






















लेखक:
(1) यिकुआन ली, एमएस, नॉर्थवेस्टर्न यूनिवर्सिटी फीनबर्ग स्कूल ऑफ मेडिसिन और सीमेंस मेडिकल सॉल्यूशंस;
(2) हन्यिन वांग, बीएमड, नॉर्थवेस्टर्न यूनिवर्सिटी फीनबर्ग स्कूल ऑफ मेडिसिन;
(3) हालिद जेड. येरेबाकन, पीएचडी, सीमेंस मेडिकल सॉल्यूशंस;
(4) योशीहिसा शिनागावा, पीएचडी, सीमेंस मेडिकल सॉल्यूशंस;
(5) युआन लुओ, पीएचडी, एफएएमआईए, नॉर्थवेस्टर्न यूनिवर्सिटी फीनबर्ग स्कूल ऑफ मेडिसिन।
लिंक की तालिका
परिचय
मानकीकृत प्रारूपों और साझा अर्थपूर्ण समझ की अनुपस्थिति के कारण विविध प्लेटफ़ॉर्म और सिस्टम में स्वास्थ्य डेटा का एकीकरण और आदान-प्रदान चुनौतीपूर्ण बना हुआ है। यह चुनौती तब और भी महत्वपूर्ण हो जाती है जब महत्वपूर्ण स्वास्थ्य जानकारी सुव्यवस्थित संरचित प्रारूपों के बजाय असंरचित डेटा में अंतर्निहित होती है। FHIR संसाधनों में नैदानिक नोट्स जैसे असंरचित स्वास्थ्य डेटा को मानकीकृत करने से विभिन्न स्वास्थ्य प्रदाताओं के बीच अस्पष्टता कम हो सकती है और इसलिए, अंतर-संचालन में सुधार हो सकता है। हालाँकि, यह किसी भी तरह से आसान काम नहीं है। पिछले अध्ययनों 1,2 ने नैदानिक नामित इकाई पहचान, शब्दावली कोडिंग, गणितीय गणना, संरचनात्मक स्वरूपण और मानव अंशांकन से जुड़ी बहु-चरणीय प्रक्रियाओं के माध्यम से प्राकृतिक भाषा प्रसंस्करण और मशीन लर्निंग टूल के संयोजन का उपयोग करके नैदानिक नोट्स को FHIR संसाधनों में बदलने का प्रयास किया है। हालाँकि, इन तरीकों को कई उपकरणों से परिणामों को समेकित करने के लिए अतिरिक्त मानवीय प्रयास की आवश्यकता होती है और विभिन्न तत्वों में F1 स्कोर 0.7 से 0.9 तक होने के साथ केवल मध्यम प्रदर्शन प्राप्त हुआ है। इस उद्देश्य के लिए, हम मुक्त-पाठ इनपुट से सीधे FHIR-स्वरूपित संसाधन उत्पन्न करने के लिए बड़े भाषा मॉडल (LLM) का उपयोग करने का इरादा रखते हैं। एलएलएम के उपयोग से पहले की बहु-चरणीय प्रक्रियाओं को सरल बनाने, स्वचालित एफएचआईआर संसाधन निर्माण की दक्षता और सटीकता को बढ़ाने और अंततः स्वास्थ्य डेटा अंतर-संचालन में सुधार होने की उम्मीद है।
तरीकों
