






















Autoren:
(1) Yikuan Li, MS, Northwestern University Feinberg School of Medicine & Siemens Medical Solutions;
(2) Hanyin Wang, BMed, Northwestern University Feinberg School of Medicine;
(3) Halid Z. Yerebakan, PhD, Siemens Medical Solutions;
(4) Yoshihisa Shinagawa, PhD, Siemens Medical Solutions;
(5) Yuan Luo, PhD, FAMIA, Northwestern University Feinberg School of Medicine.
Linktabelle
Einführung
Die Integration und der Austausch von Gesundheitsdaten über verschiedene Plattformen und Systeme hinweg bleiben aufgrund des Fehlens standardisierter Formate und eines gemeinsamen semantischen Verständnisses eine Herausforderung. Diese Herausforderung wird noch größer, wenn kritische Gesundheitsinformationen in unstrukturierte Daten statt in gut organisierte strukturierte Formate eingebettet sind. Die Standardisierung unstrukturierter Gesundheitsdaten, wie z. B. klinischer Notizen, in FHIR-Ressourcen kann Mehrdeutigkeiten zwischen verschiedenen Gesundheitsdienstleistern verringern und somit die Interoperabilität verbessern. Dies ist jedoch keineswegs eine leichte Aufgabe. Frühere Studien 1,2 haben versucht, klinische Notizen mithilfe einer Kombination aus natürlicher Sprachverarbeitung und maschinellem Lernen in FHIR-Ressourcen umzuwandeln. Dies geschah durch mehrstufige Prozesse, die die Erkennung klinischer benannter Entitäten, Terminologiecodierung, mathematische Berechnungen, strukturelle Formatierung und menschliche Kalibrierungen umfassten. Diese Ansätze erfordern jedoch zusätzlichen menschlichen Aufwand, um die Ergebnisse mehrerer Tools zu konsolidieren, und haben nur mäßige Leistungen erzielt, wobei die F1-Werte in verschiedenen Elementen zwischen 0,7 und 0,9 lagen. Zu diesem Zweck beabsichtigen wir, Large Language Models (LLMs) zu nutzen, um FHIR-formatierte Ressourcen direkt aus Freitexteingaben zu generieren. Durch die Nutzung von LLMs sollen die bislang mehrstufigen Prozesse vereinfacht, die Effizienz und Genauigkeit der automatischen Generierung von FHIR-Ressourcen verbessert und letztlich die Interoperabilität der Gesundheitsdaten verbessert werden.
Methoden
Datenannotation Nach unserem besten Wissen gibt es im FHIR-Standard keinen weitgehend öffentlich verfügbaren Datensatz, der aus Kontextdaten generiert wird. Daher haben wir uns entschieden, einen Datensatz zu annotieren, der sowohl Freitexteingaben als auch strukturierte Ausgaben in FHIR-Formaten enthält. Die Freitexteingaben wurden aus den Entlassungszusammenfassungen des MIMICIII-Datensatzes abgeleitet. 3 Dank der n2c2-Medikationsextraktions-Challenge 2018 4, bei der es im Wesentlichen um Aufgaben zur Erkennung benannter Entitäten geht, konnten Elemente in Medikamentenanweisungen identifiziert werden. Unsere Annotationen bauten auf diesen n2c2-Annotationen auf und standardisierten den Freitext in mehrere Kodierungssysteme der klinischen Terminologie wie NDC, RxNorm und SNOMED. Wir organisierten die Kontexte und Codes in FHIR-Medikationsanweisungsressourcen. Die konvertierten FHIR-Ressourcen wurden vom offiziellen FHIR-Validator (https://validator.fhir.org/) validiert, um die Einhaltung der FHIR-Standards, einschließlich Struktur, Datentyp, Codesätze, Anzeigenamen und mehr, sicherzustellen. Diese validierten Ergebnisse wurden als Goldstandard-Transformationsergebnisse betrachtet und konnten zum Testen gegen die LLMs verwendet werden. Es bestehen keine ethischen Bedenken hinsichtlich der Datenverwendung, da sowohl die MIMIC- als auch die n2c2-Datensätze autorisierten Benutzern öffentlich zugänglich sind.
