






















Autores:
(1) Yikuan Li, MS, Faculdade de Medicina Feinberg da Northwestern University e Siemens Medical Solutions;
(2) Hanyin Wang, BMed, Faculdade de Medicina Feinberg da Universidade Northwestern;
(3) Halid Z. Yerebakan, PhD, Siemens Medical Solutions;
(4) Yoshihisa Shinagawa, PhD, Siemens Medical Solutions;
(5) Yuan Luo, PhD, FAMIA, Faculdade de Medicina Feinberg da Northwestern University.
Tabela de links
Introdução
A integração e o intercâmbio de dados de saúde através de diversas plataformas e sistemas continuam a ser um desafio devido à ausência de formatos padronizados e de uma compreensão semântica partilhada. Este desafio torna-se mais significativo quando a informação crítica sobre saúde é incorporada em dados não estruturados, em vez de formatos estruturados bem organizados. A padronização de dados de saúde não estruturados, tais como notas clínicas, em recursos FHIR pode aliviar a ambiguidade entre diferentes prestadores de cuidados de saúde e, portanto, melhorar a interoperabilidade. Contudo, não é de forma alguma uma tarefa fácil. Estudos anteriores 1,2 tentaram transformar notas clínicas em recursos FHIR usando uma combinação de processamento de linguagem natural e ferramentas de aprendizado de máquina por meio de processos de várias etapas envolvendo reconhecimento de entidade clínica nomeada, codificação de terminologia, cálculos matemáticos, formatação estrutural e calibrações humanas. No entanto, estas abordagens requerem esforço humano adicional para consolidar os resultados de múltiplas ferramentas e alcançaram apenas desempenhos moderados, com pontuações F1 variando entre 0,7 e 0,9 em diferentes elementos. Para este fim, pretendemos aproveitar Large Language Models (LLMs) para gerar diretamente recursos formatados em FHIR a partir de entrada de texto livre. Espera-se que a utilização de LLMs simplifique os processos anteriormente de várias etapas, melhore a eficiência e a precisão da geração automática de recursos FHIR e, em última análise, melhore a interoperabilidade dos dados de saúde.
Métodos
Anotação de dados Até onde sabemos, não existe nenhum conjunto de dados amplamente disponível publicamente no padrão FHIR que seja gerado a partir de dados contextuais. Portanto, optamos por anotar um conjunto de dados contendo entrada de texto livre e saída estruturada em formatos FHIR. A entrada de texto livre foi derivada dos resumos de alta da base de dados MIMICIII. 3 Graças ao desafio de extração de medicamentos n2c2 de 2018 4 , que envolve essencialmente tarefas de reconhecimento de entidades nomeadas, foram identificados elementos nas declarações de medicamentos. Nossas anotações foram baseadas nessas anotações n2c2 e padronizaram o texto livre em vários sistemas de codificação de terminologia clínica, como NDC, RxNorm e SNOMED. Organizamos os contextos e códigos em recursos de declaração de medicação FHIR. Os recursos FHIR convertidos foram validados pelo validador oficial do FHIR (https://validator.fhir.org/) para garantir a conformidade com os padrões FHIR, incluindo estrutura, tipo de dados, conjuntos de códigos, nomes de exibição e muito mais. Esses resultados validados foram considerados os resultados de transformação padrão ouro e poderiam ser usados para testar os LLMs. Não existem preocupações éticas em relação ao uso de dados, uma vez que os conjuntos de dados MIMIC e n2c2 estão disponíveis publicamente para usuários autorizados.
