak bir anlamsal anlayışın bulunmaması nedeniyle zorlu olmaya devam ediyor. Kritik sağlık bilgileri iyi organize edilmiş yapılandırılmış formatlar yerine yapılandırılmamış verilere yerleştirildiğinde bu zorluk daha da önemli hale gelir. Klinik notlar gibi yapılandırılmamış sağlık verilerinin FHIR kaynaklarında standartlaştırılması, farklı sağlık sağlayıcıları arasındaki belirsizliği azaltabilir ve dolayısıyla birlikte çalışabilirliği artırabilir. Ancak bu hiç de kolay bir iş değildir. Önceki çalışmalar1,2, klinik adlandırılmış varlık tanıma, terminoloji kodlaması, matematiksel hesaplamalar, yapısal biçimlendirme ve insan kalibrasyonlarını içeren çok adımlı süreçler yoluyla doğal dil işleme ve makine öğrenimi araçlarının bir kombinasyonunu kullanarak klinik notları FHIR kaynaklarına dönüştürmeye çalışmıştır. Ancak bu yaklaşımlar, birden fazla araçtan elde edilen sonuçları birleştirmek için ek insan çabası gerektirir ve farklı unsurlarda 0,7 ila 0,9 arasında değişen F1 puanlarıyla yalnızca orta düzey performanslar elde edebilmiştir. Bu amaçla, serbest metin girişinden doğrudan FHIR formatlı kaynaklar oluşturmak için Büyük Dil Modellerinden (LLM'ler) yararlanmayı amaçlıyoruz. LLM'lerin kullanımının daha önce çok adımlı süreçleri basitleştirmesi, otomatik FHIR kaynak üretiminin verimliliğini ve doğruluğunu artırması ve sonuçta sağlık verilerinin birlikte çalışabilirliğini geliştirmesi bekleniyor.
Yöntemler
Veri Açıklaması Bildiğimiz kadarıyla, FHIR standardında bağlamsal verilerden oluşturulan, büyük ölçüde kamuya açık bir veri kümesi bulunmamaktadır. Bu nedenle, hem serbest metin girişi hem de FHIR formatlarında yapılandırılmış çıktı içeren bir veri kümesine açıklama eklemeyi seçtik. Serbest metin girişi, MIMICIII veri tabanının yayın özetlerinden türetilmiştir. 3 Temel olarak adlandırılmış varlık tanıma görevlerini içeren 2018 n2c2 ilaç çıkarma mücadelesi 4 sayesinde, ilaç beyanlarındaki öğeler belirlendi. Ek açıklamalarımız bu n2c2 ek açıklamalarını temel aldı ve serbest metni NDC, RxNorm ve SNOMED gibi birden fazla klinik terminoloji kodlama sistemiyle standartlaştırdı. İçerikleri ve kodları FHIR ilaç beyanı kaynakları halinde düzenledik. Dönüştürülen FHIR kaynakları, yapı, veri türü, kod kümeleri, görünen adlar ve daha fazlası dahil olmak üzere FHIR standartlarına uygunluğu sağlamak için resmi FHIR doğrulayıcısı (https://validator.fhir.org/) tarafından doğrulandı. Bu doğrulanmış sonuçlar, altın standart dönüşüm sonuçları olarak kabul edildi ve LLM'lere karşı test yapmak için kullanılabilir. Hem MIMIC hem de n2c2 veri kümeleri yetkili kullanıcıların kullanımına açık olduğundan, veri kullanımıyla ilgili herhangi bir etik kaygı mevcut değildir.
