






















লেখক:
(1) ইকুয়ান লি, এমএস, নর্থওয়েস্টার্ন ইউনিভার্সিটি ফেইনবার্গ স্কুল অফ মেডিসিন এবং সিমেন্স মেডিকেল সলিউশন;
(2) হ্যানিন ওয়াং, বিএমড, নর্থওয়েস্টার্ন ইউনিভার্সিটি ফেইনবার্গ স্কুল অফ মেডিসিন;
(3) Halid Z. Yerebakan, PhD, Siemens Medical Solutions;
(4) Yoshihisa Shinagawa, PhD, Siemens Medical Solutions;
(5) ইউয়ান লুও, পিএইচডি, ফ্যামিয়া, নর্থওয়েস্টার্ন ইউনিভার্সিটি ফেইনবার্গ স্কুল অফ মেডিসিন।
লিঙ্কের টেবিল
ভূমিকা
বিভিন্ন প্ল্যাটফর্ম এবং সিস্টেম জুড়ে স্বাস্থ্য তথ্যের একীকরণ এবং বিনিময় প্রমিত বিন্যাস এবং একটি ভাগ করা শব্দার্থিক বোঝাপড়ার অনুপস্থিতির কারণে চ্যালেঞ্জিং রয়ে গেছে। এই চ্যালেঞ্জ আরও তাৎপর্যপূর্ণ হয়ে ওঠে যখন জটিল স্বাস্থ্য তথ্য সুসংগঠিত কাঠামোগত বিন্যাসের পরিবর্তে অসংগঠিত ডেটাতে এম্বেড করা হয়। এফএইচআইআর সংস্থানগুলিতে ক্লিনিকাল নোটের মতো অসংগঠিত স্বাস্থ্য ডেটা মানককরণ বিভিন্ন স্বাস্থ্য সরবরাহকারীদের মধ্যে অস্পষ্টতা দূর করতে পারে এবং তাই, আন্তঃকার্যক্ষমতা উন্নত করতে পারে। যাইহোক, এটা কোনভাবেই সহজ কাজ নয়। পূর্ববর্তী অধ্যয়ন 1,2 ক্লিনিকাল নামযুক্ত সত্তা স্বীকৃতি, পরিভাষা কোডিং, গাণিতিক গণনা, কাঠামোগত বিন্যাস এবং মানব ক্রমাঙ্কন জড়িত বহু-পদক্ষেপ প্রক্রিয়ার মাধ্যমে প্রাকৃতিক ভাষা প্রক্রিয়াকরণ এবং মেশিন লার্নিং সরঞ্জামগুলির সংমিশ্রণ ব্যবহার করে ক্লিনিকাল নোটগুলিকে FHIR সম্পদে রূপান্তর করার চেষ্টা করেছে। যাইহোক, এই পন্থাগুলির জন্য একাধিক সরঞ্জাম থেকে ফলাফলগুলিকে একীভূত করার জন্য অতিরিক্ত মানবিক প্রচেষ্টার প্রয়োজন এবং বিভিন্ন উপাদানে 0.7 থেকে 0.9 পর্যন্ত F1 স্কোর সহ শুধুমাত্র মাঝারি পারফরম্যান্স অর্জন করেছে। এই লক্ষ্যে, আমরা বিনামূল্যে-টেক্সট ইনপুট থেকে সরাসরি FHIR-ফরম্যাটেড সংস্থান তৈরি করতে বড় ভাষা মডেল (LLMs) ব্যবহার করতে চাই। LLM-এর ব্যবহার পূর্ববর্তী বহু-পদক্ষেপ প্রক্রিয়াগুলিকে সহজতর করবে, স্বয়ংক্রিয় FHIR সংস্থান তৈরির দক্ষতা এবং নির্ভুলতা বাড়াবে এবং শেষ পর্যন্ত স্বাস্থ্য ডেটা আন্তঃকার্যক্ষমতা উন্নত করবে বলে আশা করা হচ্ছে।