डेटा एनोटेशन हमारी सर्वोत्तम जानकारी के अनुसार, FHIR मानक में कोई भी सार्वजनिक रूप से उपलब्ध डेटासेट नहीं है जो प्रासंगिक डेटा से उत्पन्न होता है। इसलिए, हमने FHIR प्रारूपों में मुक्त-पाठ इनपुट और संरचित आउटपुट दोनों वाले डेटासेट को एनोटेट करना चुना है। मुक्त-पाठ इनपुट MIMICIII डेटासे के डिस्चार्ज सारांश से प्राप्त किया गया था। 3 2018 n2c2 दवा निष्कर्षण चुनौती 4 के लिए धन्यवाद, जिसमें अनिवार्य रूप से नामित इकाई पहचान कार्य शामिल हैं, दवा बयानों में तत्वों की पहचान की गई है। हमारे एनोटेशन इन n2c2 एनोटेशन पर बने और मुक्त पाठ को कई नैदानिक शब्दावली कोडिंग प्रणालियों, जैसे NDC, RxNorm, और SNOMED में मानकीकृत किया। हमने संदर्भों और कोडों को FHIR दवा विवरण संसाधनों में व्यवस्थित किया। परिवर्तित FHIR संसाधनों ने आधिकारिक FHIR सत्यापनकर्ता (https://validator.fhir.org/) द्वारा सत्यापन किया इन मान्य परिणामों को स्वर्ण मानक परिवर्तन परिणाम माना गया और इनका उपयोग LLM के विरुद्ध परीक्षण के लिए किया जा सकता है। डेटा उपयोग के संबंध में कोई नैतिक चिंता मौजूद नहीं है, क्योंकि MIMIC और n2c2 डेटासेट दोनों ही अधिकृत उपयोगकर्ताओं के लिए सार्वजनिक रूप से उपलब्ध हैं।
लार्ज लैंग्वेज मॉडल हमने FHIR प्रारूप परिवर्तन के लिए LLM के रूप में OpenAI के GPT-4 मॉडल का उपयोग किया। हमने इनपुट मुक्त पाठ को क्रमशः दवा (दवा कोड, शक्ति और रूप सहित), मार्ग, अनुसूची, खुराक और कारण में बदलने के लिए LLM को निर्देश देने के लिए पाँच अलग-अलग संकेतों का उपयोग किया। सभी संकेत निम्नलिखित संरचना वाले टेम्पलेट का पालन करते हैं: कार्य निर्देश, .JSON प्रारूप में अपेक्षित आउटपुट FHIR टेम्पलेट, 4-5 रूपांतरण उदाहरण, कोड की एक व्यापक सूची जिसमें से मॉडल चयन कर सकता है, और फिर इनपुट टेक्स्ट। चूंकि हमारे प्रयोगों में कोई फ़ाइनट्यूनिंग या डोमेन-विशिष्ट अनुकूलन नहीं था, इसलिए हमने शुरू में LLM को एक छोटा उपसमूह (N = 100) उत्पन्न करने दिया। फिर, हमने LLM द्वारा उत्पन्न FHIR आउटपुट और हमारे मानवीय एनोटेशन के बीच विसंगतियों की मैन्युअल रूप से समीक्षा की। सामान्य गलतियों की पहचान की गई और संकेतों को परिष्कृत करने के लिए उनका उपयोग किया गया। यह ध्यान रखना महत्वपूर्ण है कि हमारे पास दवा के नामों के लिए NDC, RxNorm और SNOMED मेडिकेशन कोड की पूरी सूची तक पहुँच नहीं थी, साथ ही कारणों के लिए SNOMED फाइंडिंग कोड भी नहीं थे। इसके अतिरिक्त, भले ही हमारे पास ऐसी व्यापक सूचियाँ होतीं, वे LLM के लिए टोकन सीमा को पार कर जातीं। इस प्रकार, हमने LLM को इन संस्थाओं को कोड करने का काम नहीं दिया; इसके बजाय, हमने उन्हें इनपुट टेक्स्ट में उल्लिखित संदर्भों की पहचान करने का