Großes Sprachmodell Wir haben das GPT-4-Modell von OpenAI als LLM für die FHIR-Formattransformation verwendet. Wir haben fünf separate Eingabeaufforderungen verwendet, um das LLM anzuweisen, eingegebenen Freitext in Medikamente (einschließlich Medikamentencode, Stärke und Form), Route, Zeitplan, Dosierung und Grund umzuwandeln. Alle Eingabeaufforderungen folgten einer Vorlage mit der folgenden Struktur: Aufgabenanweisungen, erwartete Ausgabe-FHIR-Vorlagen im JSON-Format, 4-5 Konvertierungsbeispiele, eine umfassende Liste von Codes, aus denen das Modell Auswahlen treffen kann, und dann der Eingabetext. Da es in unseren Experimenten keine Feinabstimmung oder domänenspezifische Anpassung gab, ließen wir das LLM zunächst eine kleine Teilmenge (N = 100) generieren. Dann überprüften wir manuell die Diskrepanzen zwischen der vom LLM generierten FHIR-Ausgabe und unseren menschlichen Anmerkungen. Häufige Fehler wurden identifiziert und verwendet, um die Eingabeaufforderungen zu verfeinern. Es ist wichtig anzumerken, dass wir keinen Zugriff auf die vollständigen Listen der NDC-, RxNorm- und SNOMED-Medikamentencodes für Arzneimittelnamen sowie auf SNOMED-Suchcodes für Gründe hatten. Selbst wenn wir solch umfassende Listen gehabt hätten, hätten sie die Token-Grenzen für LLMs überschritten. Daher haben wir LLMs nicht mit der Kodierung dieser Entitäten beauftragt, sondern sie angewiesen, die im Eingabetext erwähnten Kontexte zu identifizieren. Andere Elemente, z. B. Arzneimittelwege und -formulare, die es in die Hunderte gibt, haben wir LLMs erlaubt, sie direkt zu kodieren. Bei der Auswertung der von LLMs generierten Ausgabe war unser Hauptkriterium die exakte Übereinstimmungsrate, die eine genaue Übereinstimmung mit menschlichen Anmerkungen in allen Aspekten erfordert, einschließlich Codes, Strukturen und mehr. Darüber hinaus haben wir Präzision, Rückruf und F1-Werte für bestimmte Elementvorkommen gemeldet. Wir haben über den Azure OpenAI-Dienst auf die GPT-4-APIs zugegriffen und uns an die Richtlinien zur verantwortungsvollen Nutzung von MIMIC-Daten gehalten. Das spezifische Modell, das wir verwendet haben, war „gpt-4-32k“ in seiner Version „2023-05-15“. Jede Texteingabe wurde einzeln in eine MedicationStatement-Ressource umgewandelt. Um die Effizienz zu optimieren, haben wir mehrere asynchrone API-Aufrufe durchgeführt.

Ergebnisse und Diskussionen
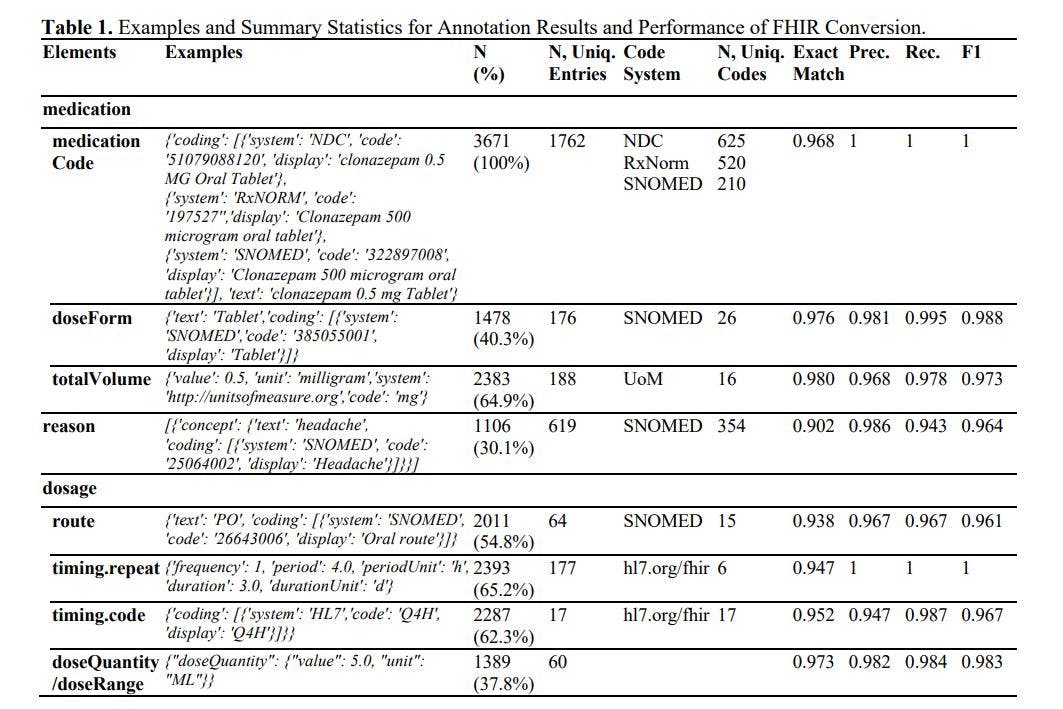
Die Ergebnisse der Annotation und FHIR-Generierung sind in Tabelle 1 dargestellt. Zusammenfassend haben wir 3.671 Medikamentenressourcen annotiert, die über 625 verschiedene Medikamente abdecken und mit 354 Gründen verknüpft sind. Das Large Language Model (LLM) erreichte eine beeindruckende Genauigkeitsrate von über 90 % und einen F1-Score von über 0,96 über alle Elemente hinweg. In früheren Studien erreichten die F1-Scores 0,750 bei „timing.repeat“, 0,878 bei „timing.route“ und 0,899 bei „timing dosage“. 