Modelo de linguagem grande Usamos o modelo GPT-4 da OpenAI como LLM para transformação do formato FHIR. Usamos cinco prompts separados para instruir o LLM a transformar o texto livre de entrada em medicamento (incluindo medicaçãoCódigo, dosagem e forma), via, horário, dosagem e motivo, respectivamente. Todos os prompts aderiram a um modelo com a seguinte estrutura: instruções de tarefa, modelos FHIR de saída esperados em formato .JSON, 4-5 exemplos de conversão, uma lista abrangente de códigos a partir dos quais o modelo pode fazer seleções e, em seguida, o texto de entrada. Como não houve ajuste fino ou adaptação específica de domínio em nossos experimentos, inicialmente fizemos com que o LLM gerasse um pequeno subconjunto (N = 100). Em seguida, revisamos manualmente as discrepâncias entre a saída FHIR gerada pelo LLM e nossas anotações humanas. Erros comuns foram identificados e usados para refinar as instruções. É importante observar que não tivemos acesso a todas as listas de códigos NDC, RxNorm e SNOMED Medication para nomes de medicamentos, bem como aos códigos SNOMED Finding por motivos. Além disso, mesmo que tivéssemos listas tão abrangentes, elas teriam excedido os limites de tokens para LLMs. Assim, não incumbimos os LLMs de codificar essas entidades; em vez disso, instruímo-los a identificar os contextos mencionados no texto de entrada. Para outros elementos, por exemplo, rotas e formas de medicamentos, numerados na casa das centenas, permitimos que os LLMs os codificassem diretamente. Ao avaliar o resultado gerado pelo LLM, nosso principal critério foi a taxa de correspondência exata, que exige alinhamento preciso com anotações humanas em todos os aspectos, incluindo códigos, estruturas e muito mais. Além disso, relatamos pontuações de precisão, recall e F1 para ocorrências de elementos específicos. Acessamos as APIs GPT-4 por meio do serviço Azure OpenAI, alinhando-nos com as diretrizes de uso responsável de dados MIMIC. O modelo específico que usamos foi ‘gpt-4-32k’ em sua versão ‘2023-05-15’. Cada entrada de texto foi transformada individualmente em um recurso MedicationStatement. Para otimizar a eficiência, fizemos diversas chamadas de API assíncronas.

Resultados e discussões
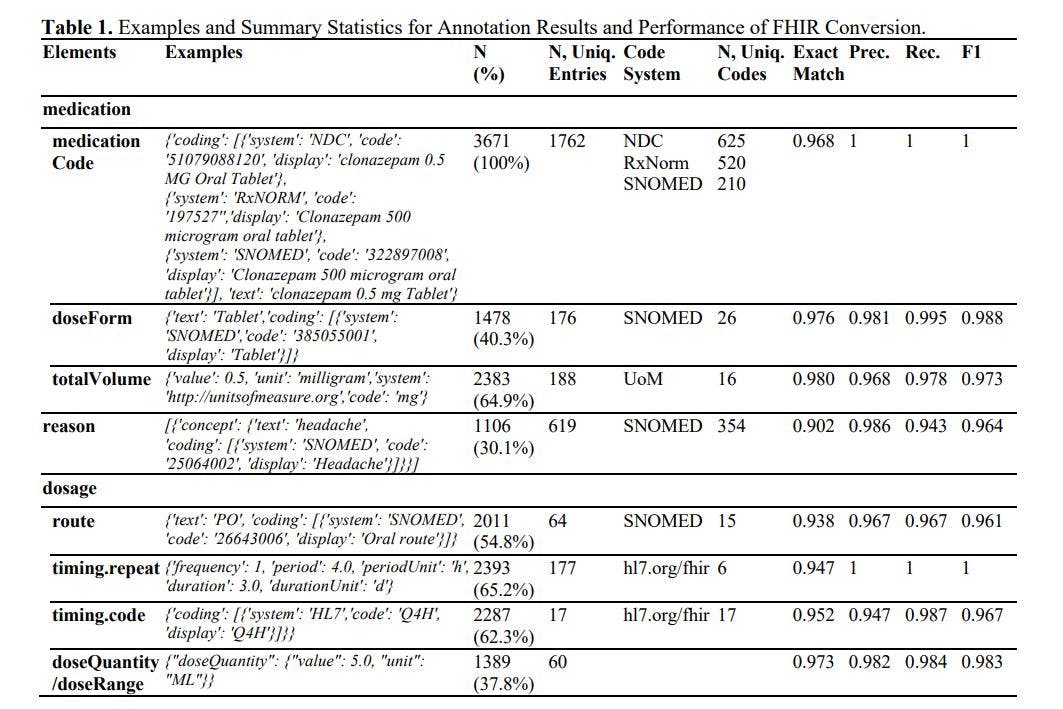
Os resultados da anotação e geração do FHIR são apresentados na Tabela 1. Em resumo, anotamos 3.671 recursos de medicamentos, abrangendo mais de 625 medicamentos distintos e associados a 354 motivos. O Large Language Model (LLM) alcançou uma taxa de precisão impressionante de mais de 90% e uma pontuação F1 superior a 0,96 em todos os elementos. Em estudos anteriores, as pontuações F1 atingiram 0,750 em tempo.repetição, 0,878 em tempo.rota e 0,899 em tempo de dosagem. 