পদ্ধতি
ডেটা টীকা আমাদের জ্ঞানের সর্বোত্তমভাবে, প্রাসঙ্গিক ডেটা থেকে তৈরি করা FHIR স্ট্যান্ডার্ডে কোনও সর্বজনীনভাবে উপলব্ধ ডেটাসেট নেই। তাই, আমরা FHIR ফরম্যাটে ফ্রি-টেক্সট ইনপুট এবং স্ট্রাকচার্ড আউটপুট উভয়ই সমন্বিত একটি ডেটাসেট টীকা করতে বেছে নিয়েছি। ফ্রি-টেক্সট ইনপুটটি MIMICIII ডেটাসের ডিসচার্জ সারাংশ থেকে নেওয়া হয়েছে। 3 2018 n2c2 ওষুধ নিষ্কাশন চ্যালেঞ্জ 4 এর জন্য ধন্যবাদ, যা মূলত নামযুক্ত সত্তা স্বীকৃতির কাজগুলিকে জড়িত করে, ওষুধের বিবৃতিতে উপাদানগুলি চিহ্নিত করা হয়েছে। আমাদের টীকাগুলি এই n2c2 টীকাগুলির উপর নির্মিত এবং বিনামূল্যে পাঠ্যটিকে একাধিক ক্লিনিকাল পরিভাষা কোডিং সিস্টেমে প্রমিত করেছে, যেমন NDC, RxNorm, এবং SNOMED৷ আমরা এফএইচআইআর মেডিসিন স্টেটমেন্ট রিসোর্সে প্রসঙ্গ এবং কোডগুলি সংগঠিত করেছি। রূপান্তরিত এফএইচআইআর সংস্থানগুলি কাঠামো, ডেটাটাইপ, কোড সেট, প্রদর্শনের নাম এবং আরও অনেক কিছু সহ এফএইচআইআর মানগুলির সাথে সম্মতি নিশ্চিত করতে অফিসিয়াল এফএইচআইআর যাচাইকারী (https://validator.fhir.org/) দ্বারা বৈধতা পেয়েছে। এই বৈধ ফলাফলগুলি সোনার মান রূপান্তর ফলাফল হিসাবে বিবেচিত হয়েছিল এবং এলএলএমগুলির বিরুদ্ধে পরীক্ষা করতে ব্যবহার করা যেতে পারে। ডেটা ব্যবহার সম্পর্কে কোনও নৈতিক উদ্বেগ নেই, কারণ MIMIC এবং n2c2 ডেটাসেট উভয়ই অনুমোদিত ব্যবহারকারীদের জন্য সর্বজনীনভাবে উপলব্ধ।
Large Language Model আমরা FHIR ফরম্যাট রূপান্তরের জন্য LLM হিসেবে OpenAI-এর GPT-4 মডেল ব্যবহার করেছি। আমরা এলএলএমকে ইনপুট ফ্রি টেক্সটকে ওষুধে রূপান্তর করতে নির্দেশ দেওয়ার জন্য পাঁচটি পৃথক প্রম্পট ব্যবহার করেছি (ঔষধের কোড, শক্তি এবং ফর্ম সহ), রুট, সময়সূচী, ডোজ, এবং, কারণ, যথাক্রমে। সমস্ত প্রম্পট নিম্নলিখিত কাঠামো সহ একটি টেমপ্লেট