Büyük Dil Modeli FHIR format dönüşümü için LLM olarak OpenAI'nin GPT-4 modelini kullandık. Yüksek Lisans'a girdi serbest metnini ilaca (ilaç kodu, güç ve form dahil), rotaya, programa, dozaja ve nedene dönüştürme talimatı vermek için beş ayrı komut kullandık. Tüm istemler aşağıdaki yapıya sahip bir şablona bağlıydı: görev talimatları, .JSON formatında beklenen çıktı FHIR şablonları, 4-5 dönüşüm örneği, modelin seçim yapabileceği kapsamlı bir kod listesi ve ardından giriş metni. Deneylerimizde ince ayar veya alana özgü uyarlama olmadığından, başlangıçta LLM'nin küçük bir alt küme (N=100) oluşturmasını sağladık. Ardından, LLM tarafından oluşturulan FHIR çıktısı ile insan ek açıklamalarımız arasındaki tutarsızlıkları manuel olarak inceledik. Yaygın hatalar belirlendi ve istemleri iyileştirmek için kullanıldı. İlaç adlarına ilişkin NDC, RxNorm ve SNOMED İlaç kodlarının tam listesine ve ayrıca SNOMED Bulma kodlarına nedenlerden dolayı erişimimizin olmadığını belirtmek önemlidir. Ayrıca bu kadar kapsamlı listelerimiz olsa bile LLM'lerin token limitlerini aşmış olacaklardı. Bu nedenle, Yüksek Lisans'lara bu varlıkları kodlama görevi vermedik; bunun yerine onlara giriş metninde bahsedilen bağlamları tanımlamaları talimatını verdik. Yüzlerce sayıdaki ilaç yolları ve formları gibi diğer unsurlar için, Yüksek Lisans'ların bunları doğrudan kodlamasına izin verdik. Yüksek Lisans tarafından oluşturulan çıktıyı değerlendirirken birincil kriterimiz, kodlar, yapılar ve daha fazlası dahil olmak üzere her açıdan insan açıklamalarıyla hassas bir şekilde hizalanmayı gerektiren tam eşleşme oranıydı. Ek olarak belirli element oluşumları için kesinlik, hatırlama ve F1 puanlarını da bildirdik. MIMIC verilerine yönelik sorumlu kullanım yönergelerine uygun olarak GPT-4 API'lerine Azure OpenAI hizmeti aracılığıyla eriştik. Kullandığımız spesifik model '2023-05-15' versiyonundaki 'gpt-4-32k' idi. Her metin girişi ayrı ayrı bir MedicationStatement kaynağına dönüştürüldü. Verimliliği optimize etmek için birden fazla eşzamansız API çağrısı yaptık.

Sonuçlar ve tartışmalar
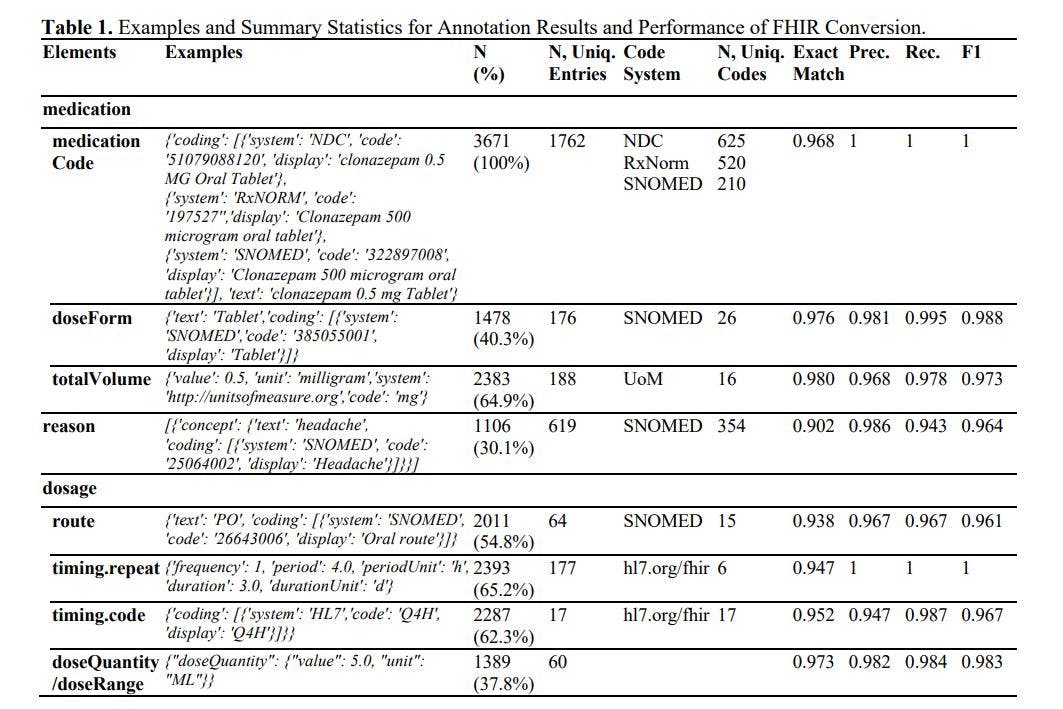
Ek açıklama ve FHIR oluşturmanın sonuçları Tablo 1'de sunulmaktadır. Özetle, 625'ten fazla farklı ilacı kapsayan ve 354 nedenle ilişkilendirilen 3.671 ilaç kaynağına açıklama ekledik. Büyük Dil Modeli (LLM), %90'ın üzerinde etkileyici bir doğruluk oranına ve tüm öğelerde 0,96'yı aşan bir F1 puanına ulaştı. Daha önceki çalışmalarda F1 puanları zamanlama tekrarında 0,750'ye, zamanlama rotasında 0,878'e ve zamanlama dozajında 0,899'a ulaşmıştı. 