निर्देश दिया। अन्य तत्वों के लिए, जैसे कि दवा के मार्ग और रूप, जिनकी संख्या सैकड़ों में है, हमने LLM को सीधे उन्हें कोड करने की अनुमति दी। LLM-जनरेटेड आउटपुट का मूल्यांकन करते समय, हमारा प्राथमिक मानदंड सटीक मिलान दर था, जो कोड, संरचनाओं और अधिक सहित सभी पहलुओं में मानव एनोटेशन के साथ सटीक संरेखण की आवश्यकता होती है। इसके अतिरिक्त, हमने विशिष्ट तत्व घटनाओं के लिए सटीकता, रिकॉल और F1 स्कोर की रिपोर्ट की। हमने MIMIC डेटा के लिए जिम्मेदार उपयोग दिशानिर्देशों के साथ संरेखित करते हुए, Azure OpenAI सेवा के माध्यम से GPT-4 API तक पहुँच प्राप्त की। हमने जिस विशिष्ट मॉडल का उपयोग किया वह 'gpt-4-32k' था, जो इसके '2023-05-15' संस्करण में था। प्रत्येक टेक्स्ट इनपुट को व्यक्तिगत रूप से एक मेडिकेशनस्टेटमेंट संसाधन में बदल दिया गया था। दक्षता को अनुकूलित करने के लिए, हमने कई एसिंक्रोनस API कॉल किए।

नतीजे और चर्चाएं
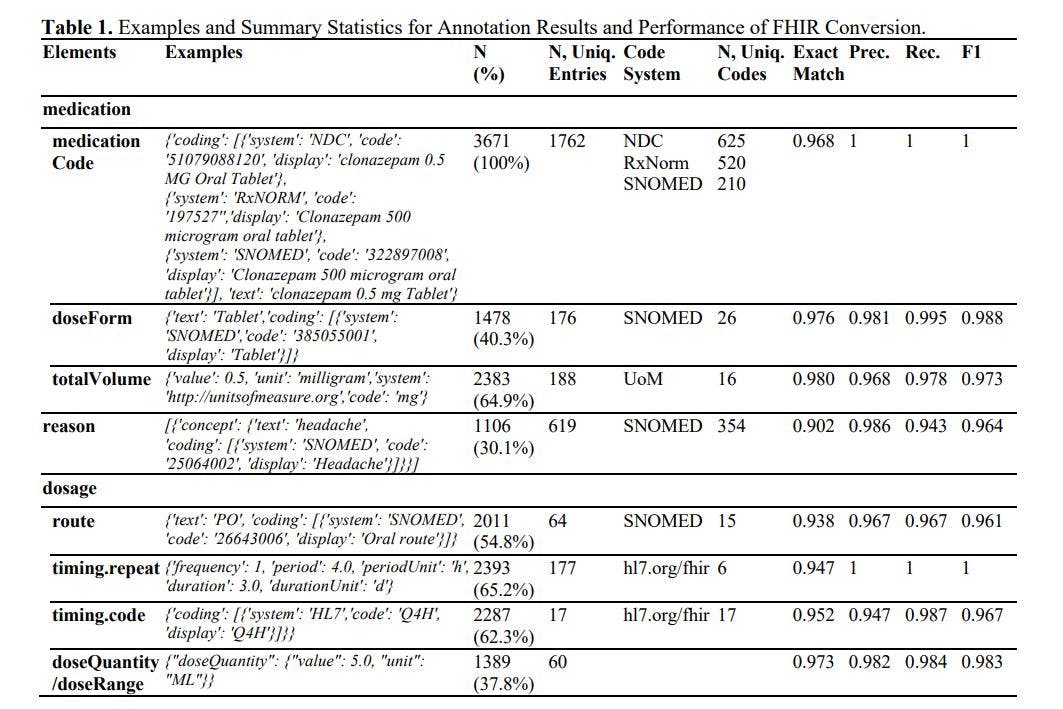
एनोटेशन और FHIR जेनरेशन के परिणाम तालिका 1 में प्रस्तुत किए गए हैं। संक्षेप में, हमने 3,671 दवा संसाधनों को एनोटेट किया, जिसमें 625 से अधिक अलग-अलग दवाएँ शामिल थीं और 354 कारणों से जुड़ी थीं। लार्ज लैंग्वेज मॉडल (LLM) ने 90% से अधिक की प्रभावशाली सटीकता दर और सभी तत्वों में 0.96 से अधिक F1 स्कोर हासिल किया। पिछले अध्ययनों में, F1 स्कोर टाइमिंग.रिपीट में 0.750, टाइमिंग.रूट में 0.878 और टाइमिंग डोज़ में 0.899 तक पहुँच गया था। 1 LLM ने इन F1 स्कोर में कम से कम 8% का सुधार किया। यह ध्यान देने योग्य है कि पिछले अध्ययनों ने एक छोटे निजी डेटासेट का उपयोग किया था, सटीक मिलान दर, छोड़ी गई शब्दावली कोडिंग जैसे सख्त मूल्यांकन मीट्रिक को नियोजित नहीं किया था, और व्यापक प्रशिक्षण की आवश्यकता थी। आगे की जांच में, हम शब्दावली कोडिंग (जिसमें अनिवार्य रूप से 100 से अधिक वर्गों के साथ वर्गीकरण कार्य शामिल है), गणितीय रूपांतरण (उदाहरण के लिए, जब इनपुट में 'TID, 30 गोलियां वितरित करें' का उल्लेख होता है तो 10 दिनों की अवधि का अनुमान लगाना), प्रारूप अनुरूपता (0.3% से कम संभावना है कि परिणामों को .JSON प्रारूप में व्याख्या नहीं किया जा सकता है) और कार्डिनैलिटी (LLM 1:N और 1:1 दोनों संबंधों को संभाल सकता है) में उच्च सटीकता से भी प्रभावित हुए।