মেনে চলে: টাস্ক নির্দেশাবলী, .JSON ফর্ম্যাটে প্রত্যাশিত আউটপুট FHIR টেমপ্লেট, 4-5 রূপান্তর উদাহরণ, কোডগুলির একটি বিস্তৃত তালিকা যা থেকে মডেল নির্বাচন করতে পারে এবং তারপরে ইনপুট পাঠ্য৷ যেহেতু আমাদের পরীক্ষায় কোন ফাইনটিউনিং বা ডোমেন-নির্দিষ্ট অভিযোজন ছিল না, তাই আমরা প্রাথমিকভাবে LLM একটি ছোট উপসেট (N=100) তৈরি করেছি। তারপরে, আমরা এলএলএম-জেনারেটেড এফএইচআইআর আউটপুট এবং আমাদের মানব টীকাগুলির মধ্যে পার্থক্যগুলি ম্যানুয়ালি পর্যালোচনা করেছি। সাধারণ ভুলগুলি চিহ্নিত করা হয়েছিল এবং প্রম্পটগুলিকে পরিমার্জন করতে ব্যবহৃত হয়েছিল৷ এটা মনে রাখা গুরুত্বপূর্ণ যে আমাদের কাছে ওষুধের নামের জন্য NDC, RxNorm এবং SNOMED মেডিকেশন কোডের পুরো তালিকার পাশাপাশি SNOMED ফাইন্ডিং কোডের কারণের জন্য অ্যাক্সেস ছিল না। উপরন্তু, এমনকি যদি আমাদের কাছে এই ধরনের বিস্তৃত তালিকা থাকে, তবে তারা LLM-এর জন্য টোকেন সীমা অতিক্রম করত। এইভাবে, আমরা LLM-কে এই সত্তা কোডিং করার কাজ করিনি; পরিবর্তে, আমরা তাদের ইনপুট টেক্সটে উল্লিখিত প্রসঙ্গগুলি সনাক্ত করতে নির্দেশ দিয়েছি। অন্যান্য উপাদানের জন্য, যেমন ড্রাগের রুট এবং ফর্ম, শতকরা সংখ্যায়, আমরা এলএলএম-কে সরাসরি তাদের কোড করার অনুমতি দিয়েছি। এলএলএম-উত্পাদিত আউটপুট মূল্যায়ন করার সময়, আমাদের প্রাথমিক মানদণ্ডটি ছিল সঠিক মিল হার, যা কোড, কাঠামো এবং আরও অনেক কিছু সহ সমস্ত দিকগুলিতে মানব টীকাগুলির সাথে সুনির্দিষ্ট প্রান্তিককরণের প্রয়োজন। উপরন্তু, আমরা নির্দিষ্ট উপাদান ঘটনার জন্য নির্ভুলতা, প্রত্যাহার, এবং F1 স্কোর রিপোর্ট করেছি। MIMIC ডেটার জন্য দায়িত্বশীল ব্যবহারের নির্দেশিকাগুলির সাথে সামঞ্জস্য রেখে আমরা Azure OpenAI পরিষেবার মাধ্যমে GPT-4 APIগুলি অ্যাক্সেস করেছি৷ আমরা যে নির্দিষ্ট মডেলটি ব্যবহার করেছি সেটি হল 'gpt-4-32k' এর '2023-05-15' সংস্করণে। প্রতিটি পাঠ্য ইনপুট পৃথকভাবে একটি মেডিকেশন স্টেটমেন্ট সম্পদে রূপান্তরিত হয়েছিল। দক্ষতা অপ্টিমাইজ করার জন্য, আমরা একাধিক অ্যাসিঙ্ক্রোনাস API কল করেছি।