1 O LLM melhorou essas pontuações na F1 em pelo menos 8%. Vale a pena notar que os estudos anteriores usaram um conjunto de dados privado menor, não empregaram as métricas de avaliação mais rigorosas, como taxa de correspondência exata, ignoraram a codificação terminológica e exigiram treinamento extensivo. Numa investigação mais aprofundada, ficámos também impressionados com a elevada precisão na codificação terminológica (que envolve essencialmente uma tarefa de classificação com mais de 100 classes), conversão matemática (por exemplo, inferir uma duração de 10 dias quando a entrada menciona 'TID, dispensar 30 comprimidos '), conformidade de formato (com menos de 0,3% de chance de que os resultados não possam ser interpretados no formato .JSON) e cardinalidade (o LLM pode lidar com relacionamentos 1:N e 1:1).
A precisão da saída é altamente dependente dos prompts de instrução usados. Com base em nossas extensas tentativas e erros, temos as seguintes recomendações: i) fornecer diversos exemplos de conversão que abrangem uma ampla gama de casos extremos heterogêneos; ii) usar linguagem forte, como “MUST”, para garantir que o resultado esteja de acordo com os formatos e resultados esperados; iii) atualizar e refinar continuamente as instruções, analisando os resultados de um pequeno subconjunto, o que pode ajudar a identificar erros comuns e melhorar a precisão geral; iv) seja cauteloso com codificações fora do vocabulário. Os LLMs podem tentar atender aos usuários inventando códigos que não existem quando não conseguem encontrar uma correspondência aproximada.
Conclusão
Neste estudo, fornecemos as bases para aproveitar os LLMs para melhorar a interoperabilidade dos dados de saúde, transformando a entrada de texto livre nos recursos FHIR. Estudos futuros terão como objetivo aproveitar esses sucessos, estendendo a geração a recursos FHIR adicionais e comparando o desempenho de vários modelos LLM.
Referência
1. Hong N, Wen A, Shen F, Sohn S, Liu S, Liu H, Jiang G. Integração de dados EHR estruturados e não estruturados usando um sistema de tipo baseado em FHIR: um estudo de caso com dados de medicação. Cúpulas AMIA sobre Procedimentos Científicos Translacionais. 2018;2018:74.
2. Hong N, Wen A, Shen F, Sohn S, Wang C, Liu H, Jiang G. Desenvolvendo um pipeline escalável de normalização de dados clínicos baseado em FHIR para padronizar e integrar dados de registros eletrônicos de saúde estruturados e não estruturados. JAMIA aberta. Dez de 2019;2(4):570-9.
3. Johnson AE, Pollard TJ, Shen L, Lehman LW, Feng M, Ghassemi M, Moody B, Szolovits P, Anthony Celi L, Mark RG. MIMIC-III, um banco de dados de cuidados intensivos de acesso gratuito. Dados científicos. 24 de maio de 2016;3(1):1-9.
4. Henry S, Buchan K, Filannino M, Stubbs A, Uzuner O. 2018 n2c2 tarefa compartilhada sobre eventos adversos a medicamentos e extração de medicamentos em registros eletrônicos de saúde. Jornal da Associação Americana de Informática Médica. 2020 janeiro;27(1):3-12.
Este artigo está disponível no arxiv sob licença CC 4.0.