1 Das LLM verbesserte diese F1-Scores um mindestens 8 %. Es ist erwähnenswert, dass die früheren Studien einen kleineren privaten Datensatz verwendeten, nicht die strengsten Bewertungsmetriken wie die exakte Übereinstimmungsrate oder die übersprungene Terminologiecodierung verwendeten und umfangreiches Training erforderten. Bei weiterer Untersuchung waren wir auch von der hohen Genauigkeit bei der Terminologiecodierung (bei der es sich im Wesentlichen um eine Klassifizierungsaufgabe mit mehr als 100 Klassen handelt), der mathematischen Konvertierung (z. B. Ableitung einer Dauer von 10 Tagen, wenn in der Eingabe „TID, 30 Tabletten ausgeben“ erwähnt wird), der Formatkonformität (mit einer Wahrscheinlichkeit von weniger als 0,3 %, dass die Ergebnisse nicht im JSON-Format interpretiert werden können) und der Kardinalität (das LLM kann sowohl 1:N- als auch 1:1-Beziehungen verarbeiten) beeindruckt.
Die Genauigkeit der Ausgabe hängt stark von den verwendeten Anweisungsaufforderungen ab. Basierend auf unseren umfangreichen Versuchen und Fehlern haben wir folgende Empfehlungen: i) Bieten Sie verschiedene Konvertierungsbeispiele an, die eine breite Palette heterogener Randfälle abdecken; ii) Verwenden Sie starke Ausdrücke wie „MUSS“, um sicherzustellen, dass die Ausgabe den erwarteten Formaten und Regeln entspricht; iii) Aktualisieren und verfeinern Sie die Aufforderungen kontinuierlich, indem Sie die Ergebnisse einer kleinen Teilmenge überprüfen, um häufige Fehler zu identifizieren und die Gesamtgenauigkeit zu verbessern; iv) Seien Sie vorsichtig bei Codierungen, die nicht zum Vokabular gehören. LLMs versuchen möglicherweise, den Benutzern entgegenzukommen, indem sie Codes erfinden, die nicht existieren, wenn sie keine nahe Entsprechung finden können.
Abschluss
In dieser Studie haben wir die Grundlagen für die Nutzung von LLMs zur Verbesserung der Interoperabilität von Gesundheitsdaten durch die Umwandlung von Freitexteingaben in die FHIR-Ressourcen geschaffen. Zukünftige Studien werden auf diesen Erfolgen aufbauen, indem die Generierung auf zusätzliche FHIR-Ressourcen ausgeweitet und die Leistung verschiedener LLM-Modelle verglichen wird.
Referenz
1. Hong N, Wen A, Shen F, Sohn S, Liu S, Liu H, Jiang G. Integration strukturierter und unstrukturierter EHR-Daten mithilfe eines FHIR-basierten Typsystems: eine Fallstudie mit Medikamentendaten. AMIA Summits on Translational Science Proceedings. 2018;2018:74.
2. Hong N, Wen A, Shen F, Sohn S, Wang C, Liu H, Jiang G. Entwicklung einer skalierbaren FHIR-basierten Normalisierungspipeline für klinische Daten zur Standardisierung und Integration unstrukturierter und strukturierter elektronischer Gesundheitsdaten. JAMIA open. 2019 Dez;2(4):570-9.
3. Johnson AE, Pollard TJ, Shen L, Lehman LW, Feng M, Ghassemi M, Moody B, Szolovits P, Anthony Celi L, Mark RG. MIMIC-III, eine frei zugängliche Datenbank für die Intensivpflege. Wissenschaftliche Daten. 2016 Mai 24;3(1):1-9.
4. Henry S, Buchan K, Filannino M, Stubbs A, Uzuner O. 2018 n2c2 gemeinsame Aufgabe zu unerwünschten Arzneimittelwirkungen und Medikamentenextraktion in elektronischen Gesundheitsakten. Journal of the American Medical Informatics Association. 2020 Jan;27(1):3-12.
Dieses Dokument ist auf Arxiv unter der CC 4.0-Lizenz verfügbar.