ফলাফল এবং আলোচনা
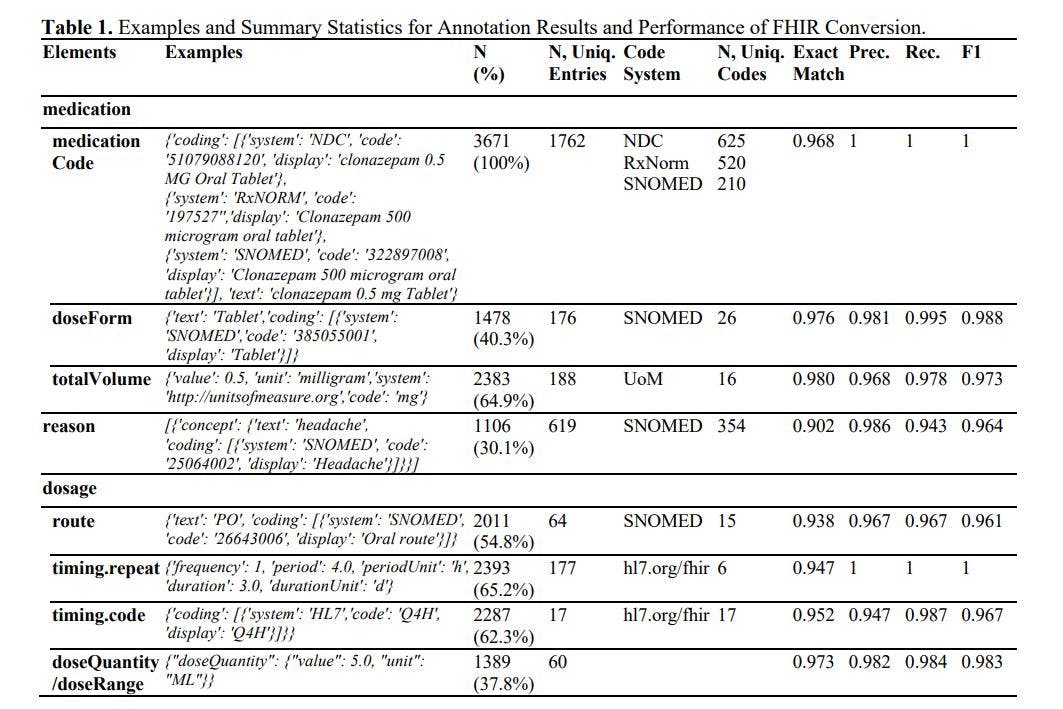
টীকা এবং এফএইচআইআর জেনারেশনের ফলাফলগুলি সারণী 1-এ উপস্থাপিত হয়েছে। সংক্ষেপে, আমরা 3,671টি ওষুধের সংস্থান টীকা করেছি, 625টিরও বেশি স্বতন্ত্র ওষুধকে কভার করে এবং 354টি কারণের সাথে যুক্ত। লার্জ ল্যাঙ্গুয়েজ মডেল (LLM) 90% এর বেশি একটি চিত্তাকর্ষক নির্ভুলতার হার এবং সমস্ত উপাদান জুড়ে 0.96 ছাড়িয়ে একটি F1 স্কোর অর্জন করেছে। পূর্ববর্তী গবেষণায়, F1 স্কোর timing.repeat-এ 0.750, timing.route-এ 0.878 এবং টাইমিং ডোজে 0.899-এ পৌঁছেছে। 1 LLM এই F1 স্কোরগুলিকে কমপক্ষে 8% উন্নত করেছে। এটি লক্ষণীয় যে পূর্ববর্তী গবেষণায় একটি ছোট ব্যক্তিগত ডেটাসেট ব্যবহার করা হয়েছিল, সঠিক ম্যাচ রেট, পরিভাষা কোডিং এড়িয়ে যাওয়া এবং ব্যাপক প্রশিক্ষণের প্রয়োজনের মতো কঠোরতম মূল্যায়ন মেট্রিকগুলি নিয়োগ করেনি। আরও তদন্তে, আমরা পরিভাষা কোডিংয়ের উচ্চ নির্ভুলতা দ্বারাও মুগ্ধ হয়েছিলাম (যা মূলত 100 টিরও বেশি ক্লাস সহ একটি শ্রেণীবিভাগের কাজ জড়িত), গাণিতিক রূপান্তর (যেমন, 10 দিনের সময়কাল অনুমান করে যখন ইনপুট 'TID' উল্লেখ করে, 30 টি ট্যাবলেট বিতরণ করে '), ফরম্যাট কনফার্মিটি (0.3% এর কম সম্ভাবনা যে ফলাফলগুলি .JSON ফর্ম্যাটে ব্যাখ্যা করা যায় না), এবং কার্ডিনালিটি (LLM 1:N এবং 1:1 সম্পর্ক উভয়ই পরিচালনা করতে পারে)।
আউটপুটের নির্ভুলতা ব্যবহৃত নির্দেশ প্রম্পটগুলির উপর অত্যন্ত নির্ভরশীল। আমাদের ব্যাপক ট্রায়াল এবং ত্রুটির উপর ভিত্তি করে, আমাদের নিম্নলিখিত সুপারিশগুলি রয়েছে: i) বিভিন্ন রূপান্তর উদাহরণ প্রদান করুন যা বিস্তৃত ভিন্ন ভিন্ন প্রান্তের ক্ষেত্রে অন্তর্ভুক্ত করে; ii) আউটপুট প্রত্যাশিত বিন্যাস এবং নিয়ম মেনে চলে তা নিশ্চিত করতে "অবশ্যই" এর মতো শক্তিশালী ভাষা ব্যবহার করুন; iii) একটি ছোট উপসেট থেকে ফলাফল পর্যালোচনা করে প্রম্পটগুলিকে ক্রমাগত