आउटपुट की सटीकता उपयोग किए गए निर्देश संकेतों पर अत्यधिक निर्भर है। हमारे व्यापक परीक्षणों और त्रुटियों के आधार पर, हमारे पास निम्नलिखित अनुशंसाएँ हैं: i) विविध रूपांतरण उदाहरण प्रदान करें जो विषम एज मामलों की एक विस्तृत श्रृंखला को शामिल करते हैं; ii) यह सुनिश्चित करने के लिए कि आउटपुट अपेक्षित प्रारूपों और परिणामों का पालन करता है, "अवश्य" जैसी मजबूत भाषा का उपयोग करें; iii) एक छोटे उपसमूह से परिणामों की समीक्षा करके संकेतों को लगातार अपडेट और परिष्कृत करें, जो सामान्य गलतियों की पहचान करने और समग्र सटीकता को बढ़ाने में मदद कर सकता है; iv) शब्दावली से बाहर कोडिंग के बारे में सतर्क रहें। LLM उपयोगकर्ताओं को ऐसे कोड का आविष्कार करके सेवा देने का प्रयास कर सकते हैं जो तब मौजूद नहीं होते जब उन्हें कोई करीबी मिलान नहीं मिल पाता।
निष्कर्ष
इस अध्ययन में, हमने फ्री-टेक्स्ट इनपुट को FHIR संसाधनों में बदलकर स्वास्थ्य डेटा इंटरऑपरेबिलिटी को बढ़ाने के लिए LLM का लाभ उठाने की नींव प्रदान की। भविष्य के अध्ययनों का उद्देश्य अतिरिक्त FHIR संसाधनों के उत्पादन को बढ़ाकर और विभिन्न LLM मॉडलों के प्रदर्शन की तुलना करके इन सफलताओं को आगे बढ़ाना होगा।
संदर्भ
1. हांग एन, वेन ए, शेन एफ, सोहन एस, लियू एस, लियू एच, जियांग जी. एफएचआईआर-आधारित प्रकार प्रणाली का उपयोग करके संरचित और असंरचित ईएचआर डेटा को एकीकृत करना: दवा डेटा के साथ एक केस स्टडी। एएमआईए समिट्स ऑन ट्रांसलेशनल साइंस प्रोसीडिंग्स। 2018;2018:74।
2. होंग एन, वेन ए, शेन एफ, सोहन एस, वांग सी, लियू एच, जियांग जी। असंरचित और संरचित इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड डेटा को मानकीकृत और एकीकृत करने के लिए एक स्केलेबल एफएचआईआर-आधारित नैदानिक डेटा सामान्यीकरण पाइपलाइन विकसित करना। जामिया ओपन। 2019 दिसंबर;2(4):570-9।
3. जॉनसन एई, पोलार्ड टीजे, शेन एल, लेहमैन एलडब्ल्यू, फेंग एम, घासेमी एम, मूडी बी, स्ज़ोलोविट्स पी, एंथनी सेली एल, मार्क आरजी। एमआईएमआईसी-III, एक स्वतंत्र रूप से सुलभ क्रिटिकल केयर डेटाबेस। वैज्ञानिक डेटा। 2016 मई 24;3(1):1-9।
4. हेनरी एस, बुकान के, फिलैनिनो एम, स्टब्स ए, उज़ुनर ओ. 2018 एन2सी2 इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड में प्रतिकूल दवा घटनाओं और दवा निष्कर्षण पर साझा कार्य। जर्नल ऑफ द अमेरिकन मेडिकल इंफॉर्मेटिक्स एसोसिएशन। 2020 जनवरी;27(1):3-12।
यह पेपर CC 4.0 लाइसेंस के अंतर्गत arxiv पर उपलब्ध है।