1 Yüksek Lisans bu F1 puanlarını en az %8 oranında artırdı. Önceki çalışmaların daha küçük bir özel veri seti kullandığını, tam eşleşme oranı gibi en katı değerlendirme ölçütlerini kullanmadığını, terminoloji kodlamasının atlandığını ve kapsamlı eğitim gerektirdiğini belirtmekte fayda var. Daha fazla araştırma yaptığımızda, terminoloji kodlamasındaki (esasen 100'den fazla sınıf içeren bir sınıflandırma görevini içeren) yüksek doğruluktan ve matematiksel dönüşümden (örneğin, girdide 'TID, 30 tablet dağıtın' dendiğinde 10 günlük bir sürenin çıkarımı) etkilendik. '), format uygunluğu (sonuçların .JSON formatında yorumlanamaması ihtimali %0,3'ten az) ve önem (LLM hem 1:N hem de 1:1 ilişkileri işleyebilir).
Çıktının doğruluğu büyük ölçüde kullanılan talimat istemlerine bağlıdır. Kapsamlı deneme ve hatalarımıza dayanarak aşağıdaki önerilerimiz var: i) çok çeşitli heterojen uç durumları kapsayan çeşitli dönüşüm örnekleri sağlamak; ii) çıktının beklenen formatlara ve kurallara uygun olmasını sağlamak için "ZORUNLU" gibi güçlü bir dil kullanın; iii) küçük bir alt kümeden elde edilen sonuçları inceleyerek istemleri sürekli olarak güncelleyin ve iyileştirin; bu, yaygın hataların belirlenmesine ve genel doğruluğun artırılmasına yardımcı olabilir; iv) sözlük dışı kodlamalara karşı dikkatli olun. Yüksek Lisans'lar, yakın bir eşleşme bulamadıklarında, mevcut olmayan kodları icat ederek kullanıcılara hitap etmeye çalışabilirler.
Çözüm
Bu çalışmada, serbest metin girişini FHIR kaynaklarına dönüştürerek sağlık verilerinin birlikte çalışabilirliğini geliştirmek için Yüksek Lisans'lardan yararlanmanın temellerini sağladık. Gelecekteki çalışmalar, nesli ek FHIR kaynaklarına genişleterek ve çeşitli LLM modellerinin performansını karşılaştırarak bu başarıların üzerine inşa etmeyi amaçlayacaktır.
Referans
1. Hong N, Wen A, Shen F, Sohn S, Liu S, Liu H, Jiang G. Yapılandırılmış ve yapılandırılmamış EHR verilerinin FHIR tabanlı bir sistem kullanılarak entegre edilmesi: ilaç verileriyle bir vaka çalışması. AMIA Çeviri Bilimi Bildirileri Zirveleri. 2018;2018:74.
2. Hong N, Wen A, Shen F, Sohn S, Wang C, Liu H, Jiang G. Yapılandırılmamış ve yapılandırılmış elektronik sağlık kaydı verilerini standartlaştırmak ve entegre etmek için ölçeklenebilir bir FHIR tabanlı klinik veri normalleştirme hattının geliştirilmesi. JAMIA açık. 2019 Aralık;2(4):570-9.
3. Johnson AE, Pollard TJ, Shen L, Lehman LW, Feng M, Ghassemi M, Moody B, Szolovits P, Anthony Celi L, Mark RG. MIMIC-III, ücretsiz olarak erişilebilen bir kritik bakım veritabanıdır. Bilimsel veriler. 2016 Mayıs 24;3(1):1-9.
4. Henry S, Buchan K, Filannino M, Stubbs A, Uzuner O. 2018 n2c2, olumsuz ilaç olayları ve elektronik sağlık kayıtlarından ilaç çıkarma konusunda görev paylaştı. Amerikan Tıp Bilişimi Derneği Dergisi. 2020 Oca;27(1):3-12.
Bu makale arxiv'de CC 4.0 lisansı altında mevcuttur.