আপডেট এবং পরিমার্জন করুন, যা সাধারণ ভুলগুলি সনাক্ত করতে এবং সামগ্রিক নির্ভুলতা বাড়াতে সাহায্য করতে পারে; iv) শব্দভান্ডারের বাইরের কোডিং সম্পর্কে সতর্ক থাকুন। এলএলএমগুলি এমন কোডগুলি উদ্ভাবন করে ব্যবহারকারীদের পূরণ করার চেষ্টা করতে পারে যা বিদ্যমান নেই যখন তারা একটি ঘনিষ্ঠ মিল খুঁজে পায় না।
উপসংহার
এই সমীক্ষায়, আমরা FHIR সংস্থানগুলিতে ফ্রি-টেক্সট ইনপুট রূপান্তর করে স্বাস্থ্য ডেটা আন্তঃকার্যযোগ্যতা বাড়ানোর জন্য LLM-এর ফাউন্ডেশন প্রদান করেছি। ভবিষ্যত অধ্যয়নগুলি প্রজন্মকে অতিরিক্ত এফএইচআইআর সংস্থানগুলিতে প্রসারিত করে এবং বিভিন্ন এলএলএম মডেলের কর্মক্ষমতা তুলনা করে এই সাফল্যগুলির উপর ভিত্তি করে গড়ে তোলার লক্ষ্য রাখবে।
রেফারেন্স
1. হং এন, ওয়েন এ, শেন এফ, সোহন এস, লিউ এস, লিউ এইচ, জিয়াং জি। একটি এফএইচআইআর-ভিত্তিক টাইপ সিস্টেম ব্যবহার করে কাঠামোগত এবং অসংগঠিত EHR ডেটা একীভূত করা: ওষুধের ডেটা সহ একটি কেস স্টাডি। AMIA সামিট অন ট্রান্সলেশনাল সায়েন্স প্রসিডিংস। 2018;2018:74।
2. হং এন, ওয়েন এ, শেন এফ, সোহন এস, ওয়াং সি, লিউ এইচ, জিয়াং জি। অসংগঠিত এবং কাঠামোগত ইলেকট্রনিক স্বাস্থ্য রেকর্ড ডেটা মানককরণ এবং একীভূত করার জন্য একটি মাপযোগ্য FHIR-ভিত্তিক ক্লিনিকাল ডেটা স্বাভাবিককরণ পাইপলাইন তৈরি করা। জামিয়া খোলা। 2019 ডিসেম্বর;2(4):570-9।
3. জনসন AE, পোলার্ড TJ, Shen L, Lehman LW, Feng M, Ghassemi M, Moody B, Szolovits P, Anthony Celi L, Mark RG। MIMIC-III, একটি অবাধে অ্যাক্সেসযোগ্য ক্রিটিক্যাল কেয়ার ডাটাবেস। বৈজ্ঞানিক তথ্য। 2016 মে 24;3(1):1-9।
4. Henry S, Buchan K, Filannino M, Stubbs A, Uzuner O. 2018 n2c2 প্রতিকূল ওষুধের ঘটনা এবং ইলেকট্রনিক স্বাস্থ্য রেকর্ডে ওষুধ নিষ্কাশনের উপর কাজ ভাগ করে নিয়েছে। আমেরিকান মেডিকেল ইনফরমেটিক্স অ্যাসোসিয়েশনের জার্নাল। 2020 জানুয়ারী;27(1):3-12।
এই কাগজটি CC 4.0 লাইসেন্সের অধীনে arxiv-এ উপলব্ধ।








